分布式、集群、分布式事务相信这几个关键词大家都已经听了无数遍,而这些又是现在互联网不得不提的话题。
那么什么是分布式?什么是集群?什么是分布式事务?
在传统的互联网中,我们通过一个系统业务和存储来完成所有业务。但随着互联网的快速发展传统的架构已经不能满足我们的需求,需要将业务进行拆分处理、或者分库分表来存储业务数据。这时就不得不提到分布式、集群、分布式事务。
分布式:简单来说就是将业务进行拆分,部署到不同的机器来协调处理。比如用户在网上买东西,大致分为:订单系统、库存系统、支付系统、、、、这些系统共同来完成用户买东西这个业务操作。
集群:同一个业务,通过部署多个实例来完成,保证应用的高可用,如果其中某个实例挂了,业务仍然可以正常进行,通常集群和分布式配合使用。来保证系统的高可用、高性能。
分布式事务:按照传统的系统架构,下单、扣库存等等,这一系列的操作都是一在一个应用一个数据库中完成的,也就是说保证了事务的ACID特性。如果在分布式应用中就会涉及到跨应用、跨库。这样就涉及到了分布式事务,就要考虑怎么保证这一系列的操作要么都成功要么都失败。保证数据的一致性。
今天粗略来谈谈分布式事务。
常见的分布式解决方案有:
XA协议
消息事务+最终一致性
TCC编程模式
现在也有许多商业的分布式插件如阿里的GTS(底层是TXC组件)
XA协议
XA是一个分布式事务协议,由Tuxedo提出。XA中大致分为两部分:事务管理器和本地资源管理器。其中本地资源管理器往往由数据库实现,比如Oracle、DB2这些商业数据库都实现了XA接口,而事务管理器作为全局的调度者,负责各个本地资源的提交和回滚。
事务管理器(transaction manager):事务管理器是分布式事务的核心管理者。事务管理器与每个资源管理器(resource manager)进行通信,协调并完成事务的处理。事务的各个分支由唯一命名进行标识。
资源管理器(resource manager):用来管理系统资源,是通向事务资源的途径。数据库就是一种资源管理器。资源管理还应该具有管理事务提交或回滚的能力。
XA协议(2pc协议,全称Two Phase Commitment Protocol)也被称为二阶段提交协议,通常主要是解决分布式数据库下,保证数据一致性问题。相对于数据库层面。其结构图如下:
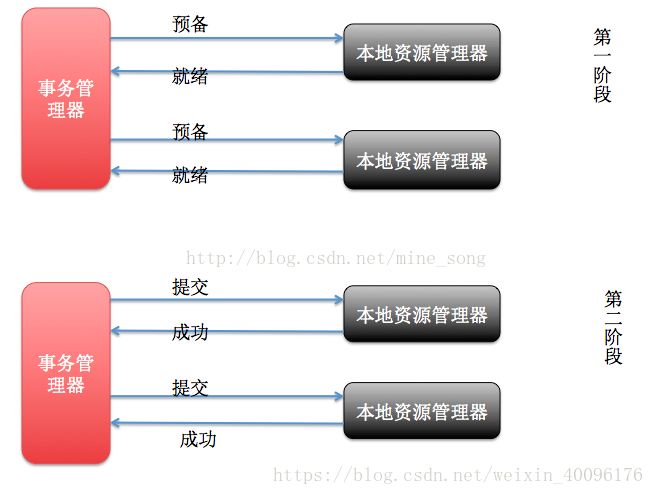
分布式事务通过2PC协议将提交分成两个阶段:
prepare;
commit/rollback
阶段一为准备(prepare)阶段。即所有的参与者准备执行事务并锁住需要的资源。参与者ready时,向transaction manager报告已准备就绪。
阶段二为提交阶段(commit)。当transaction manager确认所有参与者都ready后,向所有参与者发送commit命令。
因为XA 事务是基于两阶段提交协议的,所以需要有一个事务协调者(transaction manager)来保证所有的事务参与者都完成了准备工作(第一阶段)。如果事务协调者(transaction manager)收到所有参与者都准备好的消息,就会通知所有的事务都可以提交了(第二阶段)。MySQL 在这个XA事务中扮演的是参与者的角色,而不是事务协调者(transaction manager)
Mysql的XA事务分为外部XA和内部XA
外部XA用于跨多MySQL实例的分布式事务,需要应用层作为协调者,通俗的说就是比如我们在PHP中写代码,那么PHP书写的逻辑就是协调者。应用层负责决定提交还是回滚,崩溃时的悬挂事务。MySQL数据库外部XA可以用在分布式数据库代理层,实现对MySQL数据库的分布式事务支持,例如开源的代理工具:网易的DDB,淘宝的TDDL等等。
内部XA事务用于同一实例下跨多引擎事务,由Binlog作为协调者,比如在一个存储引擎提交时,需要将提交信息写入二进制日志,这就是一个分布式内部XA事务,只不过二进制日志的参与者是MySQL本身。Binlog作为内部XA的协调者,在binlog中出现的内部xid,在crash recover时,由binlog负责提交。(这是因为,binlog不进行prepare,只进行commit,因此在binlog中出现的内部xid,一定能够保证其在底层各存储引擎中已经完成prepare)。
XA协议比较简单,而且一旦商业数据库实现了XA协议,使用分布式事务的成本也比较低。但是,XA也有致命的缺点,那就是性能不理想,所以对于高并发业务的系统来说尽量避免使用XA协议。
消息事务+最终一致性
所谓的消息事务就是基于消息中间件的两阶段提交,本质上是对消息中间件的一种特殊利用,它是将本地事务和发消息放在了一个分布式事务里,保证要么本地操作成功成功并且对外发消息成功,要么两者都失败,开源的RocketMQ就支持这一特性,具体原理如下:
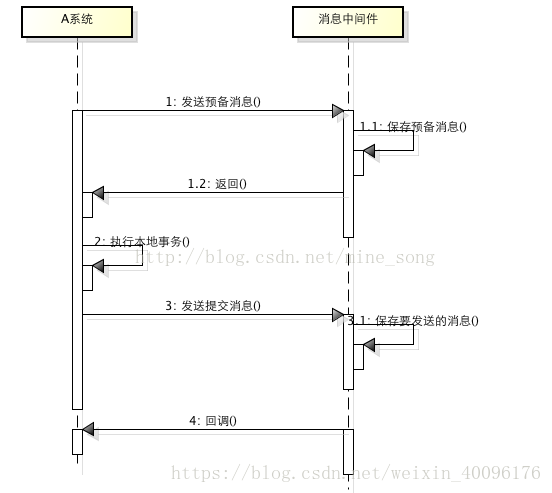
就像上面提到的分布式应用,将业务通过拆分成不同的应用来协调完成。可以通过消息中间件来间接实现分布式事务。基于消息中间件的两阶段提交往往用在高并发场景下,将一个分布式事务拆成一个消息事务(A系统的本地操作+发消息)+B系统的本地操作,其中B系统的操作由消息驱动,只要消息事务成功,那么A操作一定成功,消息也一定发出来了,这时候B会收到消息去执行本地操作,如果本地操作失败,消息会重投,直到B操作成功,这样就变相地实现了A与B的分布式事务。原理如下:
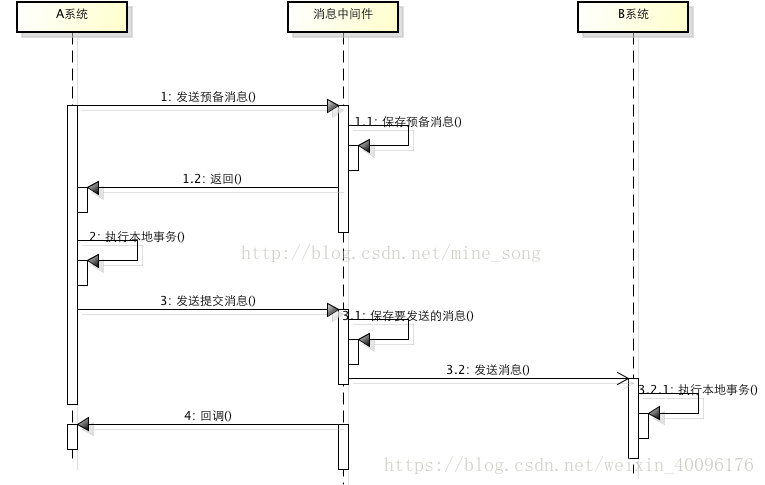
虽然上面的方案能够完成A和B的操作,但是A和B并不是严格一致的,而是最终一致的,我们在这里牺牲了一致性,换来了性能的大幅度提升。当然,这种玩法也是有风险的,如果B一直执行不成功,那么一致性会被破坏,具体要不要玩,还是得看业务能够承担多少风险。
注意Rocketmq在3.0.8版本后对事物进行了阉割,没有回调机制,需要自己通过业务操作实现。
TCC编程模式
如果你将应用看做资源管理器的话,TCC是应用层的2PC(2 Phase Commit, 两阶段提交),应该是三个英文单词的首字母缩写而来。没错,TCC分别对应Try、Confirm和Cancel三种操作,这三种操作的业务含义如下:
Try:预留业务资源
Confirm:确认执行业务操作
Cancel:取消执行业务操作
稍稍对照下关系型数据库事务的三种操作:DML、Commit和Rollback,会发现和TCC有异曲同工之妙。在一个跨应用的业务操作中,Try操作是先把多个应用中的业务资源预留和锁定住,为后续的确认打下基础,类似的,DML操作要锁定数据库记录行,持有数据库资源;Confirm操作是在Try操作中涉及的所有应用均成功之后进行确认,使用预留的业务资源,和Commit类似;而Cancel则是当Try操作中涉及的所有应用没有全部成功,需要将已成功的应用进行取消(即Rollback回滚)。其中Confirm和Cancel操作是一对反向业务操作。
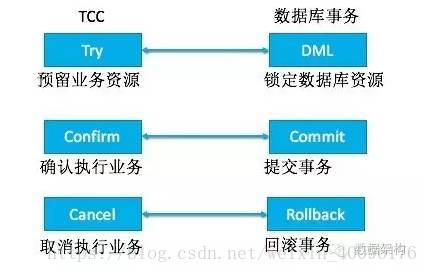
详细来说
1、Try:尝试执行业务。
完成所有业务检查(一致性)
预留必须业务资源(准隔离性)
2、Confirm:确认执行业务。
真正执行业务
不做任何业务检查
只使用Try阶段预留的业务资源
3、Cancel:取消执行业务
释放Try阶段预留的业务资源
TCC事务需要通过业务操作来实现分布式事务,开发成本较高,对开发人员要求对事物详细了解,才能开发出高效的事务。
当然现在有很多商业的组件,使用简单,但具体使用哪种方式还得看业务选择。
参考文档:https://blog.csdn.net/kobejayandy/article/details/54783212