概述
在《软件定义安全》中介绍了所有的安全产品本质上就是对安全业务的软件开发。本文介绍WAF的核心内容和核心逻辑。
一、WAF的作用
Web应用防护墙(Web Application Firewall,简称WAF)是通过执行一系列针对HTTP/HTTPS的安全策略来专门为Web应用提供保护的一款产品,主要用于防御针对网络应用层的攻击,像SQL注入、跨站脚本攻击、参数篡改、应用平台漏洞攻击、拒绝服务攻击等。
1.1 为什么要上WAF
WAF是专门为保护基于Web应用程序而设计的,传统的防火墙,是基于互联网地址和端口号来监控和阻止数据包。一个标准的端口号对应一种网络应用程序类型。传统防火墙无法应对应用层的攻击进行有效抵抗。虽然IPS可以做到部分应用层的防护,但由于IPS是全流量全协议的,所以从能力上看很难把每种协议都防护的很好,从性能上看添加过多的防护策略会导致性能跟不上,所以出现了Web应用防火墙系统,只防护Web协议。
1.2 WAF的部署模式
WAF要想达到防护效果必须要串接到网络中,串接到网络中主要有透明代理串接模式和反向代理模式,这两种在实际环境中用的都挺多的。当然如果只做检测不做阻断也可以用旁路模式。
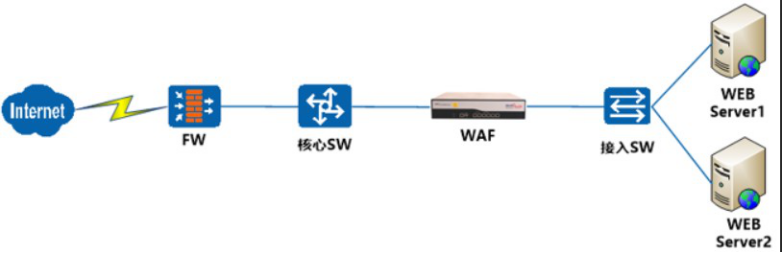
透明代理模式
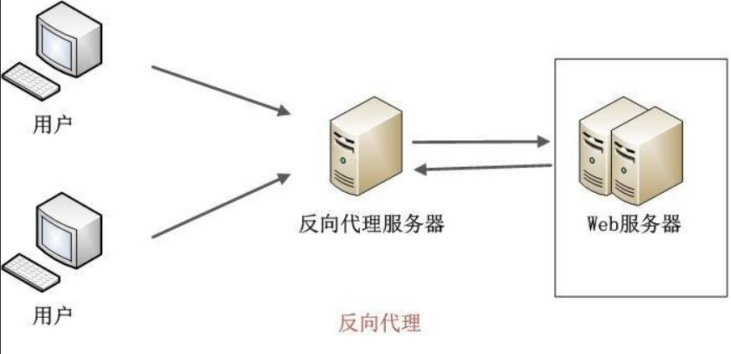
反向代理模式
二、WAF的技术
WAF主要是由流量采集和攻击分析引擎两部分组成,流量采集部分比较通用,采集这个和IPS等是通用的可以参考《安全产品的核心逻辑-IPSIDS》。很多的WAF的设计开发是在代理服务器上修改的,比如nginx,haproxy等。
2.1 攻击分析
攻击分析主要是根据采集到的Web协议,分析http/https的报文中有没有攻击行为。这个和IPS的分析逻辑也有些类似,主要是正则表达式、关键字匹配、上下文分析等。开源的有两种规则可以参考借鉴,ModSecurity规则和Naxsi规则。
2.2 ModSecurity规则
ModSecurity是一个开源的跨平台Web应用程序防火墙(WAF)引擎,用于Apache,IIS和Nginx,由Trustwave的SpiderLabs开发。作为WAF产品,ModSecurity专门关注HTTP流量,当发出HTTP请求时,ModSecurity检查请求的所有部分,如果请求是恶意的,它会被阻止和记录。
2.2.1 ModSecurity的规则
基本格式:SecRule VARIABLES OPERATOR ACTIONS
SecRule:ModSecurity主要的指令,用于创建安全规则,固定单词。
VARIABLES:代表HTTP包中的标识项,规定了安全规则针对的对象。常见的变量包括:ARGS(所有请求参数)、FILES(所有文件名称)等。
OPERATOR:代表操作符,一般用来定义安全规则的匹配条件。常见的操作符包括:@rx(正则表达式、@streq(字符串相同)、@ipmatch(IP相等)等。
ACTIONS:代表响应动作,一般用来定义数据包被规则命中后的响应动作。常见的动作包括:deny(数据包被拒绝)、pass(允许数据包通过)、everity(定义事件严重程度)等。详见:https://github.com/SpiderLabs/ModSecurity/wiki/Reference-Manual-(v2.x)
2.2.2 ModeSecurity规则例解
规则1:防XSS攻击
以下规则用于通过检查请求参数和标头中的<script>模式来避免XSS攻击,并生成带有404状态响应的“XSS Attack”消息。
SecRule ARGS|REQUEST_HEADERS “@rx <script>” id:101,msg: ‘XSS Attack,’ severity:ERROR,deny,status:404
SecRule 固定单词,规则要以这个为开头。
VARIABLES包括两部分:ARGS:所有请求参数;REQUEST_HEADERS:请求数据头部。
OPERATOR
@rx <script>:如果正则匹配字符串"<script>"成功,则规则执行。ACTIONS 动作和详细记录。
id, msg, severity, deny, status 如果模式匹配,这些都是要记录或者执行的操作
-
id:001规定该条规则编号为001;
-
msg: 'XSS Attack’代表记录信息为:XSS Attack;
-
severity:ERROR表示严重程度为ERROR;
-
deny表示拒绝所有请求包;
-
status:404表示服务器响应状态编号为404。
规则2:设置白名单
以下示例显示如何将IP地址列入白名单以绕过ModSecurity引擎:
SecRule REMOTE_ADDR “@ipMatch 192.168.1.101” id:102,phase:1,t:none,nolog,pass,ctl:ruleEngine=off
SecRule 固定单词,规则要以这个为开头。
VARIABLES
REMOTE_ADDR:远程主机IP
OPERATOR
@ipmatch 192.168.1.101:如果请求主机IP地址为192.168.1.101,则规则执行。
ACTIONS
-
id:102规定该条规则编号为102;
-
phase:1表示规则执行的范围为请求头部;
-
t:none表示VARIABLES的值不需要转换(t代表transform);
-
nolog代表不记录日志;pass代表继续下一条规则;
-
ctl:ruleEngine=off代表关闭拦截模式,所有规则失效。
一个比较有名的ModSecurity的规则库:OWASP ModSecurity Core Rule Set (CRS) https://github.com/coreruleset/coreruleset/
里面带了大量的规则库。
更详细的语法参见:
https://github.com/SpiderLabs/ModSecurity/wiki/Reference-Manual-(v2.x)
从中可以看出语法相当复杂,比如Variables就有好几十个,下面是部分截图:
所以才有了一个简化的WAF引擎和规则Naxsi。
2.3 Naxsi规则
Naxsi是一个开放源代码、高效、低维护规则的Nginx Web应用防火墙模块。它的主要目标是帮助人们加固Web应用程序,以抵御SQL注入、跨站脚本、跨域伪造请求、本地和远程文件复制等包含的漏洞。
规则主要包括以下几部分:
MainRule:定义检测规则和评分
BasicRule:定义 MainRule 的白名单
CheckRule:定义当分数达到阀值时所采取的动作
MainRule标识符用于标记检测规则,与BasicRules相反,BasicRules通常用于将某些MainRule列为白名单。
语法规则

MainRule规则必须以 MainRule 为开头,
Message(msg):这个是对这条规则的描述
SearchString(str):定义条件,可以是字符串或者正则表达式,"str:searchstr" or regex- pattern with "rx:reg.+ex",对字符串不区分大小写,但从效率上看字符串比正则表达式快很多。
MatchingZones(mz):定义搜索在哪些应用的请求中有效。包括的位置如下:
-
ARGS:GET参数
-
HEADERS:HTTP头
-
BODY:POST参数(and RAW_BODY)
-
URL:URL(before '?')
或者具体点:
-
$ARGS_VAR:string:具体的GET参数
-
$HEADERS_VAR:string:具体的HTTP头,比如:
-
$HEADERS_VAR:User-Agent
-
$HEADERS_VAR:Cookie
-
$HEADERS_VAR:Content-Type
-
$HEADERS_VAR:Connection
-
$HEADERS_VAR:Accept-Encoding
-
$BODY_VAR:string:具体的POST参数
或者用正则来表示:
$HEADERS_VAR_X:regex: 正则匹配具体的HTTP头(>=0.52)
$ARGS_VAR_X:regex: 正则匹配具体的GET参数
$BODY_VAR_X:regex: 正则匹配具体的POST参数
具体点: * FILE_EXT: 文件名
Scores (s):分数定义了某种攻击类型。每个规则都定义了一个或多个分数,每当生成一个事件时,分数都会按定义的值进行增加。分数后面由CheckRule指令进行处理。
预设的名称有:($AQL, §RFI, $TRAVERSAL, $XSS, $EVADE),但也可以自己添加。
Signature IDs (id):规则id,不重复
BasicRule是白名单:
白名单的添加最好能以日志为基础进行操作。主要确定哪些内容不进行检测。
例如:特定URL上的通用白名单
BasicRule wl:1100“mz:$URL:/some/URL | URL”;
Naxsi自带了一个基本的核心规则集,可以抵御常见的攻击,主要包括:

CheckRule检测分数后的动作
-
CheckRule "$SQL >= 8" BLOCK;
-
CheckRule "$RFI >= 8" BLOCK;
-
CheckRule "$TRAVERSAL >= 4" BLOCK;
-
CheckRule "$EVADE >= 4" BLOCK;
-
CheckRule "$ XSS >= 8" BLOCK;
以上是加载在内置中的CheckRule。他们的主要作用是读取计数器中的数值,与CheckRule中所设定的数值进行对比,一旦符合设定,那么将进行响应的动作。
以上的CheckRule意味着当名为$SQL、$RFI、$TRAVERSAL、$EVADE和$XSS这些计数器的值达到设定值后,将禁止访问。
动作主要包括:
-
DROP:抛弃请求,不做任何回应
-
BLOCK:根据DeniedUrl的设定进行跳转
-
ALLOW:允许通过
-
LOG:仅记录在日志中,不做任何动作
MainRule的基本要求
除了id外,其他的操作符号必须放在双引号内。规则单独放在一个配置文件中,例如:
include /etc/nginx/rules/naxsi_core.rules;
例如比如在请求中,如果GET、POST或者URL中包含字符串searchstring,则匹配成功,匹配成功用赋值参数XSS评分为8.
MainRule "msg:this is a message" "str:searchstring" "mz:URL|BODY|ARGS" "s:$XSS8" id:12345678990;
MainRule是固定写法
msg 是攻击发生的时候描述的字符串
str 匹配到searchstring的时候
mz 匹配的范围
s 评分或者直接动作也可以,比如:"s:DROP"
BasicRule白名单
BasicRule wl:1100 "mz:$URL/some/url|URL";
检查规则
CheckRule "XSS >= 8 " DROP ;XSS参数就是在MainRule的s中定义的参数。含义是当$XSS的只大于8则抛弃请求。
更多详细的语法介绍:
https://zero.bs/naxis-rules-manual.html
更多规则可以参考:
https://github.com/nbs-system/naxsi/blob/master/naxsi_config/naxsi_core.rules h ttps://github.com/nbs-system/naxsi-rules
2.4 机器学习
传统的WAF,依赖规则和黑白名单的方式来进行Web攻击检测。该方式过分依赖知识库,安全人员对知识库的研究和更新非常重要,但针对未知攻击类型还是无能为力;另一方面即使是已知的攻击类型,由于正则表达式,字符串匹配等天生的局限性,以及shell、php等语言极其灵活的语法,理论上就是可以绕过,因此误拦和漏拦是天生存在的;而提高正则准确性的代价就是添加更多精细化正则,规则过多会拖累WAF的整体性能。
机器学习理论内容非常多,这里不做过多阐述,只介绍一种效果比较好的思路。机器学习本质是一种统计学。
针对每个url进行学习,把url中的每个参数都进行分析,分析出参数和值两种,然后把每个字符当作一个特征向量,理论上只要给它喂养的样本足够充分,它会自己学习到一个字符集组合,出现在url的什么位置处所代表的含义,从而识别出未知攻击。
但机器学习取决于样本的规模和算法的调优。还有机器学习对性能有一定的影响,如果降低对资源的依赖也是一个挑战。
三、总结
从上面的分析可以看出WAF的检测原理其实并不是太复杂,而且比较容易理解,最简单的可以到包含某个字符串就认为是攻击。但真实的环境和攻击者往往是很复杂的,所以误报和饶过一直是这类产品最核心的竞争力,但这块也没有那么多高大上的东西,无非就是拼谁家策略做的及时有效,谁家机器学习的调优比较准确。说到底就是安全没有银弹,只有老老实实把基础做好做扎实了才能发挥更大的价值。
相关分享: