一.背景
目前,越来越多的业务需要进行解耦,逻辑拆分,服务管理,在一个业务流程中,我们可以把业务流程拆分为多个子流程,子流程我可以划分为两大类,同步子流程,异步子流程,同步子流程的运行是串行的,适合依赖上下文的业务场景,异步子流程是并行的,流程和流程之间无依赖,此篇文章我们着重讲一下异步流程的应用。
二.分析需求
- 服务通信通道的选择
常见的服务之间异步通信的方式有redis队列,mysql,rabbitmq,kafka,我们选择了kafka,kafka是一个分布式高可用高吞吐量的消息队列,最初是用来收集日志使用,在互联网场景下,慢慢的也被用来做消息队列,它的完善集群机制能保障数据的安全性,并且kafka有很好的横向伸缩能力,安全的数据持久化方案,所以kafka是我们的最优选择,关于kafka详细的集群原理以及功能,这里不展开阐述,可以自己了解下。 - 业务场景的分析
我们用kafka来连接服务,我们把每个请求变成一条消息,但是我们有很多很多服务,怎么能让服务和服务之间通过kafka高效的进行交互,只是我们要考虑的,有几项指标是我们着重关注的:
①.使用kafka是否会增加业务机器的资源消耗,例如连接,IO,内存,cpu
②.使用kafka是否会带来额外的不可控风险,能否保证数据安全
③.kafka除了连接服务和服务之外,是否有其他场景是我们目前架构所不具备的
④.怎么降低kafka的学习成本和使用成本
⑤.针对消息队列,怎么处理队列阻塞问题
三.解决方案
-
方案设计
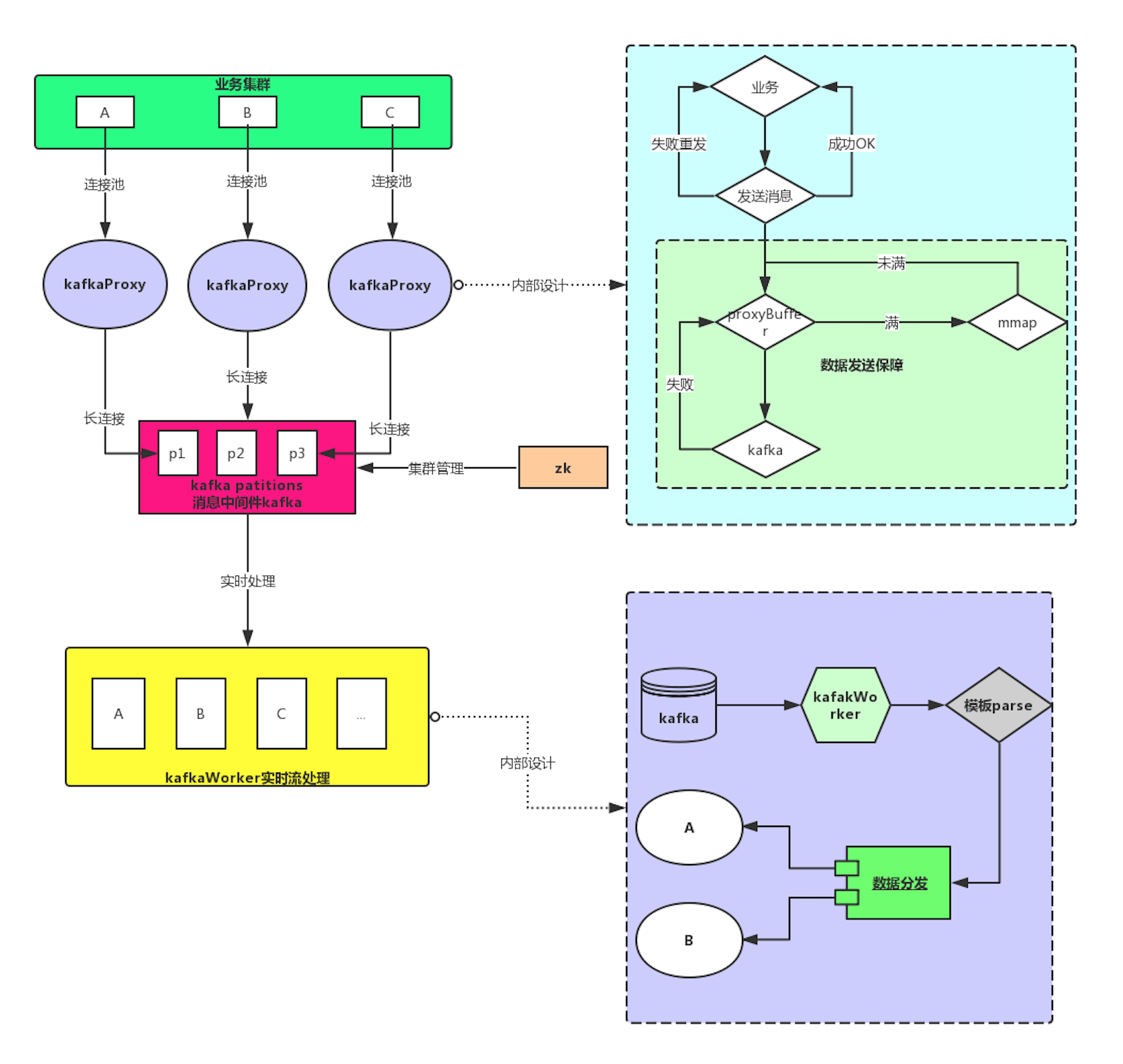
-
方案分析
消息发送我们使用kafkaProxy来做kafka的代理,主要有以下方面考虑:
①.解决了连接消耗大,业务机器资源占用大问题
②.使开发者发kafka消息简单化,不用关注消息是否写到kafka,不用担心消息丢失
③.很好的与业务进行解耦,kafkaProxy发生故障,不会影响其他业务,kafkaProxy也可以集群中心化部署
④.开发者不用关心kafka的集群状态,不用做太多故障处理机制
消息处理我们使用可kafkaWorker来实时处理,主要有以下方面考虑:
①.kafkaWorker使开发者消费kafka消息更简单,简单的配置就能使用
②.kafakWorker和业务深度解耦,插件化模板化管理业务,开发者只需要关心消息处理逻辑即可
③.开发者不用关心kafka的集群状态,不用做太多故障处理机制
④.借助kafka的分布式性能,kafkaWorker也可以灵活的支持了横向伸缩
⑤.kafakWorker针对队列消费阻塞,支持了失败队列的配置,可以设计不同功能kafkaWorker集群