为啥选它:
那要先知道什么是麦克风阵列(Microphone array),学术上有个概念是“传声器阵列”,主要由一定数目的声学传感器组成,用来对声场的空间特性进行采样并处理的系统。
通俗的讲,就是麦克风阵列是由多个单麦克风按一定顺序排列的。你可以理解为一堆麦克风。我们常见的话筒(比如苹果手机话筒就是单麦克风的)。麦克风阵列一般来说有线形、环形和球形的,严谨的应该说成一字、十字、平面、螺旋、球形及无规则阵列等。至于麦克风阵列的阵元数量,也就是麦克风数量,可以从2个到上千个不等。它们通过特定的排列(阵法),可以对声音接收有更好的效果。
语音交互应用最为普遍的就是以Siri为代表的智能手机,这个场景一般都是采用单麦克风系统。单麦克风系统可以在低噪声、无混响、距离声源很近的情况下获得符合语音识别需求的声音信号。但是,若声源距离麦克风距离较远,并且真实环境存在大量的噪声、多径反射和混响,导致拾取信号的质量下降,这会严重影响语音识别率。而且,单麦克风接收的信号,是由多个声源和环境噪声叠加的,很难实现各个声源的分离。
麦克风阵列由一组按一定几何结构(常用线形、环形)摆放的麦克风组成,对采集的不同空间方向的声音信号进行空时处理,实现噪声抑制、混响去除、人声干扰抑制、声源测向、声源跟踪、阵列增益等功能,进而提高语音信号处理质量,以提高真实环境下的语音识别率。
亚马逊Echo一样直接选用4麦以上的麦克风阵列。机器人一般4个麦克风就够了,音箱建议还是选用6个以上麦克风,至于汽车领域,最好是选用其他结构形式的麦克风阵列,比如分布式阵列。
麦克风越多成本越高,所以我们选择4阵列的。
基于Raspberry Pi的ReSpeaker 4-Mic阵列是一款适用于AI和语音应用的Raspberry Pi的四通道麦克风扩展板。 这意味着可以借助它构建一个集成Amazon Alexa语音服务,Google助手等,功能更强大,更灵活的语音产品。
区别于 ReSpeaker 2-Mics Pi HAT, 该板是基于AC108开发的,这是一款高度集成四通道ADC,具有用于高清晰度语音捕获,I2S / TDM输出,拾取3米半径的声音的语音设备。 此外,这款4-Mics版本提供了超酷LED环,其中包含12个APA102可编程LED。 就像Amazon Echo或 Google assist一样, 使用4个麦克风和LED环,Raspberry Pi具有VAD(语音活动检测),DOA(到达方向),KWS(关键字搜索),并通过LED环显示方向灯功能。
硬件软件准备:
麦克风的淘宝链接(https://item.taobao.com/item.htm?spm=a1z10.1-c.w13838425-11172345252.1.542035bczDBegW&id=557884254210)我买的这家的。
我的树莓派是Pi 4B,这个麦克风阵列兼容(Raspberry Pi Zero和Zero W,Raspberry Pi B +,Raspberry Pi 2 B和Raspberry Pi 3 B,Raspberry Pi 4 B,Raspberry Pi 3 B +)所以说用惯了3B的小伙伴也可以跟我一起做。
树莓派系统用的最新的系统:

树莓派系统安装步骤请参考(https://blog.csdn.net/Smile_h_ahaha/article/details/84997205)
安装引文与前言:
我会把最好的安装方法用手把手小白级别记录在下面。你要跟我一步一步来,肯定没毛病。
我把安装中遇到的坑还有解决方法记录在第七步中了。纪念一下我花了N天的安装心路历程。感兴趣的可以看一下。
现在是2020.09.24日,不排除在这个时间之后树莓派的源们又不支持的可能性,因为技术在刷新,兼容不并行。
我树莓派的SD卡状态为刚重装了系统(2020.02.13版本),并按照以下链接的方法设置的树莓派。
树莓派重装系统(https://blog.csdn.net/Smile_h_ahaha/article/details/84997205)
树莓派Putty与远程VNC(https://blog.csdn.net/Smile_h_ahaha/article/details/84997214)这里可以先不换源,无所谓,我后面都会说,你换了也没事。
如果在未来的时候安装有问题,欢迎在评论区给我留言。
下面是我的详细安装方法
第一步,换源的必要性。
换源命令:
sudo nano /etc/apt/sources.list用#注释第一句。然后在最下面复制下面句子:(换成清华源)
deb http://mirrors.tuna.tsinghua.edu.cn/raspbian/raspbian/ buster main non-free contrib
deb-src http://mirrors.tuna.tsinghua.edu.cn/raspbian/raspbian/ buster main non-free contrib继续换源:(这一步别忘啊。。。忘了的话,装pyaudio的时候,会出问题,别问我是怎么知道了,重装系统30次的男人)
sudo nano /etc/apt/sources.list.d/raspi.list操作同上并替换为:
deb http://mirror.tuna.tsinghua.edu.cn/raspberrypi/ buster main ui
deb-src http://mirror.tuna.tsinghua.edu.cn/raspberrypi/ buster main ui注意清华源里面的buster对应的是debian10, 在2019.6月的版本以后都是debian10了。以前的版本是debian9(对应的是stretch),你的系统若是以前的版本,注意这个后缀别写错了。建议你下个新版本用,这个没什么兼容问题。兼容问题主要是麦克风支持python2,不支持3的问题。
换源直接决定了安装Seeed话筒驱动的成功与否,你用树莓派自带内核的话(此时不换清华源或阿里源),有很大概率能成功的安装话筒驱动(树莓派版本2020-02-13-raspbian-buster-full.img(比它还新的版本更没有问题了))。但是在安装成功后,你不换清华源的话,就会安装失败“Voice engine”。所以换源是必要的。
在引文部分的攻略中(包括官网)都有个错误:声卡安装没有强调compat kernel。因为2019.06.22版本以后树莓派内核移除了kernel(内核认为对于全局来说it is not necessary 于是移除了,WTF???)。
下图为树莓派安装失败的提示:它让你在“sudo ./install.sh”命令后加入 “ --compat-kernel”

所以说直接按照下图所示代码,在cd /home/pi 中逐一键入:
sudo apt-get update #源更新
sudo apt-get upgrade #已安装软件更新
git clone https://github.com/respeaker/seeed-voicecard.git #下载声卡驱动包
cd seeed-voicecard #新建声卡驱动文件夹
sudo ./install.sh --compat-kernel #安装声卡驱动
reboot #重启
然后,成功了。重启

安装pyaudio
sudo apt-get install libportaudio0 libportaudio2 libportaudiocpp0 portaudio19-dev
sudo apt-get install python-pyaudio python3-pyaudio
pip3 install pyaudio第二步,检查声卡是否安装成功。
输入命令:
cd
cd seeed-voicecard
arecord -L然后出来下图一堆,说明话筒可以用了。

输入命令
alsamixer可以调节话筒音量。

用F6选择seeed-4mic的声卡设备,调节音量。
安装个能录音的软件:
sudo apt update
sudo apt install audacity
audacity // 运行 audacity打开软件后,把mic设置为4,这样你就有四个声道一起录音了。

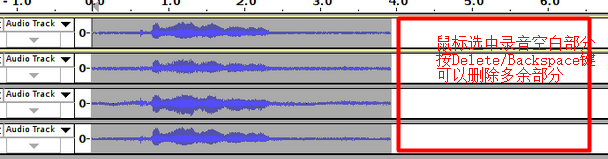
生成.wav文件,保存在树莓派当地。可以用它作为你的应答词。
输入sudo raspi-config打开控制面板,
把5.Interfacing Options中的SPI 和 SSH 和I2C 都使能Enable
把7.Advanced Options 中的A4 Audio 选择你自己喜欢的音响输出端口。第一个是HDMI音频输出,第二个是3.5mm直径的耳机孔。
如果你想用HDMI连接的显示屏发声就选第一个,如果是用耳机线连接的外置音响,就选第二个Head...(3.5mm)。
以上问题不大,你也可以手动配置音频的声卡card号。
输入以下,查声卡号。
arecord -l声卡是输入(Input)就是你的录音话筒。只要你用的是4-mic的那个Seeed话筒,那我们就是一样的。把这个号记住。

这个号,在程序中,表示为“hw:2,0”。当然如果你用的别的USB麦克风,你不用装Seeed驱动,直接也是记住声卡号就行了。普通的单声道麦克风不如四阵列清晰。
输入以下,查音响号(Output):
aplay -l 
这个号,在程序中,表示为“hw:0,0”。
输入以下代码,用nano重新手动设置“默认声卡程序”中的变量:
sudo nano /home/pi/.asoundrc下图为打开后的文件
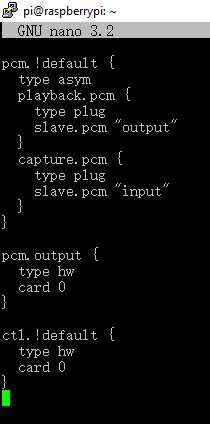
按照下图所示改你自己的代码。下图为我的改动。你对照上下文改。我的是:
Input改为hw:2,0
Output改成hw:0,0
pcm.output 那的 card 0 输出音频号为card 0
ct1.default那是 card 0 默认优先选择HDMI显示屏作为输出音频
pcm.!default {
type asym
playback.pcm {
type plug
slave.pcm "hw:0,0"
}
capture.pcm {
type plug
slave.pcm "hw:2,0"
}
}
pcm.output {
type hw
card 0
}
ctl.!default {
type hw
card 0
}
然后Ctrl+X 然后Y然后Enter退出。
输入以下代码,在home/pi下创建一个叫demo.wav的录音文件,你说3秒话,它会录音。
arecord -d 3 demo.wav输入以下代码,播放刚才录的音:
aplay demo.wav然后你就听到很清晰的声音了。你可以用它录回答的音频。
以上是安装Seeed驱动的教程,就BB到这了。下面将介绍Snowboy关键词识别的项目安装步骤。
(已规避所有坑,本博文更新时间2020年9月24日02:09:00am)
如果你的话筒是4-mics Pi HAT的,请直接跳到第四步跟着做,如果你的话筒是普通的,那就跟着第三步做。第三步与第四步安装流程不能重叠。第三步是我试了好几次,百分百兼容级别的安装教程。(因为我把我的备份都给你们了,肯定能成功)第四步比第三步多了点4-mics Pi HAT他们家的独家例程。区别不大。第5步包含了在线语音识别的安装与激活,第五步是兼容第四步的。
第三步,安装Snowboy引擎(仅能离线关键字语音识别)
输入命令,新建个叫snowboy的文件夹,并打开:
cd
mkdir snowboy
cd snowboy
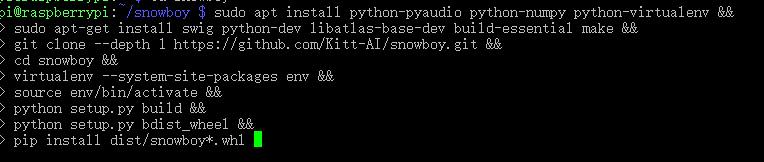
在上图所示的路径下,把以下代码一口气的复制粘贴到树莓派终端中(我在每行的命令后加了&&,它可以让每行命令挨个执行)
以下代码是让你安装 pyaudio, numpy and snowboy的,还要安装个virtual python environment.(Python的虚拟环境)。
sudo apt install python-pyaudio python-numpy python-virtualenv &&
sudo apt-get install swig python-dev libatlas-base-dev build-essential make &&
git clone --depth 1 https://github.com/Kitt-AI/snowboy.git &&
cd snowboy &&
virtualenv --system-site-packages env &&
source env/bin/activate &&
python setup.py build &&
python setup.py bdist_wheel &&
pip install dist/snowboy*.whl 如下图所示,粘贴后点击回车安装。
我解释一下每行代码啥意思吧,下面的代码不要安装了,你看看就好:
sudo apt install python-pyaudio python-numpy python-virtualenv
#安装python支持的pyaudio,numpy,virtual env虚拟机
sudo apt-get install swig python-dev libatlas-base-dev build-essential make
#安装python库文件到SWIG文件夹中,这是github上的更新与补充
git clone --depth 1 https://github.com/Kitt-AI/snowboy.git
#下载Snowboy引擎包
cd snowboy
#打开Snowboy文件夹
virtualenv --system-site-packages env
#安装python虚拟机
source env/bin/activate
#激活虚拟机,这是你以后,运行代码前必要的一步。
#输入命令deactivate可以退出虚拟机
python setup.py build
#编译python库
python setup.py bdist_wheel
#编译Snowboy的python库
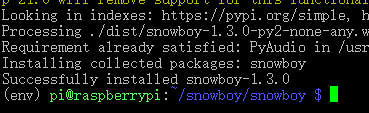
pip install dist/snowboy*.whl
#下载安装Snowboy的KWS关键词库当你看到下图,说明Snowboy工具包安装成功了
其实装到这里就以及可以使用Snowboy的关键字语音识别了。以上安装应该是肯定没有问题的。这个时候大家可以直接把我写好的NBoy的文件夹拷贝到home/pi中,然后
cd NBoy
python3 demo.py 你的关键字.pmdl你的关键字直接保存进Nboy中即可。在demo中添加你自己的功能,比如控制GPIO开个灯之类的。Nboy文件下载链接
(https://download.csdn.net/download/Smile_h_ahaha/12889142)
那,你现在应该是说出关键词之后听到Ding的声音了。成功的话点个赞再走吧O(∩_∩)O哈哈~
第四步,奥利给4-MICS家专属例程安装(上接第二步)实现在线语音识别
step 1. 配置和安装相关依赖
git clone https://github.com/respeaker/4mics_hat.git
cd ~/4mics_hat
sudo apt install libatlas-base-dev # 安装 snowboy dependencies
sudo apt install python-pyaudio # 安装pyaudio音频处理包
pip install ./snowboy*.whl # 安装 snowboy for KWS
pip install ./webrtc*.whl # 安装 webrtc for DoA
cd ~/
git clone https://github.com/voice-engine/voice-engine #write by seeed
cd voice-engine/
sudo python setup.py bdist_wheel
pip install dist/*.whl
cd ~/
git clone https://github.com/respeaker/avs
cd avs # install Requirements
sudo python setup.py install
pip install avs==0.5.3
sudo apt install libgstreamer1.0-0
sudo apt install gstreamer1.0-plugins-bad gstreamer1.0-plugins-ugly
sudo apt install gstreamer1.0-libav gstreamer1.0-doc gstreamer1.0-tool
sudo apt install gstreamer1.0-plugins-good
sudo apt install python-gi gir1.2-gstreamer-1.0
pip install tornado==5.1.1
sudo apt install mpg123step 2. 取得授权
在终端运行 alexa-auth ,然后登陆获取alexa的授权, 或者运行 dueros-auth 获取百度的授权。 授权的文件保存在/home/pi/你的安装路径/avs/.avs.json。

如果我们在 alexa-auth 和 dueros-auth之间切换, 请先删除 /home/pi/你的安装路径/.avs.json 。 这个是隐藏文件,请用 ls -la 显示文件。
step 3. 让我们High起来!
cd ~/4mics_hat
sudo nano ns_kws_doa_alexa_with_light.py #编辑文件改配置按照下面的信息更新下面代码的设置:(如果你的麦克风是4-mic HAT那就不用改以下配置,如果不是,我把要改的地方标出来了)
"""
Hands-free Voice Assistant with Snowboy and Alexa Voice Service.
Requirement:
sudo apt-get install python-numpy
pip install webrtc-audio-processing
pip install spidev
"""
import time
import logging
from voice_engine.source import Source
from voice_engine.channel_picker import ChannelPicker
from voice_engine.kws import KWS
from voice_engine.ns import NS
from voice_engine.doa_respeaker_4mic_array import DOA
from avs.alexa import Alexa
def main():
logging.basicConfig(level=logging.DEBUG)
src = Source(rate=16000, channels=1, device_name='plughw:1,0') #你是几声道的就把channels的值改成几
ch1 = ChannelPicker(channels=1, pick=1)
ns = NS(rate=16000, channels=1) #rate是采样率,这个值去查你话筒的芯片手册,给他匹配最合适的采样频率
kws = KWS(model='snowboy') #把这里的snowboy替换成你的关键词路径
#例如/home/pi/NBoy/DaBai.pmdl
doa = DOA(rate=16000)
alexa = Alexa()
def on_detected(keyword):
direction = doa.get_direction()
logging.info('detected {} at direction {}'.format(keyword, direction))
alexa.listen()
kws.on_detected = on_detected
src.link(ch1)
ch1.link(ns)
ns.link(kws)
kws.link(alexa)
src.link(doa)
src.recursive_start()
while True:
try:
time.sleep(1)
except KeyboardInterrupt:
break
src.recursive_stop()
if __name__ == '__main__':
main()假如需要使用mic-array作为音频输出口的话则如下图进行设置

运行PLAYER=mpg123 python ns_kws_doa_alexa_with_light.py, 我们会在终端看到很多 debug 的消息. 当我们看到status code: 204的时候, 请说snowboy来唤醒 respeaker。接下来 respeaker 上的 led 灯亮起来, 我们可以跟他对话, 比如问,"谁是最帅的?" 或者 "播放刘德华的男人哭吧哭吧不是罪"。小伙伴,尽情的 High 起来吧。
第五步,怎样用Snowboy自定义唤醒词?
(这步从2021.03.18开始用不了Snowboy网站了,他们家关闭服务器了,你可以去Github上下载别人训练的关键词,拿来用:https://github.com/Kitt-AI/snowboy 当然也可以直接下载我之前训练的:https://download.csdn.net/download/Smile_h_ahaha/16662655 然后再继续阅读第五步中的设置方法)
去这个Snowboy官网(https://snowboy.kitt.ai/dashboard)点击创建新的关键词




然后点击Save and Download, 下载你的自定义声音文件“DaBai.pmdl”.
然后打开树莓派,把这个文件保存自你想保存的路径下。我的是“/home/pi/NBoy”。
然后找到“demo.py”文件。这个文件不同的人安装路径可能不同,但是文件名肯定没错,毕竟是Snowboy大佬写的。我的安装路径在“/home/pi/NBoy”下。
用文本编辑器/sudo nano打开“demo.py”文件,找到如下所示命令:
kws=KWS(model='snowboy')把它注释掉,并用如下代码替换(实际上就是把唤醒词的调取路径换了)
#kws=KWS(model='snowboy')
kws=KWS(model='/home/pi/NBoy/DaBai.pmdl')如果你的唤醒词文件名叫别的什么,你也可以改。库路径随便放哪,你让kws调用的时候找的到就行。
然后保存,文本。
回到树莓派的命令窗口。
挨个输入以下命令
cd ~/home/pi/NBoy
source ~/env/bin/activate
python3 demo.py DaBai.pmdl等见到命令窗口显示“204”,“On ready”的时候,就可以对麦克风说"大白(●—●)"了。你也成了吧,点个赞吧~
第六步,如何更改代码添加GPIO输出(LED灯定义)

用GPIO12和13举例. 我们可以调用python和RPi.GPIO来读取状态。
sudo pip install rpi.gpio // install RPi.GPIO library
sudo nano ledGpio.py // copy the following code in button.pyimport RPi.GPIO as GPIO
import time
BUTTON = 12
LED = 13
GPIO.setmode(GPIO.BCM)
GPIO.setup(BUTTON, GPIO.IN)
GPIO.setup(LED, GPIO.OUT)
while True:
state = GPIO.input(BUTTON)
if state:
print("on")
GPIO.output(LED, GPIO.HIGH)
else:
print("off")
GPIO.output(LED, GPIO.LOW)
time.sleep(1)第七步,安装中遇到的问题,归纳总结。
Q1: 内置算法的参数(高级玩家以后用得到)
pi@raspberrypi:~/usb_4_mic_array $ python tuning.py -p
name type max min r/w info
-------------------------------
AECFREEZEONOFF int 1 0 rw Adaptive Echo Canceler updates inhibit.
0 = Adaptation enabled
1 = Freeze adaptation, filter only
AECNORM float 16 0.25 rw Limit on norm of AEC filter coefficients
AECPATHCHANGE int 1 0 ro AEC Path Change Detection.
0 = false (no path change detected)
1 = true (path change detected)
AECSILENCELEVEL float 1 1e-09 rw Threshold for signal detection in AEC [-inf .. 0] dBov (Default: -80dBov = 10log10(1x10-8))
AECSILENCEMODE int 1 0 ro AEC far-end silence detection status.
0 = false (signal detected)
1 = true (silence detected)
AGCDESIREDLEVEL float 0.99 1e-08 rw Target power level of the output signal.
[−inf .. 0] dBov (default: −23dBov = 10log10(0.005))
AGCGAIN float 1000 1 rw Current AGC gain factor.
[0 .. 60] dB (default: 0.0dB = 20log10(1.0))
AGCMAXGAIN float 1000 1 rw Maximum AGC gain factor.
[0 .. 60] dB (default 30dB = 20log10(31.6))
AGCONOFF int 1 0 rw Automatic Gain Control.
0 = OFF
1 = ON
AGCTIME float 1 0.1 rw Ramps-up / down time-constant in seconds.
CNIONOFF int 1 0 rw Comfort Noise Insertion.
0 = OFF
1 = ON
DOAANGLE int 359 0 ro DOA angle. Current value. Orientation depends on build configuration.
ECHOONOFF int 1 0 rw Echo suppression.
0 = OFF
1 = ON
FREEZEONOFF int 1 0 rw Adaptive beamformer updates.
0 = Adaptation enabled
1 = Freeze adaptation, filter only
FSBPATHCHANGE int 1 0 ro FSB Path Change Detection.
0 = false (no path change detected)
1 = true (path change detected)
FSBUPDATED int 1 0 ro FSB Update Decision.
0 = false (FSB was not updated)
1 = true (FSB was updated)
GAMMAVAD_SR float 1000 0 rw Set the threshold for voice activity detection.
[−inf .. 60] dB (default: 3.5dB 20log10(1.5))
GAMMA_E float 3 0 rw Over-subtraction factor of echo (direct and early components). min .. max attenuation
GAMMA_ENL float 5 0 rw Over-subtraction factor of non-linear echo. min .. max attenuation
GAMMA_ETAIL float 3 0 rw Over-subtraction factor of echo (tail components). min .. max attenuation
GAMMA_NN float 3 0 rw Over-subtraction factor of non- stationary noise. min .. max attenuation
GAMMA_NN_SR float 3 0 rw Over-subtraction factor of non-stationary noise for ASR.
[0.0 .. 3.0] (default: 1.1)
GAMMA_NS float 3 0 rw Over-subtraction factor of stationary noise. min .. max attenuation
GAMMA_NS_SR float 3 0 rw Over-subtraction factor of stationary noise for ASR.
[0.0 .. 3.0] (default: 1.0)
HPFONOFF int 3 0 rw High-pass Filter on microphone signals.
0 = OFF
1 = ON - 70 Hz cut-off
2 = ON - 125 Hz cut-off
3 = ON - 180 Hz cut-off
MIN_NN float 1 0 rw Gain-floor for non-stationary noise suppression.
[−inf .. 0] dB (default: −10dB = 20log10(0.3))
MIN_NN_SR float 1 0 rw Gain-floor for non-stationary noise suppression for ASR.
[−inf .. 0] dB (default: −10dB = 20log10(0.3))
MIN_NS float 1 0 rw Gain-floor for stationary noise suppression.
[−inf .. 0] dB (default: −16dB = 20log10(0.15))
MIN_NS_SR float 1 0 rw Gain-floor for stationary noise suppression for ASR.
[−inf .. 0] dB (default: −16dB = 20log10(0.15))
NLAEC_MODE int 2 0 rw Non-Linear AEC training mode.
0 = OFF
1 = ON - phase 1
2 = ON - phase 2
NLATTENONOFF int 1 0 rw Non-Linear echo attenuation.
0 = OFF
1 = ON
NONSTATNOISEONOFF int 1 0 rw Non-stationary noise suppression.
0 = OFF
1 = ON
NONSTATNOISEONOFF_SR int 1 0 rw Non-stationary noise suppression for ASR.
0 = OFF
1 = ON
RT60 float 0.9 0.25 ro Current RT60 estimate in seconds
RT60ONOFF int 1 0 rw RT60 Estimation for AES. 0 = OFF 1 = ON
SPEECHDETECTED int 1 0 ro Speech detection status.
0 = false (no speech detected)
1 = true (speech detected)
STATNOISEONOFF int 1 0 rw Stationary noise suppression.
0 = OFF
1 = ON
STATNOISEONOFF_SR int 1 0 rw Stationary noise suppression for ASR.
0 = OFF
1 = ON
TRANSIENTONOFF int 1 0 rw Transient echo suppression.
0 = OFF
1 = ON
VOICEACTIVITY int 1 0 ro VAD voice activity status.
0 = false (no voice activity)
1 = true (voice activity)Q2: ImportError: No module named usb.core
如下图所示 路径位置 输入命令 sudo pip install pyusb 安装 pyusb.
pi@raspberrypi:~/usb_4_mic_array $ sudo python tuning.py DOAANGLE
Traceback (most recent call last):
File "tuning.py", line 5, in <module>
import usb.core
ImportError: No module named usb.core
pi@raspberrypi:~/usb_4_mic_array $ sudo pip install pyusb
Collecting pyusb
Downloading pyusb-1.0.2.tar.gz (54kB)
100% |████████████████████████████████| 61kB 101kB/s
Building wheels for collected packages: pyusb
Running setup.py bdist_wheel for pyusb ... done
Stored in directory: /root/.cache/pip/wheels/8b/7f/fe/baf08bc0dac02ba17f3c9120f5dd1cf74aec4c54463bc85cf9
Successfully built pyusb
Installing collected packages: pyusb
Successfully installed pyusb-1.0.2
pi@raspberrypi:~/usb_4_mic_array $ sudo python tuning.py DOAANGLE
DOAANGLE: 180Q3: 有没有树莓派的Alexa的样例? Alexa是在线语音识别系统
A3: 有,(https://github.com/alexa/avs-device-sdk/wiki/Raspberry-Pi-Quick-Start-Guide-with-Script)
Q4: 有在ROS系统上面运行Mic array v2.0 的历程吗
A4: 有,是的,感谢Yuki分享了将ReSpeaker Mic Array v2与ROS(机器人操作系统)中间件集成的软件包。(https://github.com/furushchev/respeaker_ros)
Q5: 能直接通过3.5mm耳机孔听到采样的声音吗?
A5: 不行的。3.5mm耳机孔音源来自于上位机,但是如果用树莓派的话可以通过执行
arecord -D plughw:1,0 -f cd |aplay -D plughw:1,0 -f cd 达到目的。
Q6:运行python3 demo.py resources/xxx路径.umdl的时候出错:
from. import snowboydetect Error.
A6: 把“from. import”改为“import”。
Q7:在我打开Snowboy中的example中的C文件下的例程使,提示打不开。
A7:你忘记编译了。要去cd /python/snowboy/.../Swig/C 目录下 输入 sudo make 先编译,然后就可以运行了。
然后回到cd /.../example/C 下输入 gcc demo.c -o demo 再输入 sudo ./demo运行。C语言和Python操作不同,有问题再搜搜别的地方吧。
Q8:运行例程demo.py的时候,找不到Voice-engine源。
A8:你的Snowboy的python库安装失败,或者安错包了。Snowboy仅支持python2,不支持python3。
python2对应pip
python3对应pip3
网上有些菜鸡们瞎唧唧不负责的教你,导致本应该安装python2的库,安装成了python3(pip3开头的命令都是错的)。那Snowboy的声音引擎(voice engine)肯定识别不了啊。
如下图所示的红框圈起来的安装命令都是错的:


下图所示的样子才是正确的:(源自我上文第四步中内容)你看有python3(pip3)吗?

哎,天下文章一大抄啊,抄来抄去都是米,预知此事要躬行 。
Q9:安装python setup.py install命令的时候没有权限(access)怎么办。
A9:用sudo前缀获得7777权限。sudo python setup.py install
Q10:HDMI连接电脑显示屏,再录音播放的时候听不到声音怎么办?
A10:如果你们遇到HDMI连接电脑显示屏,完事树莓派再外接音箱(想靠它发声),然后录音没问题,播放的时候没声音这样的情况。大多数是声卡设置的时候没设置好。被系统默认成音频走HDMI,即电脑显示屏发声了。这时候要么把外接的音箱接到显示屏上去,要么就认真阅读理解我的“第二步”,把CARD值改成树莓派音频输出。然后就可以了。
Q11: 我未来,还有问题怎么办?
A11:欢迎在评论区留言。
看完不点赞,学分少一半~