Leader选举是zookeeper很重要的机制,也是保证分布式数据一致性的关键所在。上一篇的zookeeper角色中我们提到只有Leader才具有事务请求处理的权利,本篇我们来看看Leader的选举。
先来看几个术语
SID:服务器ID
SID是一个数字,用来唯一标识一台Zookeeper集群中的机器,每台机器不能重复,和myid的值一致。关于myid可以参考Linxu集群搭建
ZXID:事务ID
ZXID是一个事务ID,用来唯一标识一次服务器状态的变更。在某一时刻,集群中每台机器的ZXID值不一定完全一致,这和ZooKeeper服务器对于客户端更新请求的处理逻辑有关。
Vote:投票
当集群中的机器发现自己无法检测到Leader机器的时候,就会开始尝试进行投票
Quorum:过半机器数
这是整个Leader选择算法中最重要的一个术语,指的是Zookeeper集群中过半的机器数,如果集群中总的机器数是n的话: quorum = (n/2 + 1)
LOOKING
寻找Leader状态。当服务器处于该状态时,它会认为当前集群中没有Leader,因此需要进入Leader选举流程。
FOLLOWING
跟随者状态,表明当前服务器角色是Follower
LEADING:
领导这状态,表明当前服务器角色是Leader
OBSERVING”
观察者状态,表明当前服务器角色是Observer
Leader选举会发生在服务器启动时期和运行时期,首先选举的背景是在集群环境中,也就是说至少要有两台服务器(我们以三台为例)。
服务器启动时的Leader选举
第一台服务器启动时,无法完成Leader选举,当第二台启动后,此时这两台服务器已经能后进行互相通信,每台机器都试图找到一个Leader,于是进入了Leader选举流程。
1、每个Server会发出一个投票
在初始情况,server1和server2都会将自己作为Leader服务器进行投票,每次投票包含的最基本的元素包括:所推荐的服务器的myid和ZXID,以(myid,ZXID)的形式来表示。初始阶段server1的投票(1,0),server2的投票(2,0),然后各自将这个投票发给集群中的其他所有机器。
2、接收来自各个服务器的投票
每个服务器都会接收来自其他服务器的投票。集群中的每个服务器在接收到投票后,先判断该投票的有效性,包括检查是否是本轮投票、是否来自LOOKING状态的服务器。
3、处理投票
在接收到来自其他服务器的投票后,针对每一个投票,服务器都需要将别人的投票和自己的投票进行PK,PK的规则如下
- 优先检查ZXID。ZXID比较大的服务器优先作为Leader
- 如果ZXID相同的话,那么就比较myid。myid比较大的服务器作为Leader服务器。
由于server1和server2的ZXID都是0,而server2的myid大于server1,于是server1更新自己的投票为(2,0),然后重新将投票发出去。而对于server2来说,只是再向集群中的所有机器发上一次的投票信息即可。
4、统计投票
每次投票后,服务器都会统计所有投票,判断是否已经有过半的机器接收到相同的投票信息。对于server1和server2来说,都统计出集群中已经有两台机器接收了(2,0)这个投票信息。由于这里集群是3台,经过(n/2+1)得出2,满足了大于或等于2台的“过半”要求。因此Leader就被选出来了。
5、改变服务器状态
一旦确定了Leader,每个服务器就会更新自己的状态:如果是Follower,那么就变更为FOLLOWING,如果是Leader,那么就变更为LEADING.
服务器运行时的Leader选举
在Zookeeper集群正常运行过程中,一旦选出一个Leader,那么所有服务器的机器角色一般不会再发送变化,但有一个种情况列外,假如Leader服务器挂了,那么整个集群将暂时无法对我服务,而是进入新一轮的Leader。
1、状态变更
当Leader挂了后,余下的非Observer服务器都会将自己的服务器状态变更为LOOKING,然后开始进入Leader选举流程。其他流程与启动时期的Leader选举基本一致。
Leader选举算法
在ZooKeeper中,提供了三种Leader选举的算法,分别是LeaderElection、UDP版本的FastLeaderElection和TCP版本的FastLeaderElection,可以通过配置文件zoo.cfg中使用electionAlg属性来指定,分别使用数字0~3来表示,0代表LeaderElection;1代表UDP版本的FastLeaderElection,非授权模式;2代表UDP版本的FastLeaderElection,授权模式;3代表TCP版本的FastLeaderElection。从3.4.0版本开始,Zookeeper只保留了TCP版本的FastLeaderElection。
进入Leader选举
当ZooKeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举。
- 服务器初始化启动
服务器运行期间无法和Leader保持连接
而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态。集群中本来就已经存在一个Leader
- 集群中确实不存在Leader
第一种已经存在Leader的情况。这种情况通常是集群中的某一台机器启动比较晚,在它启动之前,集群已经可以正常工作,即已经存在了一台Leader服务器。当该机器试图去选举Leader的时候,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立起连接,并进行状态同步即可。在集群中Leader不存在的情况下,就要开始进行Leader选举了。
开始第一次投票
通常有两种情况会导致集群中不存在Leader,一种情况是在整个服务器刚刚初始化启动时,尚为产生一台Leader服务器;另一种情况就是在运行期间当前Leader所在的服务器挂了。无论是哪种情况,此时集群中的所有机器都处于一种试图选举出一个Leader的状态,这种状态就是”LOOKING”,当一台服务器处于LOOKING状态的时候,它会想集群中的所有其他机器发送消息,我们称这个消息为“投票”。
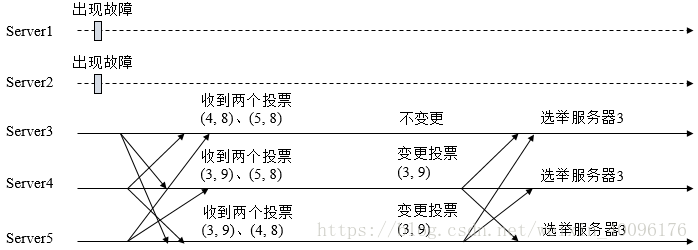
在这个投票消息中包含了两个最基本的信息:所推举的服务器的SID和ZXID,分别表示了被推荐服务器的唯一标识和事务ID。我们以(SID,ZXID)这样的形式来标识一次投票信息。假设一个ZooKeeper集群由5台机器组成,SID分别为1、2、3、4、5,ZXID分别为9、9、9、8、8,并且此时SID为2的机器是Leader服务器。某一时刻,1和2所在的机器出现故障,因此集群开始进行Leader选举。
在第一次投票时,由于还无法检测到集群中其他机器的状态信息,因此每天机器都是讲自己作为被推荐的对象来进行投票。于是SID为3、4、5的机器,投票情况分别为:(3,9)(4,8)(5,8)
变更投票
集群中的每台机器发出自己的投票后,也会接受到来自集群中其他机器的投票。每台机器会根据一定的规则,来处理收到的其他机器的投票,并以此来决定是否需要变更自己的投票。这个规则也成为了整个Leader选举算法的核心所在。
- vote_sid:接收到的投票中所推举Leader服务器的SID
- vote_zxid:接收到的投票中所推举Leader服务器的ZXID
- self_sid:当前服务器自己的SID
- self_zxid:当前服务器自己的ZXID
每次对于收到的投票的处理,都是一对(vote_sid,vote_zxid)和(self_sid,self_zxid)对比的过程。 - 规则1:如果vote_zxid大于self_zxid,就认可当前收到的投票,并再次将该投票发送出去。
- 规则2:如果vote_zxid小于self_zxid,那么就坚持自己的投票,不做任何变更。
- 规则3:如果vote_zxid等于self_zxid,那么就对比两者的SID。如果vote_sid大于self_sid,那么就认可当前接收到的投票,并再次将投票发送出去。
- 规则4:如果vote_zxid等于self_zxid,并且vote_sid小于self_sid,那么同样坚持自己的投票,不做变更。
根据上面的规则,变更过程如下图:
确定Leader
经过第二次投票后,集群中的每台机器都会再次收到其他机器的投票,然后开始统计投票。如果一台机器收到超过半数的相同的投票,那么这个投票对应的SID机器即为Leader.
对于本次来说 quorum = (5/2+1)=3
也就是说,只要收到3个或3个以上(含当前服务器自身在内)一致的投票即可。在这里server3、server4、server5都投票(3,9),因此确定了server3为Leader。
简单的说,通常哪台服务器上的数据越新,那么越有可能成为Leader,因为数据越新,它的ZXID也就越大,也越能保证数据的恢复。
参考文献:《从Paxos到Zookeeper 分布式一致性原理与实践 》