依赖库
OpenCL是一套标准,由Khronos Group管理,Khronos在github上有一个仓库,另外各个硬件厂家也都有自己的实现。
KhronosGroup
github地址:https://github.com/KhronosGroup/OpenCL-SDK
点击页面右侧的Releases,根据自己的环境进行下载。
可以下载编译好的压缩包,比如:OpenCL-SDK-v2022.09.30-Win-x64.zip
解压后可以看到bin,include,lib等文件夹,这些是主要要用的,习惯上我会把最外层文件夹名字后缀全部干掉,只留下OpenCL。
Nvidia
Nvidia的OpenCL库在装Cuda的时候会顺带装上,需要去Cuda安装目录里面扒出来。
Cuda下载:https://developer.nvidia.com/cuda-downloads
官方Demo:https://developer.nvidia.com/opencl
安装之后去下面目录中把CL文件夹拷贝出来:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\include
然后去下面两个文件夹中把OpenCL.lib拷贝出来:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\lib\Win32
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\lib\x64
最后形成这样一个文件夹结构:
- OpenCL
- include
- CL:一堆头文件
- lib
- Win32:OpenCL.lib
- x64:OpenCL.lib
- include
Intel
Intel比较坑,需要下载sdk并安装,但是下载sdk的过程必须要求注册。
Intel OpenCL sdk下载:https://software.intel.com/en-us/intel-opencl/download
安装后的sdk的路径为:
C:\Program Files (x86)\IntelSWTools\system_studio_2020\OpenCL\sdk
这个路径下有include和lib,拷贝出来形成与上述相同的文件夹结构。
在Visual Studio中配置依赖库
下面以KhronosGroup的SDK为例。
创建一个新的VS空项目,平台改成x64,然后把OpenCL依赖库拷贝进去。
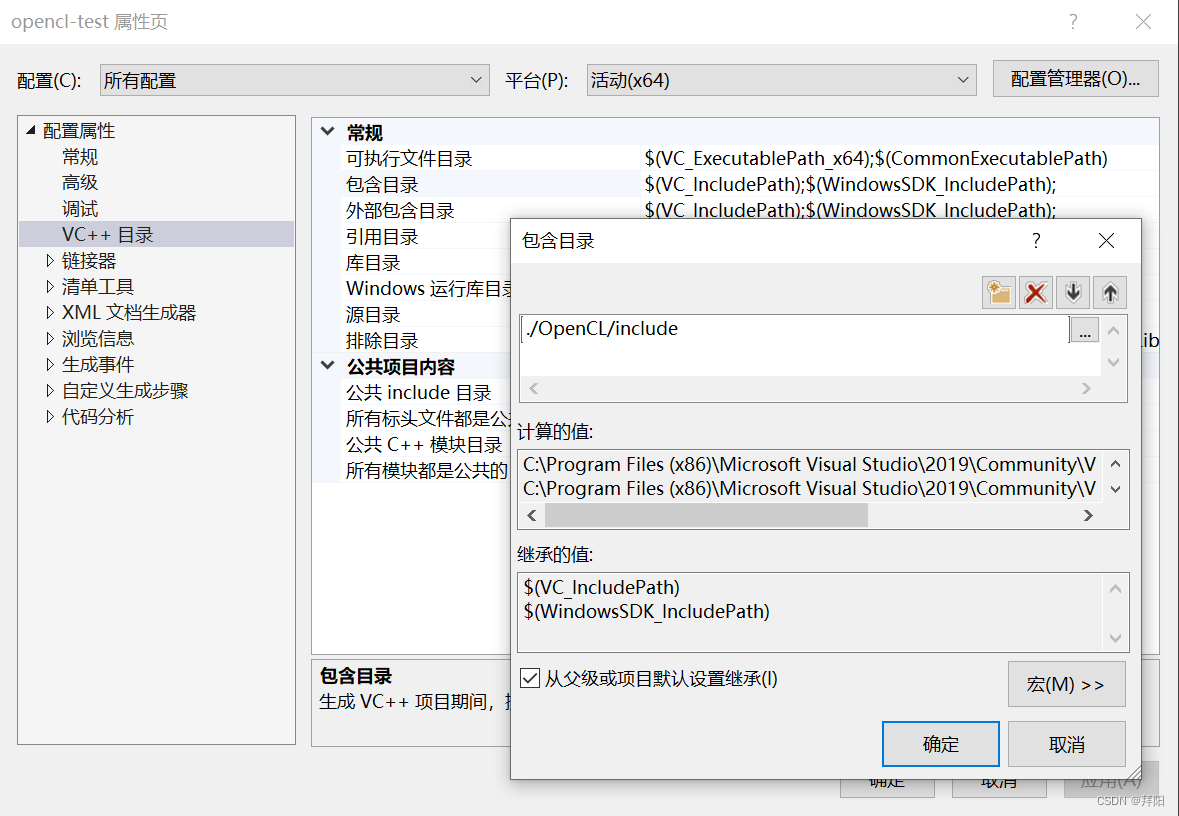
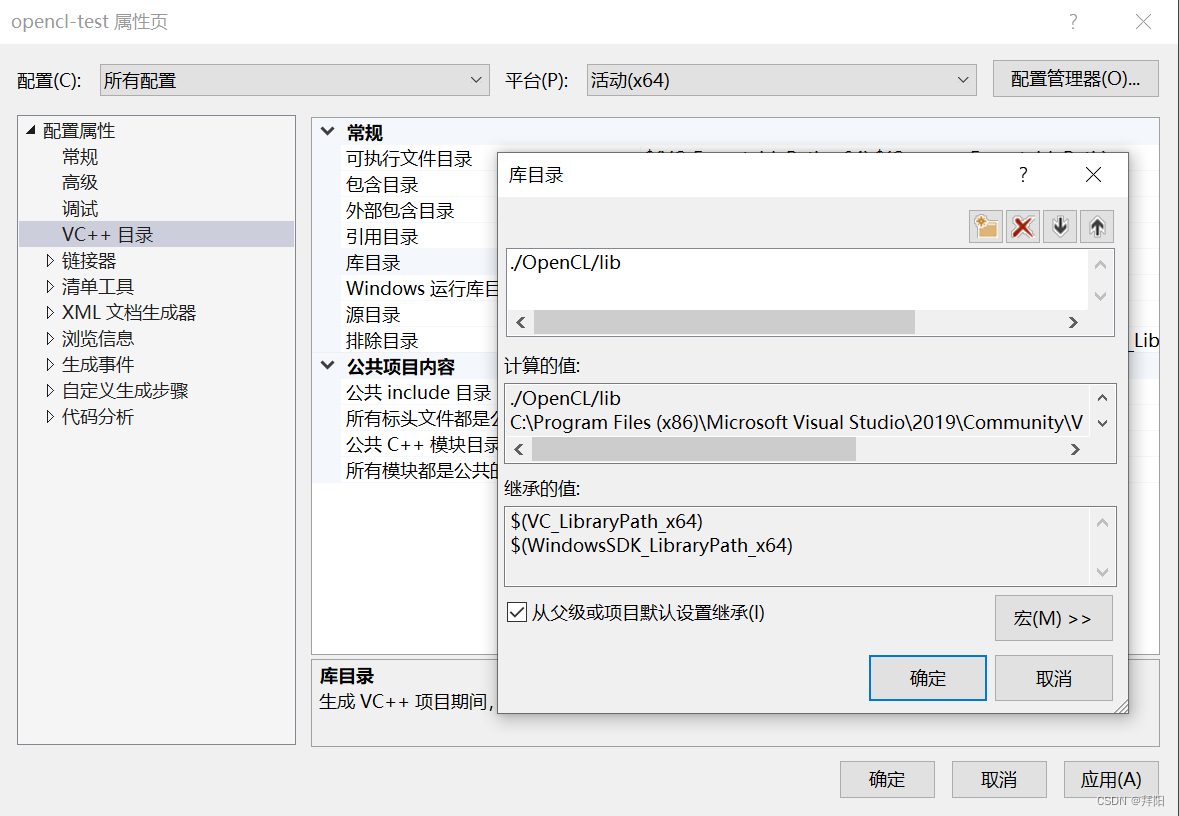
配置include和lib目录
右键点击项目 - 属性,按如下方式配置include和lib路径。
请注意配置成相对路径,这样把工程拷贝给别人后,别人不需要更改直接就可以运行,下同。
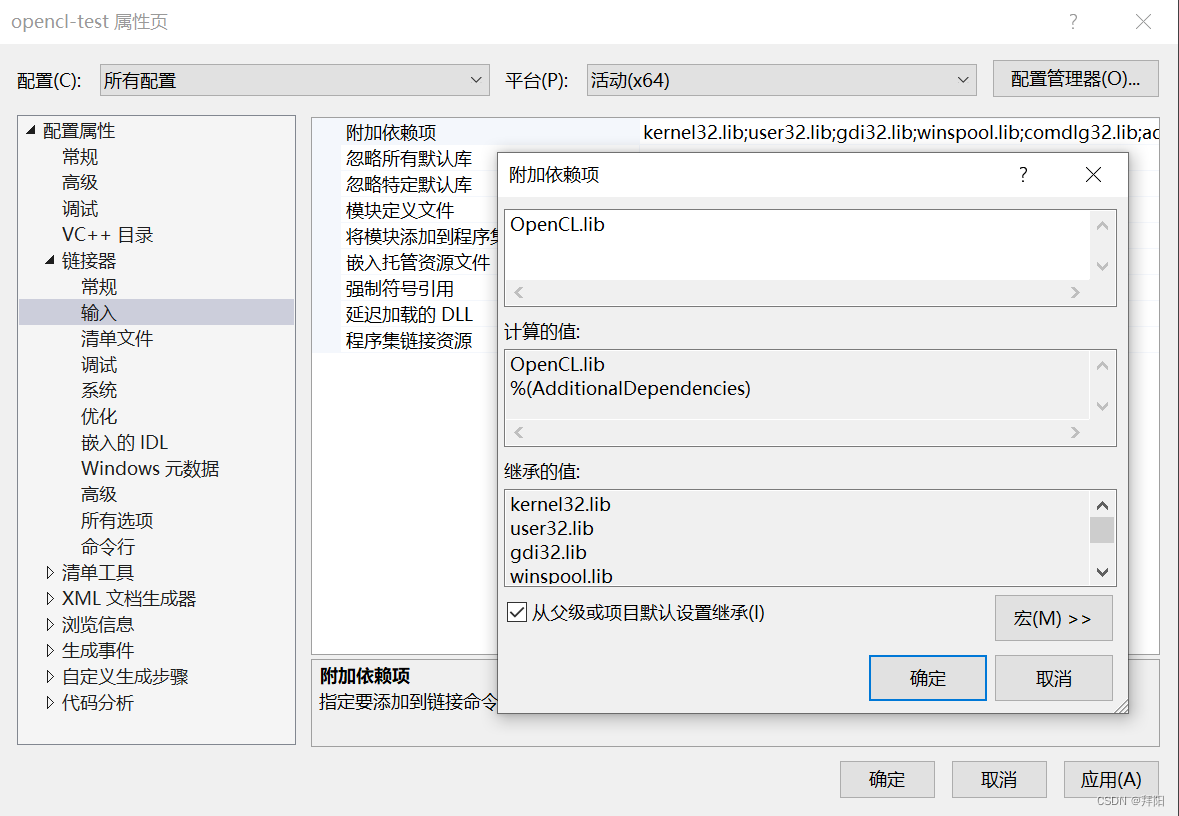
配置附加依赖项
点击链接器 - 输入 - 附加依赖项,把OpenCL.lib写进去。
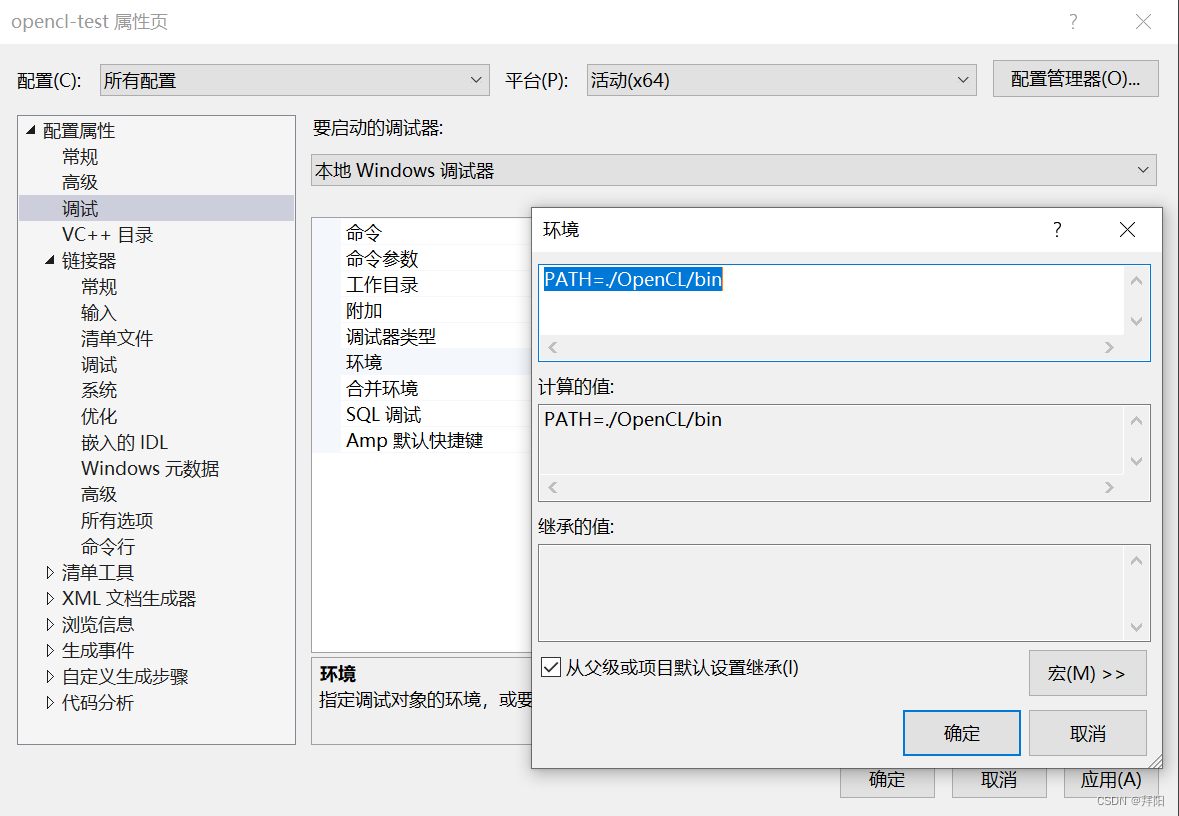
配置dll目录(可选)
在调试 - 环境中配置dll路径,注意这时候路径前面要写PATH=。
这一步常常是可选的,为什么呢?因为如果安装过cuda或者其他类似驱动的话,Windows\System32文件夹下常常已经有OpenCL.dll了,这个系统文件夹下的dll可以默认被调用到,所以不用配置也可以使用。(不过System32文件夹下的dll和KhronosGroup的dll不是一套代码编译出来的,可能会存在接口不一致情况。)
测试代码
入门可以找一些公开的代码库学习一下,比如Nvidia的Samples:https://developer.nvidia.com/opencl
但是Nvidia自己搞了一些公用库,并且有些工程项目使用了非常老的vs版本(vs08,vs10之类),不太好配。
因此下面以其中一个DotProduct为例,把代码重新梳理了一下,把下面的两个文件main.cpp和dot_product.cl放入工程目录下,并把main.cpp添加到工程源文件中,即可点F5执行测试。
dot_product.cl是kernel文件,内容是Nvidia sample里面贴过来的,一点没改。注意文件名不要改,因为主程序要通过文件名去找kernel文件。
main.cpp
#include <CL/opencl.h>
#include <iostream>
#include <string>
#include <fstream>
#include <ctime>
void CheckErrorCode(cl_int error_code, cl_int reference, std::string function_name, int return_code);
template<typename T> T RoundUp(T group_size, T global_size);
void FillArray(float* data, size_t size);
std::string ReadFile(const std::string& filaname);
void DotProductHost(const float* a, const float* b, float* result, size_t array_size);
int CompareResult(const float* reference, const float* data, size_t array_size, const float epsilon);
int main()
{
// common variables
cl_int error_code;
size_t array_size = 9992222; // Length of float arrays to process
std::string kernel_souce_file = "dot_product.cl";
// Get the NVIDIA platform
std::string platform_name_keyword = "NVIDIA";
cl_platform_id platform = nullptr; // output of this block
cl_uint num_platforms;
error_code = clGetPlatformIDs(0, NULL, &num_platforms);
CheckErrorCode(error_code, CL_SUCCESS, "clGetPlatformIDs", -11);
if (num_platforms == 0) {
std::cout << "No OpenCL platform found!" << std::endl;
return -12;
} else {
// if there's a platform or more, make space for ID's
cl_platform_id* platforms = nullptr;
platforms = (cl_platform_id*)malloc(num_platforms * sizeof(cl_platform_id));
if (platforms == nullptr) {
std::cout << "Failed to allocate memory for cl_platform ID's!" << std::endl;
return -13;
}
error_code = clGetPlatformIDs(num_platforms, platforms, NULL);
CheckErrorCode(error_code, CL_SUCCESS, "clGetPlatformIDs", -14);
char info_buffer[1024] = {
0 };
for (cl_uint i = 0; i < num_platforms; ++i) {
error_code = clGetPlatformInfo(platforms[i], CL_PLATFORM_NAME, sizeof(info_buffer), &info_buffer, NULL);
CheckErrorCode(error_code, CL_SUCCESS, "clGetPlatformInfo", -15);
std::string platform_name = info_buffer;
if (platform_name.find(platform_name_keyword) != std::string::npos) {
platform = platforms[i];
break;
}
}
if (platform == nullptr) {
std::cout << "WARNING: " << platform_name_keyword <<
" OpenCL platform not found - defaulting to first platform!" << std::endl;
platform = platforms[0];
}
free(platforms);
platforms = nullptr;
}
// Get device
cl_device_id device = nullptr; // output of this block
cl_uint num_devices = 0; // Number of devices available
cl_uint target_device_id = 0; // Default Device to compute on
cl_uint num_compute_units = 0; // Number of compute units (SM's on NV GPU)
error_code = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 0, NULL, &num_devices);
CheckErrorCode(error_code, CL_SUCCESS, "clGetDeviceIDs", -21);
if (num_devices == 0) {
std::cout << "No OpenCL devices found!" << std::endl;
return -22;
} else {
// if there's a device or more, make space for ID's
cl_device_id* devices = nullptr;
devices = (cl_device_id*)malloc(num_devices * sizeof(cl_device_id));
if (devices == nullptr) {
std::cout << "Failed to allocate memory for cl_device ID's!" << std::endl;
return -23;
}
// clamp target_device_id
target_device_id = std::min(std::max(target_device_id, static_cast<cl_uint>(0)), num_devices - 1);
// select device
error_code = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, num_devices, devices, NULL);
CheckErrorCode(error_code, CL_SUCCESS, "clGetDeviceIDs", -24);
device = devices[target_device_id];
// print device info
char info_buffer[1024] = {
0 };
error_code = clGetDeviceInfo(device, CL_DEVICE_NAME, sizeof(info_buffer), &info_buffer, NULL);
CheckErrorCode(error_code, CL_SUCCESS, "clGetDeviceInfo", -25);
std::cout << "Using GPU device: " << info_buffer << std::endl;
// get and print number of compute units
error_code = clGetDeviceInfo(device, CL_DEVICE_MAX_COMPUTE_UNITS, sizeof(num_compute_units), &num_compute_units, NULL);
CheckErrorCode(error_code, CL_SUCCESS, "clGetDeviceInfo", -26);
std::cout << "Compute Units: " << num_compute_units << std::endl;
free(devices);
devices = nullptr;
}
// Set local and global work size
size_t local_work_size = 256;
size_t global_work_size = RoundUp(local_work_size, array_size);
std::cout << "array_size: " << array_size << std::endl;
std::cout << "local work size: " << local_work_size << std::endl;
std::cout << "global_work_size:" << global_work_size << std::endl;
// Create the context
cl_context gpu_context = nullptr;
gpu_context = clCreateContext(0, 1, &device, NULL, NULL, &error_code);
CheckErrorCode(error_code, CL_SUCCESS, "clCreateContext", -31);
// Create a command-queue
std::cout << "clCreateCommandQueue..." << std::endl;
cl_command_queue command_queue = nullptr;
//command_queue = clCreateCommandQueue(gpu_context, device, 0, &error_code); // clCreateCommandQueue is deprecated after CL1.2
command_queue = clCreateCommandQueueWithProperties(gpu_context, device, 0, &error_code);
CheckErrorCode(error_code, CL_SUCCESS, "clCreateCommandQueue", -41);
// Read the OpenCL kernel in from source file
std::cout << "oclLoadProgSource " << kernel_souce_file << "..." << std::endl;
std::string kernel_source = ReadFile(kernel_souce_file);
CheckErrorCode(kernel_source != "", true, "Read kernel source file", -61);
size_t kernel_length = kernel_source.size();
const char* kernel_souce_cstr = kernel_source.c_str();
// Create the program
std::cout << "clCreateProgramWithSource..." << std::endl;
cl_program program = nullptr;
program = clCreateProgramWithSource(gpu_context, 1, (const char**)&kernel_souce_cstr, &kernel_length, &error_code);
CheckErrorCode(error_code, CL_SUCCESS, "clCreateProgramWithSource", -62);
error_code = clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
CheckErrorCode(error_code, CL_SUCCESS, "clBuildProgram", -63);
// Create the kernel
std::cout << "clCreateKernel (dot_product)..." << std::endl;
cl_kernel kernel = nullptr;
kernel = clCreateKernel(program, "DotProduct", &error_code); // kernel_name (2nd param) should be same as the function name in kernel source file
CheckErrorCode(error_code, CL_SUCCESS, "clCreateKernel", -64);
// Allocate and initialize host arrays
std::cout << "Allocate and Init Host Mem..." << std::endl;
void* src_a;
void* src_b;
void* dst;
void* golden;
src_a = (void*)malloc(sizeof(cl_float4) * global_work_size);
src_b = (void*)malloc(sizeof(cl_float4) * global_work_size);
dst = (void*)malloc(sizeof(cl_float) * global_work_size);
golden = (void*)malloc(sizeof(cl_float) * array_size);
FillArray(static_cast<float*>(src_a), 4 * array_size);
FillArray(static_cast<float*>(src_b), 4 * array_size);
// Allocate the OpenCL buffer memory objects for source and result on the device GMEM
std::cout << "clCreateBuffer on the Device GMEM..." << std::endl;
cl_mem device_src_a = nullptr;
cl_mem device_src_b = nullptr;
cl_mem device_dst = nullptr;
device_src_a = clCreateBuffer(gpu_context, CL_MEM_READ_ONLY, sizeof(cl_float) * global_work_size * 4, NULL, &error_code);
CheckErrorCode(error_code, CL_SUCCESS, "clCreateBuffer", -51);
device_src_b = clCreateBuffer(gpu_context, CL_MEM_READ_ONLY, sizeof(cl_float) * global_work_size * 4, NULL, &error_code);
CheckErrorCode(error_code, CL_SUCCESS, "clCreateBuffer", -52);
device_dst = clCreateBuffer(gpu_context, CL_MEM_READ_ONLY, sizeof(cl_float) * global_work_size, NULL, &error_code);
CheckErrorCode(error_code, CL_SUCCESS, "clCreateBuffer", -53);
// Set the Argument values
std::cout << "clSetKernelArg 0 - 3..." << std::endl;
error_code = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void*)&device_src_a);
error_code |= clSetKernelArg(kernel, 1, sizeof(cl_mem), (void*)&device_src_b);
error_code |= clSetKernelArg(kernel, 2, sizeof(cl_mem), (void*)&device_dst);
error_code |= clSetKernelArg(kernel, 3, sizeof(cl_int), (void*)&array_size);
CheckErrorCode(error_code, CL_SUCCESS, "clSetKernelArg", -65);
// Asynchronous write of data to GPU device
std::cout << "clEnqueueWriteBuffer (src_a and src_b)..." << std::endl;
error_code = clEnqueueWriteBuffer(command_queue, device_src_a, CL_FALSE, 0, sizeof(cl_float) * global_work_size * 4, src_a, 0, NULL, NULL);
error_code |= clEnqueueWriteBuffer(command_queue, device_src_b, CL_FALSE, 0, sizeof(cl_float) * global_work_size * 4, src_b, 0, NULL, NULL);
CheckErrorCode(error_code, CL_SUCCESS, "clEnqueueWriteBuffer", -66);
// Launch kernel
clock_t device_time_beg;
clock_t device_time_end;
std::cout << "clEnqueueNDRangeKernel (DotProduct)..." << std::endl;
device_time_beg = clock();
error_code = clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL, &global_work_size, &local_work_size, 0, NULL, NULL);
device_time_end = clock();
float device_time_cost = (float)(device_time_end - device_time_beg);
CheckErrorCode(error_code, CL_SUCCESS, "clEnqueueNDRangeKernel", -71);
// Read back results and check accumulated errors
std::cout << "clEnqueueReadBuffer (dst)..." << std::endl;
error_code = clEnqueueReadBuffer(command_queue, device_dst, CL_TRUE, 0, sizeof(cl_float) * global_work_size, dst, 0, NULL, NULL);
CheckErrorCode(error_code, CL_SUCCESS, "clSetKernelArg", -81);
// Compute and compare results for golden-host and report errors and pass/fail
std::cout << "Comparing against Host/C++ computation..." << std::endl;
clock_t host_time_beg;
clock_t host_time_end;
host_time_beg = clock();
DotProductHost((const float*)src_a, (const float*)src_b, (float*)golden, array_size);
host_time_end = clock();
float host_time_cost = (float)(host_time_end - host_time_beg);
int error_count = CompareResult((const float*)golden, (const float*)dst, array_size, 0.000001f);
std::cout << "error value count: " << error_count << std::endl;
// Print time cost for host and device
std::cout << "Host time cost (ms): " << host_time_cost << std::endl;
std::cout << "Device time cost (ms):" << device_time_cost << std::endl;
// Release and clean
free(src_a);
free(src_b);
free(dst);
free(golden);
src_a = nullptr;
src_b = nullptr;
dst = nullptr;
golden = nullptr;
kernel_souce_cstr = nullptr;
if (gpu_context != nullptr) {
clReleaseContext(gpu_context);
gpu_context = nullptr;
}
if (command_queue != nullptr) {
clReleaseCommandQueue(command_queue);
command_queue = nullptr;
}
if (program != nullptr) {
clReleaseProgram(program);
program = nullptr;
}
if (kernel != nullptr) {
clReleaseKernel(kernel);
kernel = nullptr;
}
if (device_src_a != nullptr) {
clReleaseMemObject(device_src_a);
device_src_a = nullptr;
}
if (device_src_b != nullptr) {
clReleaseMemObject(device_src_b);
device_src_b = nullptr;
}
if (device_dst != nullptr) {
clReleaseMemObject(device_dst);
device_dst = nullptr;
}
return 0;
}
void CheckErrorCode(cl_int error_code, cl_int reference, std::string function_name, int return_code)
{
if (error_code != reference) {
std::cout << "Error in " << function_name << " Call, error code = " << error_code << std::endl;
exit(return_code);
}
return;
}
template<typename T>
T RoundUp(T group_size, T global_size)
{
T r = global_size % group_size;
if (r == 0) {
return global_size;
} else {
return global_size + group_size - r;
}
}
void FillArray(float* data, size_t size)
{
const float scale = 1.0f / static_cast<float>(RAND_MAX);
for (size_t i = 0; i < size; ++i) {
data[i] = scale * rand();
}
}
std::string ReadFile(const std::string& filaname)
{
std::string filestring;
std::fstream ifs;
ifs.open(filaname, std::ios::in);
if (ifs) {
std::istreambuf_iterator<char> begin(ifs);
std::istreambuf_iterator<char> end;
filestring = std::string(begin, end);
}
ifs.close();
return filestring;
}
void DotProductHost(const float* a, const float* b, float* result, size_t array_size)
{
for (size_t i = 0; i < array_size; i++) {
result[i] = 0.0f;
for (size_t j = 0; j < 4; j++) {
size_t k = i * 4 + j;
result[i] += a[k] * b[k];
}
}
}
int CompareResult(const float* reference, const float* data, size_t array_size, const float epsilon)
{
int error_count = 0;
float diff;
for (size_t i = 0; i < array_size; ++i) {
diff = fabs(reference[i] - data[i]);
if (diff > epsilon) {
++error_count;
}
}
return error_count;
}
dot_product.cl
/*
* Copyright 1993-2010 NVIDIA Corporation. All rights reserved.
*
* Please refer to the NVIDIA end user license agreement (EULA) associated
* with this source code for terms and conditions that govern your use of
* this software. Any use, reproduction, disclosure, or distribution of
* this software and related documentation outside the terms of the EULA
* is strictly prohibited.
*
*/
__kernel void DotProduct (__global float* a, __global float* b, __global float* c, int iNumElements)
{
// find position in global arrays
int iGID = get_global_id(0);
// bound check (equivalent to the limit on a 'for' loop for standard/serial C code
if (iGID >= iNumElements)
{
return;
}
// process
int iInOffset = iGID << 2;
c[iGID] = a[iInOffset] * b[iInOffset]
+ a[iInOffset + 1] * b[iInOffset + 1]
+ a[iInOffset + 2] * b[iInOffset + 2]
+ a[iInOffset + 3] * b[iInOffset + 3];
}