# 字典
a = None # None = null
b = False # boolean
c, d = 12, 10.6 # int float
e = 'asdd' # str
f = ['s', 'e'] # list,数组,可增删改查
g = ('a', 's', 'f') # 元组(tuple),只能查

# 字典
t = {
# 键:值
'': '',
'': ''
}
# 字典
# dict key: value key是唯一的,无序的
h = {
's': 12,
'f': False,
2: 'd',
'r': 't',
'sd': ['gf', 'rt', ' ew'],
'rt': ('rte', 'ewr'),
'ru': {
'rty': 'fghg',
'dfs': 'yjtujyt'
}
}
# print(h)
print(h['ru']) # 取出指定的key为ru的值

# 取出所有的key
keys = h.keys()
print(keys)
'''
# 遍历所有的key
for i in list(keys):
print('%s = %s'%(i, h[i]))
'''
abc = {'aa': 'dd', 'bb': 'th'}
print(abc)
print(type(abc)) # 查看abc的数据类型
aaa = str(abc) # 字典转str
print(type(aaa))
print(aaa)
bbb = eval(aaa) # str转字典
print(type(bbb))
print(bbb)

# 字符串转字典
bbb = eval(aaa)
print(type(bbb))
print(bbb)

# 字典转json: json本质是字符串,只是按一定规则转换的
d_json = json.dumps(h)
print(d_json)
print(type(d_json))

# json(str)转字典 : 把json格式转换成字典格式
json_dict = json.loads(d_json)
print(type(json_dict))
print(json_dict)

# 传json参数
import requests
url = 'xxxxxxxx'
body = {
'xxx': 'xxx',
'xxx': 'xxx'
}
# body是json格式的
r = requests.post(url, json=body)
print(r.text)

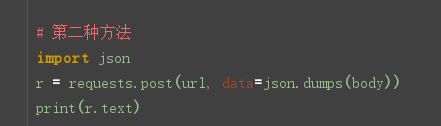
# 第二种方法
import json
r = requests.post(url, data=json.dumps(body))
print(r.text)
import requests
url = "http://v.juhe.cn/weather/index"
par = {
"cityname": "深圳", # 城市名或城市ID,如:"苏州",需要utf8 urlencode
"dtype": "json", # 返回数据格式:json或xml,默认json
"format": "1", # 未来7天预报(future)两种返回格式,1或2,默认1
"key": "80b4d4e1d870d257d3344fcf2d08f64a" # key须申请
}
r = requests.get(url, params=par)
print(r.text) # json格式的str

# 1、requests里面自带解析器转字典
print(r.json())
print(type(r.json()))

# 取出json中的'result_sk_temp'字段
# {"resultcode":"200","reason":"查询成功","result":{"sk":{"temp":"28","wind_direction":"东南风","wind_strength":"2级"
result = r.json()["result"]['sk']['temp']
print(result)

# 2、json模块转字典
import json
print(json.loads(r.text)) # json格式的str转dict
print(type(json.loads(r.text)))

# 查看返回内容,是字典格式才能转json
# html不能转成json
print(r.json()['reason'])
print(r.json()['result']['today']['weather'])

# url编码与解码
from urllib import parse
url = 'http://zzk.cnblogs.com/s/blogpost?Keywords=中文'
a = '中文'
b = parse.quote(a) # 转urlencode编码
print(b)
print(parse.quote(b)) # 转第二次(若有需求)

# 解码
c = '%E4%B8%AD%E6%96%87'
d = parse.unquote(c)
print(d)

# 解码
f = 'http://zzk.cnblogs.com/s/blogpost?Keywords=%E4%B8%AD%E6%96%87'
print(parse.unquote(f))

# 参数关联
import requests
url = "http://v.juhe.cn/weather/index"
par = {
"cityname": "深圳", # 城市名或城市ID,如:"苏州",需要utf8 urlencode
"dtype": "json", # 返回数据格式:json或xml,默认json
"format": "1", # 未来7天预报(future)两种返回格式,1或2,默认1
"key": "80b4d4e1d870d257d3344fcf2d08f64a" # key须申请
}
r = requests.get(url, params=par)
print(r.text) # json格式的str
# 1、requests里面自带解析器转字典
print(r.json())
print(type(r.json()))
# 取出json中的'result_sk_temp'字段
# {"resultcode":"200","reason":"查询成功","result":{"sk":{"temp":"28","wind_direction":"东南风","wind_strength":"2级"
# 参数关联:将result_sk_temp存入变量,下次使用
result = r.json()["result"]['sk']['temp']
url2 = 'xxx?key=%s'%result
body = {
'aa': result
}
r2 = requests.post(url, json=body)

# 正则表达式 一般用于提取数据
import requests
import re
url = 'xxxx'
r = requests.post(url)
# 正则公式:
postid = re.findall(r"(.+?)", r.url) # r.url:匹配的url对象
# ^表示从头开始匹配
u = re.findall(r"^(.+?)\?", url)
# 如果参数在末尾,匹配到最后
# 参数:postid=35454&actiontip=按时发
res = re.findall(r"actiontip=(.+?)$", r.url)
# 知道字符串前、后,取中间,这里的前、后所代表的值须为固定不变的
postid = re.findall(r"前(.+?)后", r.url)
# 参数:postid=35454&actiontip=按时发
# 取:35454 前“postid=” 后“&”
postid = re.findall(r"postid=(.+?)&", r.url)
print(postid) # 这里是list
print(postid[0]) # 提取为字符串

# 参数关联
url1 = 'xxxxx'
body = {'postid': postid}
r1 = requests.post(url, json=body)
# 判断请求是否成功
if r1.json()['xx']:
print('成功')
else:
print('失败')
'''
# 正则提取需要的参数值
import re
postid = re.findall(r"postid=(.+?)&", r2.url)
print postid
# 这里是list
# 提取为字符串
print postid[0]
1.先导入re模块
2.re.findall(匹配规则,查找对象)是查找所有符合规则的
3. postid=(.+?)& 这个意思是查找postid=开头,&结尾的,返回字符串中间内容,如:postid=12345&a=111
那就返回[‘12345’]
4.返回的结果是list
5.list[0]是取下标第一个
'''

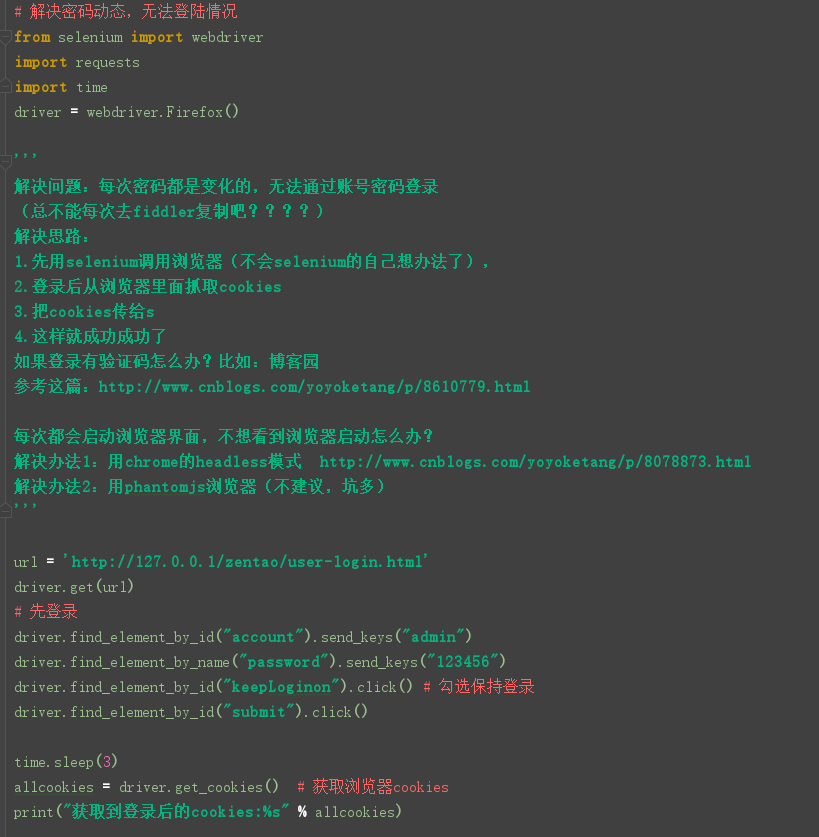
# 解决密码动态,无法登陆情况
from selenium import webdriver
import requests
import time
driver = webdriver.Firefox()
'''
解决问题:每次密码都是变化的,无法通过账号密码登录
(总不能每次去fiddler复制吧????)
解决思路:
1.先用selenium调用浏览器(不会selenium的自己想办法了),
2.登录后从浏览器里面抓取cookies
3.把cookies传给s
4.这样就成功成功了
如果登录有验证码怎么办?比如:博客园
参考这篇:http://www.cnblogs.com/yoyoketang/p/8610779.html
每次都会启动浏览器界面,不想看到浏览器启动怎么办?
解决办法1:用chrome的headless模式 http://www.cnblogs.com/yoyoketang/p/8078873.html
解决办法2:用phantomjs浏览器(不建议,坑多)
'''
url = 'http://127.0.0.1/zentao/user-login.html'
driver.get(url)
# 先登录
driver.find_element_by_id("account").send_keys("admin")
driver.find_element_by_name("password").send_keys("123456")
driver.find_element_by_id("keepLoginon").click() # 勾选保持登录
driver.find_element_by_id("submit").click()
time.sleep(3)
allcookies = driver.get_cookies() # 获取浏览器cookies
print("获取到登录后的cookies:%s" % allcookies)
# 把抓取的cookies添加到s中
s = requests.session()
def add_cookies(allcook):
'''往session添加cookies'''
try:
# 添加cookies到CookieJar
c = requests.cookies.RequestsCookieJar()
for i in allcook:
c.set(i["name"], i['value'])
s.cookies.update(c) # 更新session里cookies
except Exception as msg:
print(u"添加cookies的时候报错了:%s" % str(msg))
# 调用添加cookies函数
add_cookies(allcookies)
print("打印s里面是否添加成功了")
print(s.cookies)
# 访问一个登录之后的页面,看是不是能访问了
r1 = s.get("http://127.0.0.1/zentao/my/")
print(r1.content.decode("utf-8"))