一 慢查询分析
所谓慢查询日志就是系统在命令执行前后计算每条命令的执行时间,当超过预设阈值,就将这条命令的相关信息(例如:发生时间、耗时、命令的详细信息)记录下来。
1.1 生命周期
发送命令-> 命令排队 -> 执行命令 -> 返回结果
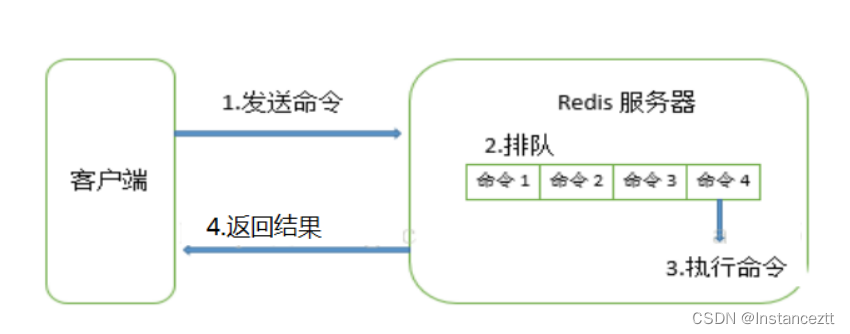
- 慢查询一般发生在第三阶段
- 客户端超时不一定是慢查询,但慢查询是客户端超时的一个可能性因素
1.2 慢查询的两个配置参数
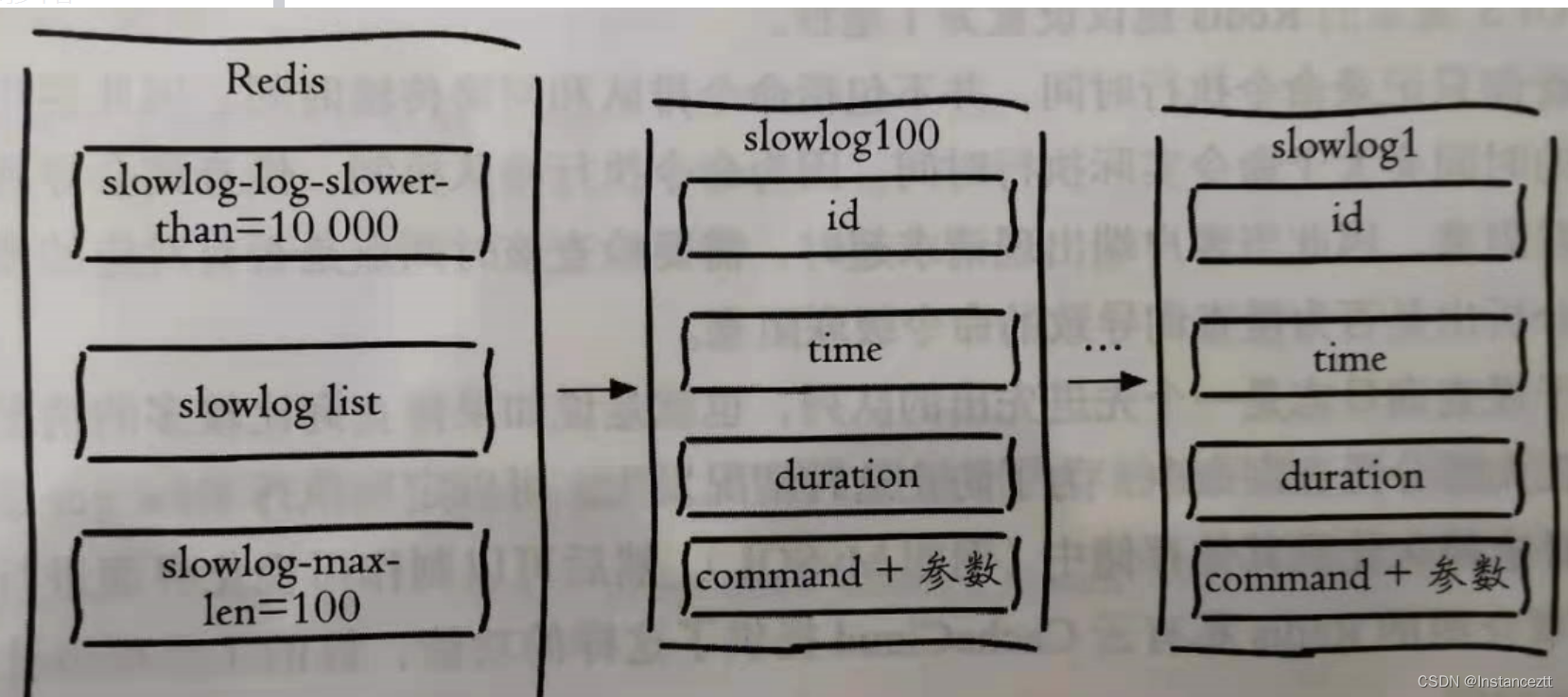
slowlog-max-len: 保存慢查询队列的最大长度,默认值128slowlog-log-slower-than: 慢查询阀值(单位:微秒),表示执行时间大于多少时被记录为慢查询,设为0表示记录所有命令,小于0不记录任何命令,默认值10000(10毫秒)
修改配置的方式:
- 直接修改redis的配置文件
- 直接通过
config set动态修改
config set slowlog-max-len 256
config set slowlog-log-slower-than 1000
1.3 慢查询命令
虽然慢查询日志是存放在 Redis 内存列表中的,但是 Redis 并没有暴露这个列表的键,而是通过一组命令来实现对慢查询日志的访问和管理。
slowlog get [n]: 获取慢查询队列slowlog len: 获取慢查询队列当前长度slowlog reset: 清空慢查询队列
慢查询日志结构
1.4 生产运维
slowlog-log-slower-than 不要设置过大,默认 10ms,通常设置 1msslowlog-max-len 不要设置过小,通常设置 1000 左右- 理解命令的生命周期,
慢查询只记录命令执行时间,并不包括命令排队或网络传输时间 定期持久化慢查询日志,由于慢查询日志是一个先进先出的队列,也就是说如果慢查询比较多的情况下,可能会丢失部分慢查询命令。
二 流水线(pipeline)
Redis 提供了批量操作命令(例如 mget、mset 等),有效地节约 RTT(Round Trip Time,往返时间)。但大部分命令是不支持批量操作的,例如要执行 n 次 hgetall 命令,并没有 mhgetall 命令存在,需要消耗 n 次 RTT。
Pipeline(流水线)机制能改善上面这类问题,它能将一组 Redis 命令进行组装,通过一次 RTT 传输给 Redis,再将这组 Redis 命令的执行结果按顺序返回给客户端。
2.1 流水线的使用
@Autowired
private RedisTemplate redisTemplate;
@GetMapping("/testRedisPipeline")
@Inner(value = false)
public R testRedisPipeline(){
StopWatch stopWatch = StopWatch.create("test:for");
String testKey = "test:for";
stopWatch.start();
for (int i = 0; i< 1000; i++) {
redisTemplate.opsForHash().put(testKey,"filed"+i,"value"+i);
}
stopWatch.stop();
log.info("for循环耗时:{}",stopWatch.getTotalTimeMillis());
StopWatch pipelineStopWatch = StopWatch.create("test:pipeline");
final String pipelineKey = "test:pipeline";
pipelineStopWatch.start();
redisTemplate.executePipelined((RedisCallback<Object>) connection -> {
connection.openPipeline();
for (int i = 0; i< 1000; i++) {
String key = "filed"+i;
String value = "value"+i;
connection.hSet(pipelineKey.getBytes(StandardCharsets.UTF_8),key.getBytes(StandardCharsets.UTF_8),value.getBytes(StandardCharsets.UTF_8));
}
return null;
});
pipelineStopWatch.stop();
log.info("pipeline耗时:{}",pipelineStopWatch.getTotalTimeMillis());
return R.ok();
}
执行结果:
2022-12-08 15:00:05.333 INFO 21320 --- [ XNIO-1 task-1] c.c.c.a.controller.GenTestController : for循环耗时:5884
2022-12-08 15:00:05.416 INFO 21320 --- [ XNIO-1 task-1] c.c.c.a.controller.GenTestController : pipeline耗时:83
2.2 原生批量命令与 Pipeline 对比
- 原生批量命令是原子操作,Pipeline 是非原子操作
- 原生批量命令是一个命令对应多个 key,Pipeline 支持多个命令
- 原生批量命令是 Redis 服务端支持实现的,而 Pipeline 需要服务端和客户端的共同实现
三 redis的事务
3.1 什么是事务
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
Redis 事务可以一次执行多个命令, 并且带有以下三个重要的保证:
- 批量操作在发送 EXEC 命令前被放入
队列缓存。 - 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
- 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:
- 开始事务。
- 命令入队。
- 执行事务。
3.2 事务的原理
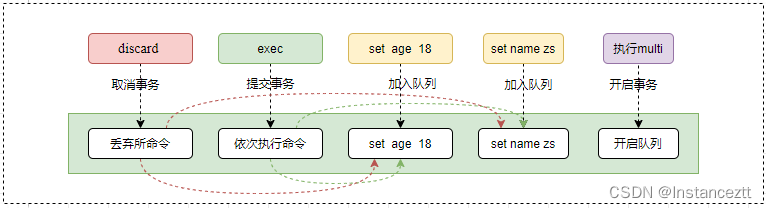
当执行multi命令将会开启事务,那么所有命令就会加入事务队列暂存,不会真正的直接执行,如果遇到exec就会把队列中的命令依次执行-提交事务,需要注意的是即使有的命令执行失败了,也不会影响其他命令的执行结果-不回滚,但是如果遇到discard就会放弃执行队列中的命令-取消事务 , 如下:
3.3 事务操作
multi: 标记一个事务块的开始。
multi #开启事务
set name zs #添加字符串值
set age 18 #添加数字值
incr name #name的值+1
incr age #age的值+1
exec: 执行所有事务块内的命令
exec #提交事务,开启 multi 后的所有命令将被执行,如果有命令失败了也不会回滚成功的命令依然成功
#incr name命令会执行失败因为字符串是不能+1的,incr age命令会执行成功,age的值是数字能+1
get name #返回zs
get age #返回19
discard:取消事务,如果在开启multi后选择执行discard命令,将会 放弃执行事务块内的所有命令。
discard #取消事务,开启multi后的所有命令将取消执行
get name #会返回空值
get age #会返回空值
四 位图(BitMaps)
Redis 提供了 Bitmaps 这个“数据结构”可以实现对位的操作。
数据结构模型:
本身不是一种数据结构,实际上它就是字符串,但是它可以对字符串的位进行操作- BitMaps 单独提供了一套命令,所以在 Redis 中使用 BitMaps 和使用字符串的方法不太相同。
API
setbit key offset value:给位图指定索引设置值,第 offset 位设置成 value,value 只能是 0 或 1getbit key offset:获取某一位的值bitcount key [start end]:获取位图指定范围(start 到 end,单位为字节,不指定表示获取所有)位值为1的个数bitop op destkey key [key...]:做多个 Bitmap 的 and(交集),or(并集),not(非),xor(异或)操作,并将结果保存到 - destkey 中bitops key targetBit [start] [end]:计算位图指定范围(start 到 end,单位为字节,如果不指定就是获取全部)第一个偏移量对应的值等于 targetBit 的位置。
五 Hyperloglog
数据结构模型
并不是一种新的数据结构,实际类型也是字符串类型,而是一种基数算法,通过 Hyperloglog 可以利用极小的内存空间完成独立总数的统计,数据集可以是 IP、Email、ID 等。
API
pfadd key element [element ...]:向 Hyperloglog 添加元素pfcount key [key ...]:计算 Hyperloglog 的独立总数pfmerge destkey sourcekey [sourcekey ...]:合并多个 Hyperloglog
使用经验
- 是否能够容忍错误?Redis 官方给出的数字是 0.81% 的失误率
- 是否需要单条语句?这里是无法取出单条语句
- 使用场景可以是统计一些用户数,而且可以接受一个很小的误差
六 发布/订阅
6.1 什么是发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。Redis 客户端可以订阅任意数量的频道。没订阅的接收者当然是接收不到消息的,(pub/sub)是一种广播模式,及会把消息发送给所有的订阅者
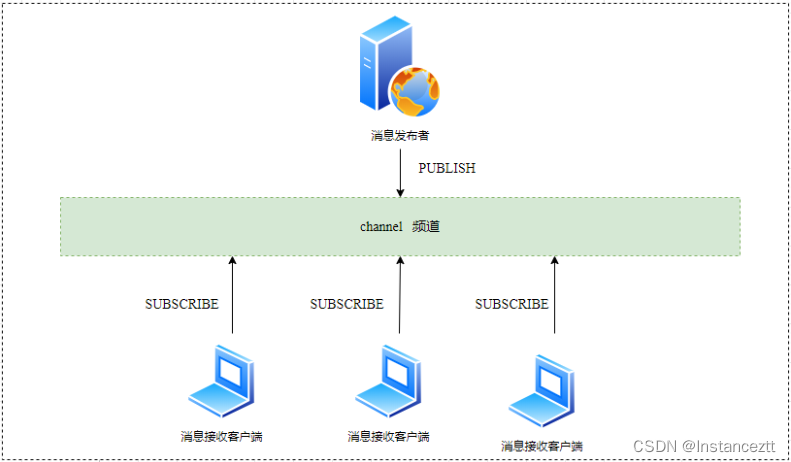
消息接收者通过 SUBSCRIBE channel 命令订阅某个频道 , 消息发布者通过 PUBLISH channel message 向该频道发布消息,那么订阅了该频道的所有接收者就可以收到消息。
6.2 API
publish channel message:向 channel 频道发布 message 消息,返回结果是订阅者数subscribe [channel]:可订阅一个或多个频道unsubscribe [channel]:取消订阅psubscribe [pattern...]:订阅模式punsubscribe [pattern...]:退订指定的模式pubsub channels:列出至少有一个订阅者的频道pubsub numsub [channel...]:列出给定频道的订阅者数量pubsub numpat:列出被订阅模式的数量
七 GEO(地理信息定位)
Redis 提供的 GEO 功能,支持存储地理位置信息用来实现诸如附近位置、摇一摇这类依赖于地理位置信息的功能。
geoadd key lng lat member [lng lat member ...]:增加地理位置信息geopos key member [member ...]:获取地理位置信息geodist key member1 member2 [unit]:获取两个地理位置的距离,unit:m(米),km(千米),mi(英里),ft(尺)georadius:获取地理位置信息