前段时间在IP102数据集上做了一些实验,在测试集上的预测结果通过文本的方式不便于直接观察,于是有了一些可视化的需求:可视化数据的原始分布和各类别的预测情况。
分析
可视化数据的原始分布直接通过 plt.bar() 画柱形图就行,各类别的预测情况通过 matshow() 函数画出混淆矩阵也很方便观察。
但是混淆矩阵只是通过颜色来展示数据相对的大小,我还想通过图来看数据之间的绝对大小,也就是说我想把这两个需求放在一张图里...
那么在原始柱形图的基础上,画各类别预测情况的折线图也不是一个难事,但是当预测类别太多的时候,多条折线图糊在一起可太难观察了!于是又产生了新的需求:鼠标点击某个柱形(类别)时,显示该类别测试数据在各类别上的预测情况。
代码
这里的数据是使用某网络对IP102中水稻的14类虫害的预测结果。 本文主要想分享的是自己突发奇想的可视化方法和matplotlib鼠标点击事件的实现,相关的json文件读取、数据获取等代码这里就不粘了,需要使用的数据都直接粘在main函数里。下面是copy过去可以直接跑的代码:
import random
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.ticker import MultipleLocator
# 随机生成一个颜色
def getRandomColor():
colorArr = ['1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F']
color = ""
for i in range(6):
color += colorArr[random.randint(0, 14)]
return "#"+color
# 通过柱形图可视化测试样本分布情况,鼠标点击某个柱形图时,显示该类别测试数据在各类别上的预测情况
def visualize(idx2name, label_distr, pred_distr):
classes_name = [name for idx, name in idx2name.items()] # x轴名称
x = range(len(classes_name))
color_list = [getRandomColor() for i in x] # 颜色列表
fig1, ax = plt.subplots()
def plot_bar():
barlist = plt.bar(x, label_distr, width=0.3) # 条形图
for i in x:
barlist[i].set_color(color_list[i]) # 设置每个条形的颜色
plt.xticks(range(len(classes_name)), classes_name, rotation=90, fontsize=8) # x轴各刻度的名称
def call_back(event):
plt.cla()
plot_bar()
xdata = event.xdata
cur_class = round(xdata) # 确定点击的是那个条形柱
if cur_class < 0:
cur_class = 0
elif cur_class > len(classes_name) - 1:
cur_class = len(classes_name) - 1
cur_pred = pred_distr[str(cur_class)]
plt.plot(x, cur_pred, color_list[cur_class], linewidth=1)
plt.scatter(x, cur_pred, color="black", s=10)
fig1.canvas.draw_idle()
plot_bar()
fig1.canvas.mpl_connect('button_press_event', call_back) # 鼠标点击事件
plt.show()
# 可视化混淆矩阵
def visulize_matric(idx2name, pred_distr):
classes_name = [name for idx, name in idx2name.items()]
mat = []
for cur_class_idx, cur_pred in pred_distr.items():
cur_pred = np.array(cur_pred)
cur_pred = cur_pred / sum(cur_pred)
mat.append(cur_pred)
fig2 = plt.figure()
ax = fig2.add_subplot(111)
cax = ax.matshow(mat)
fig2.colorbar(cax)
ax.set_xticklabels([''] + classes_name, rotation=90, fontsize=6) # set up axes
ax.set_yticklabels([''] + classes_name, fontsize=6)
ax.xaxis.set_major_locator(MultipleLocator(1))
ax.yaxis.set_major_locator(MultipleLocator(1))
plt.show()
if __name__ == '__main__':
# 类别索引到类别名称的映射(14)
idx2name = {'0': 'brown plant hopper', '1': 'rice water weevil', '2': 'small brown plant hopper',
'3': 'paddy stem maggot', '4': 'grain spreader thrips', '5': 'rice shell pest',
'6': 'yellow rice borer', '7': 'asiatic rice borer', '8': 'rice leaf caterpillar',
'9': 'white backed plant hopper', '10': 'rice leafhopper', '11': 'rice leaf roller',
'12': 'Rice Stemfly', '13': 'rice gall midge'}
label_distr = [251, 257, 166, 79, 52, 123, 152, 316, 147, 268, 122, 335, 111, 152] # 14类数据的标签分布情况
# 各类别下图片预测情况
pred_distr = {'0': [110, 5, 48, 0, 0, 0, 4, 8, 0, 49, 14, 8, 1, 4],
'1': [3, 217, 1, 2, 2, 0, 2, 13, 4, 4, 0, 3, 3, 3],
'2': [21, 1, 88, 1, 0, 0, 1, 9, 0, 35, 3, 2, 4, 1],
'3': [1, 6, 0, 39, 0, 0, 2, 7, 3, 1, 3, 1, 14, 2],
'4': [1, 1, 1, 0, 40, 0, 3, 0, 0, 1, 2, 1, 2, 0],
'5': [0, 2, 0, 0, 0, 63, 3, 3, 11, 2, 0, 37, 2, 0],
'6': [1, 2, 0, 0, 0, 2, 108, 29, 0, 4, 1, 3, 1, 1],
'7': [2, 3, 2, 9, 1, 6, 51, 203, 13, 2, 3, 16, 3, 2],
'8': [1, 4, 0, 4, 3, 9, 6, 10, 80, 0, 1, 25, 2, 2],
'9': [37, 3, 49, 1, 1, 4, 2, 17, 2, 137, 6, 4, 4, 1],
'10': [5, 3, 12, 1, 0, 2, 1, 5, 3, 8, 76, 1, 3, 2],
'11': [2, 3, 0, 3, 0, 22, 3, 10, 13, 1, 2, 267, 3, 6],
'12': [0, 2, 1, 9, 0, 0, 4, 6, 3, 3, 3, 0, 78, 2],
'13': [1, 1, 0, 3, 1, 2, 0, 3, 0, 4, 3, 2, 2, 130]}
visualize(idx2name, label_distr, pred_distr) # 可视化数据分布图
visulize_matric(idx2name, pred_distr) # 可视化混淆矩阵
input()
效果
运行代码将会先画出柱形图(测试集中各类别的原始分布情况):

此时,点击某个柱形时,会画出该类别数据在各类别上的预测情况:

如点击图中黄色柱形,黄色柱形表示rice leaf roller这一类别共有335张图像,折线图表示这些图像在各类别上的预测情况,分别有2, 3, 0, 3, 0, 22, 3, 10, 13, 1, 2, 267, 3, 6张图像预测为第1-14类。点击其他柱形图同理。
关闭当前窗口后,将出现混淆矩阵窗口,如下:
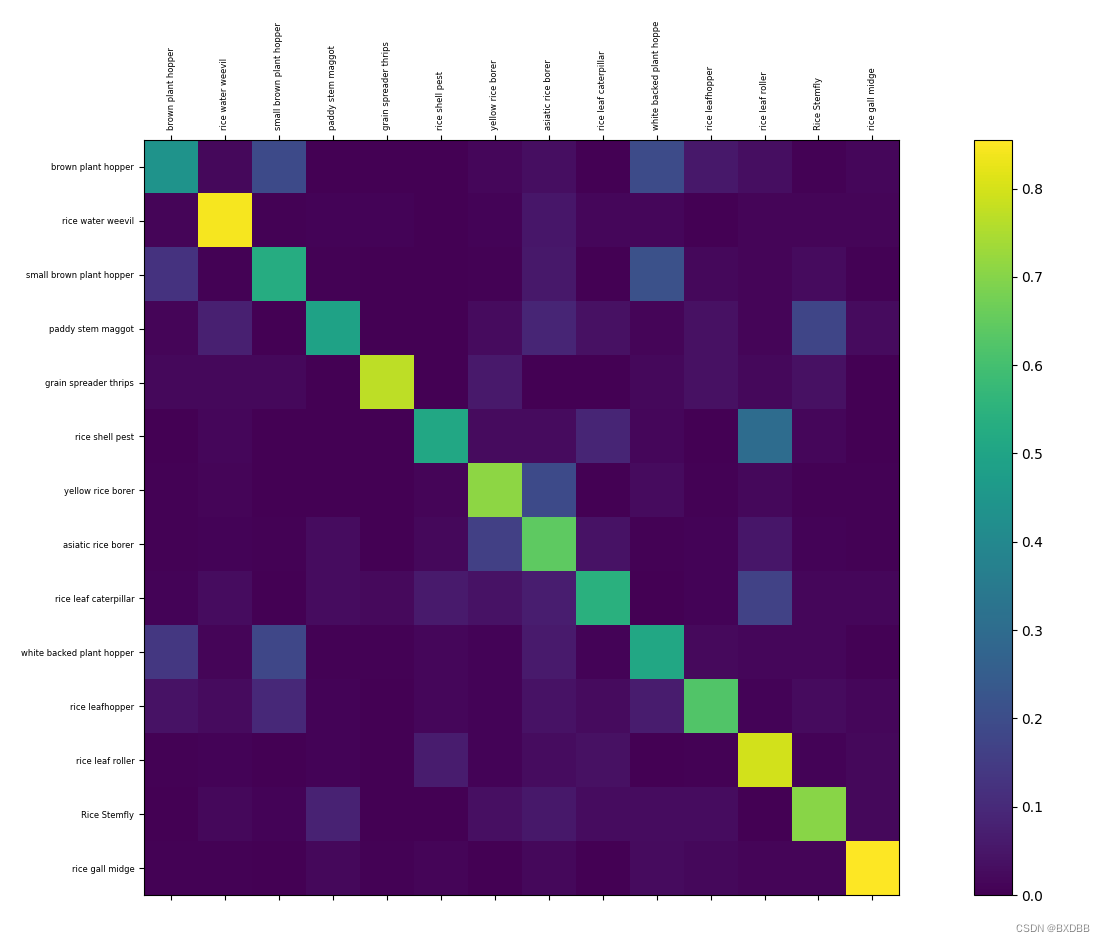
混淆矩阵也能反映出一些数据关系和模型特性,这里不做分析。
快在自己的数据上试试吧~