原理篇
GC是用来管理堆内存的,我们将堆抽象为下图的表示:

GC标记清除算法有两个阶段:
- 标记阶段:把所有活动对象做上标记
- 清除阶段:回收没有被标记的对象,也就是非活动对象
在GC标记清除算法中,任何不能直接或间接被根节点引用的对象都被视为非活动对象,是可被回收的垃圾。伪代码:
mark_sweep() {
mark_phase() //标记
sweep_phase() //清除
}
如下图所示为执行GC前堆的状态。

可以看到,从根出发,所有活动对象构成的数据结构是一颗多叉树。标记阶段就是遍历这颗树,给每个节点打上"存活"标记。伪代码表示如下。
mark_phase() {
//$roots表示根节点指向的节点数组
for(r : $roots)
mark(*r)
}
mark(obj) {
if(obj.mark == FALSE) //未标记过
obj.mark = TRUE //标记存活
//children函数用来获取对象obj的子节点数组
for(child : children(obj)) //遍历子对象
mark(*child) //递归标记子对象
}
在本文的伪代码中,
$开头的变量表示全局变量。
标记代码是一个简单的树的先序遍历,标记执行完以后,堆的状态如下图所示。
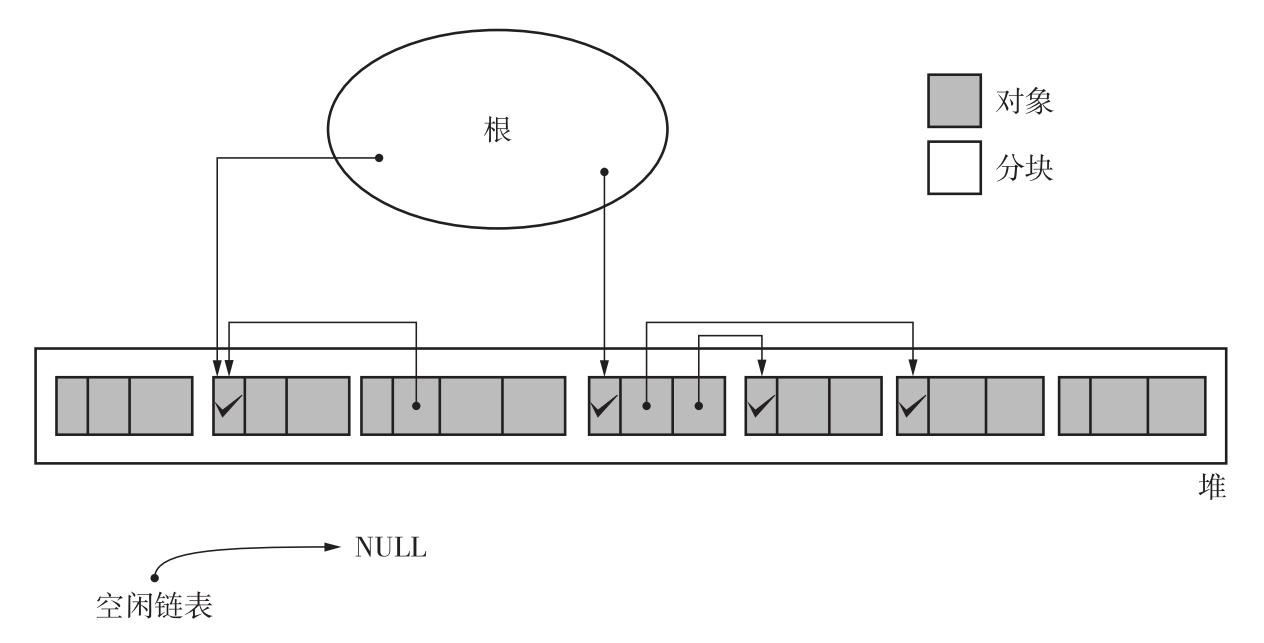
标记阶段会遍历所有活动对象,因此,标记阶段耗时与活动对象数成正比。
清除阶段需要遍历整个堆,遍历过程中会完成两件事:
- 将非活动对象回收
- 清除活动对象的标记,为下次GC做准备
伪代码如下:
sweep_phase() {
sweeping = $heap_start //从堆头开始
while(sweeping < $heap_end) //遍历堆
if(sweeping.mark == TRUE) //如果是活动对象
sweeping.mark = FALSE //清除标记
else
sweeping.next = $free_list //$free_list表示空闲链表
$free_list = sweeping //头插法将非活动对象插入空闲链表
sweeping += sweeping.size //下一个对象
}
我们通过sweeping从堆的头部开始遍历堆内对象,并通过头插法将非活动对象加入空闲链表。空闲链表的数据结构是单链表,头插法效率更高。垃圾回收中的回收就是指将非活动对象添加到空闲链表。
清除阶段执行完以后,堆的状态如下图所示。
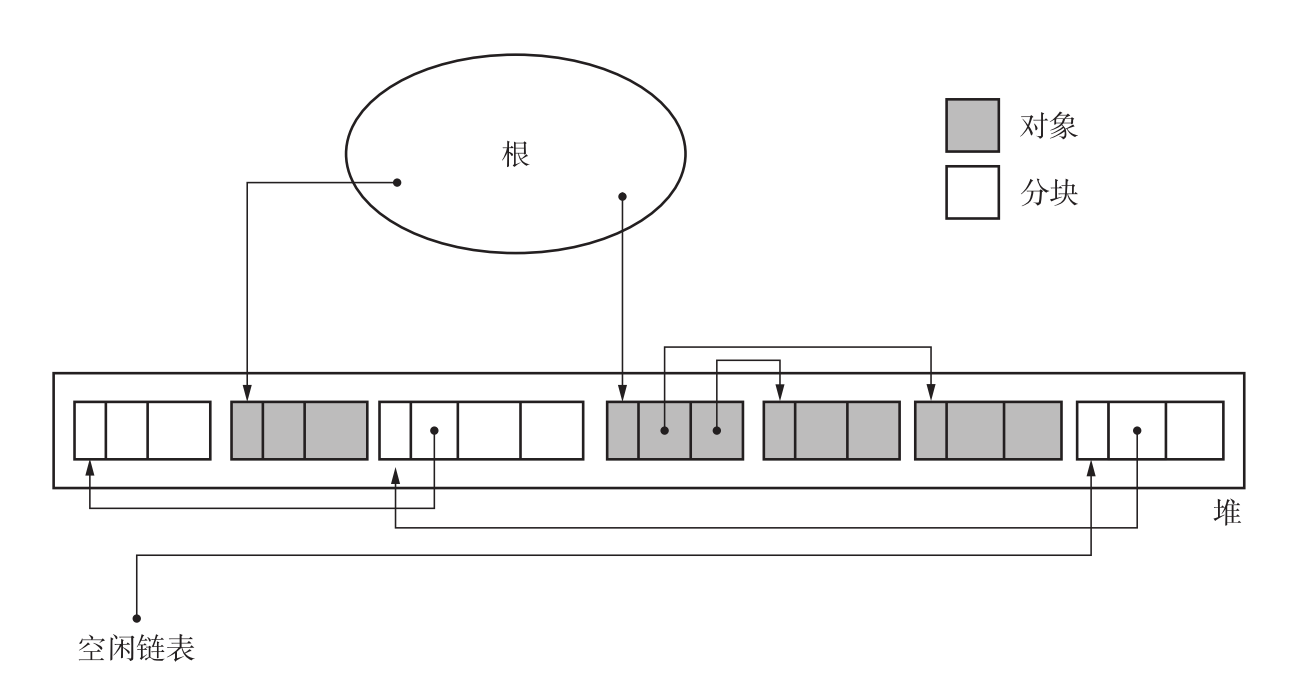
因为清除阶段会遍历整个堆,因此清除阶段耗时与堆大小成正比。
内存管理除了回收还有分配。分配操作就是遍历空闲链表中找到大小合适的对象,伪代码如下:
new_obj(size) {
//遍历空闲链表寻找大小合适的分块
chunk = pickup_chunk(size, $free_list)
if(chunk != NULL) //分配成功
return chunk
else
allocation_fail() //分配失败
}
pickup_chunk函数会遍历空闲链表并寻找大于等于size的对象。如果对象大小等于size则直接返回;如果对象大小大于size,则从对象中切分出size大小的对象返回,剩余部分依然放在空闲链表中。如果所有对象都小于size,则返回失败。
如何寻找合适大小的空闲分块有三种策略:
- First-fit:找到第一个大于等于
size的分块就立刻返回 - Best-fit:遍历完空闲链表,找到大于等于
size的最小分块 - Worst-fit:找到空闲链表中最大的分块,切出
size大小,目的是使得剩下的分块大小最大化
Worst-fit一般不推荐使用,考虑到分配时间,一般选择First-fit。
关于分块和对象这两个词语,活动对象用"对象"这个词,空闲列表中的对象就用"分块"这个词。
随着分配的进行,会产生很多小分块,在清除阶段可以将连续的分块合并成一个大分块。伪代码如下:
sweep_phase() {
sweeping = $heap_start //从堆头开始
while(sweeping < $heap_end) //遍历堆
if(sweeping.mark == TRUE) //如果是活动对象
sweeping.mark = FALSE //清除标记
else
if(sweeping == $free_list + $free_list.size) //连续分块
$free_list.size += sweeping.size //合并分块
else //不是连续分块
sweeping.next = $free_list //头插法加入空闲链表
$free_list = sweeping
sweeping += sweeping.size //下一个对象
}
注意到清除阶段是从低地址向高地址遍历堆的,连续分块的堆状态如下图。

GC标记清除算法的优点有两个:
- 实现简单,与其他算法组合也简单
- 与保守式GC算法兼容,因为他们都不需要移动对象。
GC标记清除算法的缺点也很明显。
第一点是碎片化。简单来说就是随着分配和回收的进行会产生很多小的空闲对象散落在堆中,彼此也不连续。碎片化带来的问题是无法分配大的空闲空间,尽管总的空闲空间是够用的,比如下图这种情况。碎片化带来的另一个问题是局部性原理失效,因为具有引用关系的数据分配到的空闲空间并不连续。

第二个问题是分配速度慢。因为空闲链表是单链表结构,分配时需要遍历链表,时间复杂度是O(n)。
第三个问题是与写时复制不兼容。因为标记阶段会修改堆内对象,导致大量拷贝。
写时复制是指多个调用者访问同一份资源时,如果只是读取并不会将资源复制多份,只有当某个调用者尝试写入时,才会给它复制一份资源副本。例如复制进程时,并不会复制内存空间,只有当进程尝试写入内存时,才会复制一份内存空间。
写时复制的例子在生活中也很常见。比如你上课忘带课本,可以和同桌共用一本课本,但是当要在课本上做笔记时,你就要把同桌的课本复印一份了。再比如领导共享的汇报模板,参考时大家打开的是同一份文件,当你想修改时,就要复制一份再修改。
优化篇
多空闲链表
在之前的算法中,我们只用了一个链表来管理所有的分块,需要O(n)的时间来寻找合适的分块,有没有什么办法能在O(1)的时间完成呢?答案就是哈希表。
我们用数组模拟哈希表,数组的每一项是一个空闲链表,空闲链表中每个分块的大小都是该空闲链表在数组中的下标。如下图所示。

空闲链表数组不可能无限长,因此需要规定一个上限,大于该上限的分块统一用一个链表管理,也就是退化成单链表。考虑到现实情况是分配小对象的时候要远远多于分配大对象,这样的设计也是合理的。
新的结构需要有新的分配算法和清除算法,伪代码如下:
//分配算法
new_obj(size) {
//计算所需大小在空闲链表数组的下标
index = size / (WORD_LENGTH / BYTE_LENGTH)
if(index <= 100) //假定上限为100
if($free_list[index] != NULL) //该空闲链表不为空,说明还有空闲空间
chunk = $free_list[index] //分配空闲链表头节点
$free_list[index] = $free_list[index].next //删除空闲链表头节点
return chunk //分配成功
else
chunk = pickup_chunk(size, $free_list[101]) //退化成单链表
if(chunk != NULL) //分配成功
return chunk
allocation_fail() //分配失败
}
//清除算法
sweep_phase() {
for(i : 2..101)
$free_list[i] = NULL //初始化
sweeping = $heap_start //从堆头部开始
while(sweeping < $heap_end) //遍历堆
if(sweeping.mark == TRUE) //若是活动对象
sweeping.mark = FALSE //清除标记,为下次GC做准备
else
//计算对象大小在空闲链表数组的下标
index = sweeping.size / (WORD_LENGTH / BYTE_LENGTH )
if(index <= 100) //假设上限为100
sweeping.next = $free_list[index]
$free_list[index] = sweeping //头插法加入空闲链表
else
sweeping.next = $free_list[101]
$free_list[101] = sweeping //头插法加入空闲链表
sweeping += sweeping.size //下一个对象
}
在分配过程中我们先根据对象大小计算出在空闲数组中的下标,如果是100以内,就直接分配,如果大于100,还是按以前的方式,遍历链表寻找合适分块。而在回收时,也需要根据对象大小插入到不同的空闲链表中去。
Go语言的GC也采用了类似的分级方案,不过Go是按2的整数倍进行分级的。
BiBOP
BiBOP是为了减少碎片化而设计的优化方案,全称Big Bag Of Pages。具体操作是把堆分割成固定大小的块,让每个块只分配相同大小的对象。如下图所示。

BiBOP并不能完全消除碎片化,反而还会降低堆的使用效率。
位图标记
在标记和清除阶段,为了区分对象是活动对象还是非活动对象,我们使用了一个字段来记录对象的状态。这个字段在对象头部,与对象的数据放在一起。

因为对象状态只有两种,位图标记的思路是将所有对象的状态放到一个独立的地方集中管理。堆中每个字节的状态用1bit表示,因为对象的数量是不确定的,但是只要堆的大小确定,字节数也就确定了。

使用位图标记的标记和清除伪代码如下:
mark(obj) {
obj_num = (obj - $heap_start) / WORD_LENGTH //对象距堆头的偏移量
index = obj_num / WORD_LENGTH //标志位在第几个字节
offset = obj_num % WORD_LENGTH //标志位在第几个比特
if(($bitmap_tbl[index] & (1 << offset)) == 0) //未标记
$bitmap_tbl[index] |= (1 << offset) //标记为活动对象
for(child : children(obj))
mark(*child) //递归标记子对象
}
相比于之前的版本只是改成了位操作而已。
sweep_phase() {
sweeping = $heap_start
index = 0
offset = 0
while(sweeping < $heap_end) //遍历堆
if($bitmap_tbl[index] & (1 << offset) == 0) //非活动对象
sweeping.next = $free_list
$free_list = sweeping //头插法加入空闲链表
index += (offset + sweeping.size) / WORD_LENGTH //下一个对象的状态位在第几个字节
offset = (offset + sweeping.size) % WORD_LENGTH //下一个对象的状态位在第几个比特
sweeping += sweeping.size //下一个对象
for(i : 0..(HEAP_SIZE / WORD_LENGTH - 1))
$bitmap_tbl[i] = 0 //清除标记,为下次GC做准备
}
相比于之前的清除算法,现在的清除效率更高,因为现在是批量清除的。
此外,由于GC只会修改位图区域,因此写时复制也只需要复制位图,代价要小很多,算是于写时复制兼容了。
最后要注意的是,每个堆都需要一个位图。如果 有多个堆,就需要多个位图。
Go语言的GC采用了位图表格。
延迟清除
延迟清除的思想是在标记完成后并不马上执行清除,而是延迟到分配的阶段再执行清除。目的是为了减少因清除而导致的程序暂停,因为现在程序和GC还是串行执行的。

上图中,mutator表示应用程序,A,B,C时段GC运行,应用程序暂停,其中B就是最大暂停时间。
延迟清除的分配算法伪代码如下:
//分配对象
new_obj(size) {
chunk = lazy_sweep(size) //分配
if(chunk != NULL) //分配成功
return chunk
mark_phase() //标记
chunk = lazy_sweep(size) //再次尝试分配
if(chunk != NULL) //分配成功
return chunk
allocation_fail() //分配失败
}
//延迟清除
lazy_sweep(size) {
//注意$sweeping是全局变量
while($sweeping < $heap_end) //遍历堆
if($sweeping.mark == TRUE) //活动对象
$sweeping.mark = FALSE //清除标记
else if($sweeping.size >= size) //非活动对象,并且大小大于等于size
chunk = $sweeping //将非活动对象分配出去
$sweeping += $sweeping.size //下一个对象
return chunk //分配成功
$sweeping += $sweeping.size //下一个对象
//如果第一次分配失败,再次分配就会从头开始
$sweeping = $heap_start
return NULL //分配失败
}
此时分配算法会在首次分配失败后进行标记,并再次尝试分配。从lazy_sweep函数可以看出,如果首次分配失败,第二次就会从头开始。$sweeping是一个全局变量,记录了每次分配成功后的位置,每次都是从上次分配成功的位置向后查找合适的分块。
你会发现它并没有空闲链表,每次分配都是在遍历整个堆。所以它是有最好和最坏情况的,最坏情况反而会使程序暂停时间更长。
总结
- GC标记清除算法分标记和清除两个阶段。标记阶段从根节点开始为活动对象打上标记,清除阶段遍历堆将非活动对象加入空闲链表。
- 多空闲链表利用数组模拟哈希表加快了分配速度。
- BiBOP是为了优化碎片化问题。
- 位图标记提高了清除效率,兼容写时复制。
- 延迟清除旨在减少最大暂停时间。