1,词向量由来
很多情况下,我们希望将单词转换为vector,让计算机跟数字进行打交道
例如:猫这个词,人们希望会通过这个词进行联想,可以得到动物、有毛、宠物、吃鱼等
为了表示这些单词,出现了很多的方法
①词典表示
用一个词典进行表示,把每一个单词都变成对应的一个数字,例如:{"yanyu":1,"Beyond":2,"hjj":3}
这里的1、2、3并没有包含单词本身的语义信息
缺点:一万个单词需要一万个词典来接收,很麻烦
②One-hot表示
跟词典表示方法类似,只不过是把一个词变成了一个向量进行表示而已
yanyu:[0,0,0,0,0,0,0,1]、Beyond:[0,0,0,0,0,0,1,0]、hjj:[0,0,0,0,0,0,1,1]
缺点:工作量大,单词表膨胀
③Bag of Words表示
把所有单词出现的次数进行标识

缺点:单词的顺序没有被考虑,语义信息仍未被考虑
④TF-IDF
罕见的单词权重高一点,常见的单词权重低一些,稍微加了一些单词的语义信息,但仍然很难表示单词的具体语义信息

⑤Bi-gram和N-gram
将多个单词拼在一起作为整体加入单词表

虽然考虑了词的顺序,但词表过于膨胀,并未解决根本的问题
⑥分布式表示(Distributed representation)
"You shall know a word by the company it keeps." ----- J. R. Firth 1957: 11
用一个词附近的其他词来表示该词
若想知道某个单词的具体含义,就看这个单词会跟什么别的单词同时出现,就能知道这个单词的含有,例如:banking跟crises和regulation有关系

⑦Word2Vec:Skip-Gram模型
假设有50000个单词,每个单词都是100维
input embedding输入词向量:需要新建一个50000100的矩阵,进来一个单词,就把这个单词所在的那一行取出来,将其作为输入词向量,也就是公式里面的u(0)
output embedding输出词向量:这里也是一个50000100的矩阵,也就是公式里面的v©
输入w(t),t表示单词的位置
使用一个一层神经网络预测周围的若干个单词,w(t-1)、w(t-2)、w(t+1)…
用中心词去预测周围的单词
最终的目的只是使用模型中的某些参数


所用到的损失函数完整展开式:
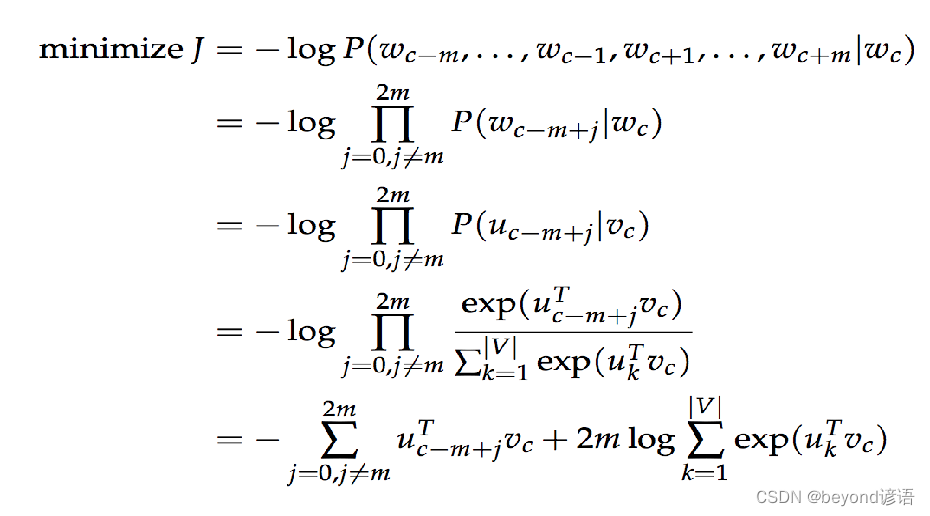
涉及到求和和点积,运算速度很慢,工作量大。
Skip-Gram:负例采样Negative Sampling
制定一个假的任务,用一个中心词去预测周围词,因为这个任务太困难了,所以使用负例采样。
给定一个中心词、一个正确的周围词和若干个错误的周围词(从单词表中随机采样),希望前面的部分越大越好,后面的部分因为有负号,所以也希望越大越好
P(w|context(w)): 一个正样本,V-1个负样本,对负样本做采样
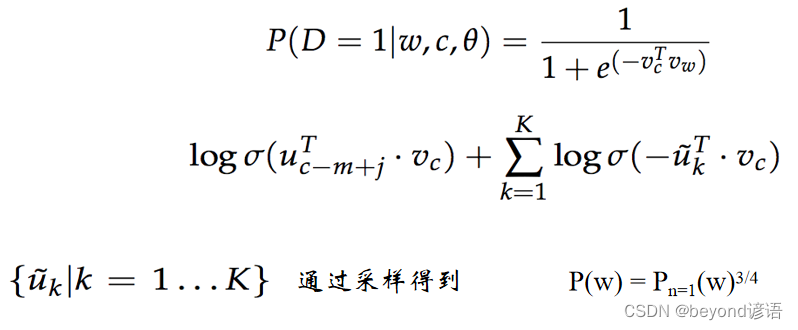
本来是个超大的分类问题,通过负例采样就变成了一个二分类问题,只关心两个单词之间是不是相邻的,若相邻返回一个高一点的概率;若不相邻,返回一个低一点的概率
Negative Sampling想法提出的论文出处:《Distributed Representations of Words and Phrases and their Compositionality》
⑧应用
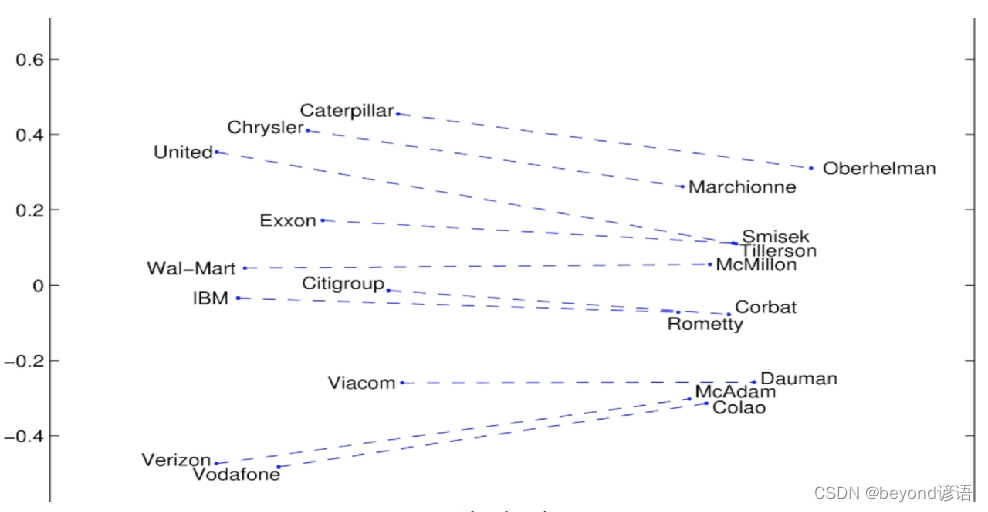
Ⅰ词嵌入可视化: 公司 — CEO
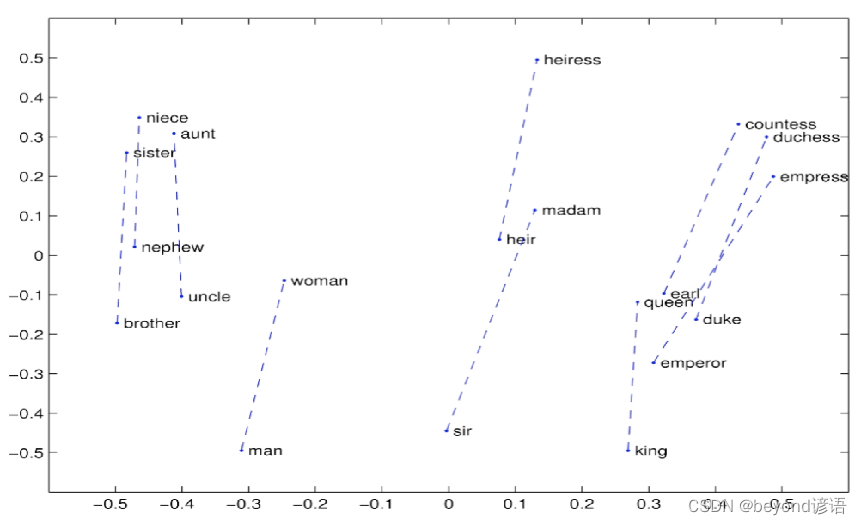
Ⅱ词嵌入可视化: 词向
Ⅲ词嵌入可视化: 比较级和最高级
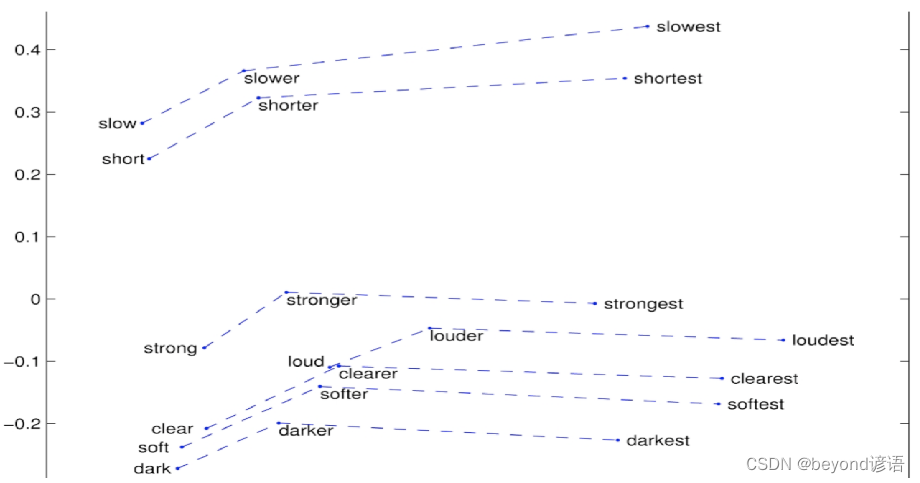
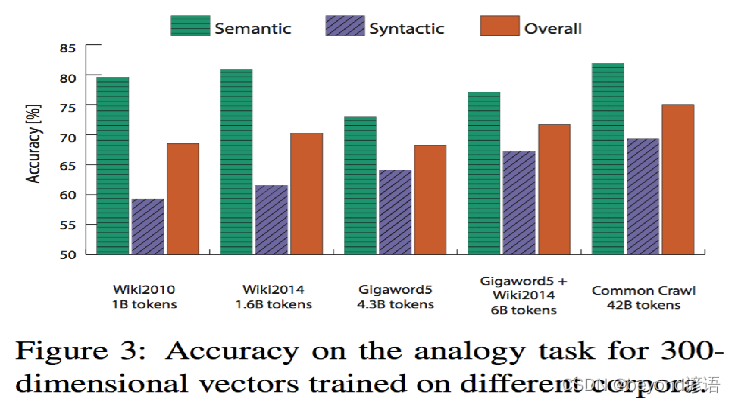
Ⅳ词嵌入可视化: 词类比任务

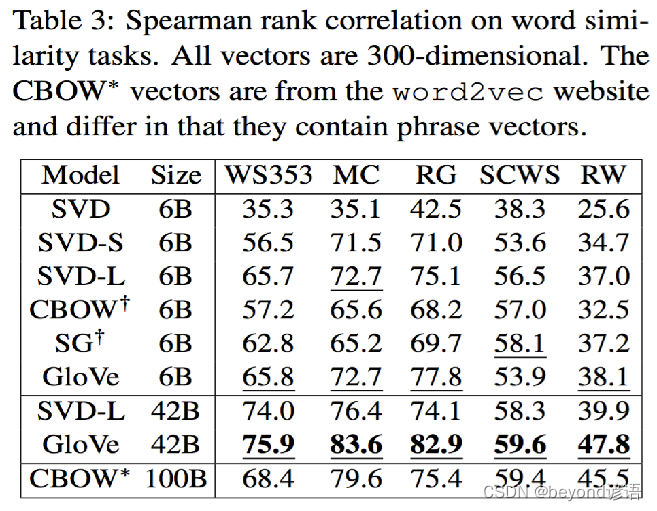
Ⅴ词嵌入效果评估: 词相似度任务

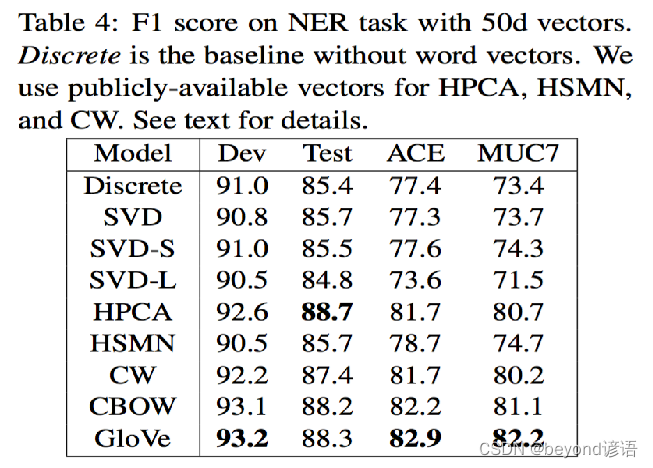
Ⅵ词嵌入效果评估: 作为特征用于CRF实体识别

2,PyTorch实现
Ⅰ、对数据进行预处理操作
①导包
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as tud
from torch.nn.parameter import Parameter
import numpy as np
import random
import math
import pandas as pd
import scipy
import sklearn
from collections import Counter #计算某个单词出现的次数
from sklearn.metrics.pairwise import cosine_similarity
②固定随机初始化参数
为了保证实验结果的可复性,把所有的seed都固定下来,每次训练的结果就会一致
模型的随机初始化会对模型有一定的影响,每次跑出来的结果都不一样,为了让模型实验结果尽量保持一致,把seed都变成一个固定的值即可,每次随机初始化的结果都是一样的,结果就可以复现了
USE_CUDA = torch.cuda.is_available()
# 为了保证实验结果可以复现,我们经常会把各种random seed固定在某一个值
random.seed(53113)
np.random.seed(53113)
torch.manual_seed(53113)
if USE_CUDA:
torch.cuda.manual_seed(53113)
③设定超参数
C=3,定义周围3个单词算周围词
K=100,没出现一个正确的周围词,就会伴随着出现100个非周围词
NUM_EPOCHS=2,训练多少次epoch
MAX_VOCAB_SIZE=30000,最终一共有多少个单词,词汇表有多大,这里训练三万个最常见的单词的词向量
BATCH_SIZE=128,每128个词为一组进行训练
LEARNING_RATE=0.2,学习率设置为0.2
# 设定一些超参数
K = 100 # number of negative samples
C = 3 # nearby words threshold
NUM_EPOCHS = 2 # The number of epochs of training
MAX_VOCAB_SIZE = 30000 # the vocabulary size
BATCH_SIZE = 128 # the batch size
LEARNING_RATE = 0.2 # the initial learning rate
EMBEDDING_SIZE = 100
④定义分割单词函数
把一篇文本转化成一个个单词
def word_tokenize(text):
return text.split()
⑤训练词向量
训练所需数据集下载
我这里放到了项目所在当前目录下了
with open("./text8.train.txt", "r") as fin:
text = fin.read()
# 测试一下
text[:500] # 看下训练集都是啥内容,一堆文章里面的东西,没有标点符号
text[:500].split() # 拿到一个个单词
从文本文件中读取所有的文字,通过这些文本创建一个vocabulary
由于单词数量可能太大,只选取最常见的MAX_VOCAB_SIZE个单词
添加一个UNK单词表示所有不常见的单词
text = text.split(),得到一个一个分割之后的单词
vocab = dict(Counter(text).most_common(MAX_VOCAB_SIZE - 1)),其中Counter(text)把text中的单词全部给数一遍,每一个单词究竟出现了多少次,统计最频繁出现的MAX_VOCAB_SIZE - 1这些词给取出来,通过.most_common来实现。减一操作是因为要留取UNK不常用的单词数量位置信息。dict()最后变成字典形式。
vocab["<unk>"] = len(text) - np.sum(list(vocab.values()))留一个位置给UNK不常用的单词数量位置信息。vocab.values()表示单词出现的次数,求和之后再减掉就大概是UNK不常用的单词出现的频率
text = text.split()
vocab = dict(Counter(text).most_common(MAX_VOCAB_SIZE-1))
vocab["<unk>"] = len(text) - np.sum(list(vocab.values()))
vovab # 查看下在训练数据中所获取的每个单词所出现的次数,就可以构建词汇表
idx_to_word = [word for word in vocab.keys()] ,把这个list中所有单词表中的单词给取下来
word_to_idx = {word:i for i, word in enumerate(idx_to_word)},出现的次数和单词交换位置
idx_to_word = [word for word in vocab.keys()]
word_to_idx = {
word:i for i, word in enumerate(idx_to_word)}
idx_to_word
"""
['the',
'of',
'and',
...]
"""
list(word_to_idx.items())
"""
[('the', 0),
('of', 1),
('and', 2),
('one', 3),
('in', 4),
...]
"""
word_counts = np.array([count for count in vocab.values()], dtype=np.float32),其中vocab.values()是每个单词的出现次数,最终获得每个单词出现的次数
word_freqs = word_counts / np.sum(word_counts),每个单词出现的次数除以所有的单词出现的次数,可以得到每个单词出现的频率
word_freqs = word_freqs ** (3./4.),因为Negative Sampling所在论文中提到了把概率提到原来的3/4次方,效果会更好些。
word_freqs = word_freqs / np.sum(word_freqs) ,因为概率发生了改变,故需要再次计算一下频率,相同的操作即可
VOCAB_SIZE = len(idx_to_word),需要再次更新一下VOCAB_SIZE ,以防万一训练数据中和预处理之前定义的30000个单词不一致
word_counts = np.array([count for count in vocab.values()], dtype=np.float32)
word_freqs = word_counts / np.sum(word_counts)
word_freqs = word_freqs ** (3./4.)
word_freqs = word_freqs / np.sum(word_freqs) # 用来做 negative sampling
VOCAB_SIZE = len(idx_to_word)
VOCAB_SIZE
代码整合:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as tud
from torch.nn.parameter import Parameter
import numpy as np
import random
import math
import pandas as pd
import scipy
import sklearn
from collections import Counter #计算某个单词出现的次数
from sklearn.metrics.pairwise import cosine_similarity
USE_CUDA = torch.cuda.is_available()
# 为了保证实验结果可以复现,我们经常会把各种random seed固定在某一个值
random.seed(53113)
np.random.seed(53113)
torch.manual_seed(53113)
if USE_CUDA:
torch.cuda.manual_seed(53113)
# 设定一些超参数
K = 100 # number of negative samples
C = 3 # nearby words threshold
NUM_EPOCHS = 2 # The number of epochs of training
MAX_VOCAB_SIZE = 30000 # the vocabulary size
BATCH_SIZE = 128 # the batch size
LEARNING_RATE = 0.2 # the initial learning rate
EMBEDDING_SIZE = 100
def word_tokenize(text):
return text.split()
with open("./text8.train.txt", "r") as fin:
text = fin.read()
text = text.split()
vocab = dict(Counter(text).most_common(MAX_VOCAB_SIZE-1))
vocab["<unk>"] = len(text) - np.sum(list(vocab.values()))
idx_to_word = [word for word in vocab.keys()]
word_to_idx = {
word:i for i, word in enumerate(idx_to_word)}
word_counts = np.array([count for count in vocab.values()], dtype=np.float32)
word_freqs = word_counts / np.sum(word_counts)
word_freqs = word_freqs ** (3./4.)
word_freqs = word_freqs / np.sum(word_freqs) # 用来做 negative sampling
VOCAB_SIZE = len(idx_to_word)
VOCAB_SIZE # 30000
Ⅱ、Dataloader
为了使用dataloader,我们需要定义以下两个function:
__len__ 需要返回整个数据集中有多少个item
__get__ 根据给定的index返回一个item
官网DataLoader使用手册
⑥定义Dataloader
把所有text编码成数字,然后用subsampling预处理这些文字
保存vocabulary,单词count,normalized word frequency
每个iteration sample一个中心词
根据当前的中心词返回context单词
根据中心词sample一些negative单词
返回单词的counts
整合代码如下:
class WordEmbeddingDataset(tud.Dataset): #tud.Dataset父类
def __init__(self, text, word_to_idx, idx_to_word, word_freqs, word_counts):
''' text: a list of words, all text from the training dataset
word_to_idx: the dictionary from word to idx
idx_to_word: idx to word mapping
word_freq: the frequency of each word
word_counts: the word counts
'''
super(WordEmbeddingDataset, self).__init__() #初始化模型
self.text_encoded = [word_to_idx.get(t, VOCAB_SIZE-1) for t in text]
#字典 get() 函数返回指定键的值(第一个参数),如果值不在字典中返回默认值(第二个参数)。
#取出text里每个单词word_to_idx字典里对应的索引,不在字典里返回"<unk>"的索引
#"<unk>"的索引=29999,get括号里第二个参数应该写word_to_idx["<unk>"],不应该写VOCAB_SIZE-1,虽然数值一样。
self.text_encoded = torch.Tensor(self.text_encoded).long()
#变成tensor类型,这里变成longtensor,也可以torch.LongTensor(self.text_encoded)
self.word_to_idx = word_to_idx #保存数据
self.idx_to_word = idx_to_word #保存数据
self.word_freqs = torch.Tensor(word_freqs) #保存数据
self.word_counts = torch.Tensor(word_counts) #保存数据
def __len__(self): #数据集有多少个item
#魔法函数__len__
''' 返回整个数据集(所有单词)的长度
'''
return len(self.text_encoded) #所有单词的总数
def __getitem__(self, idx):
#魔法函数__getitem__,这个函数跟普通函数不一样
''' 这个function返回以下数据用于训练
- 中心词
- 这个单词附近的(positive)单词
- 随机采样的K个单词作为negative sample
'''
center_word = self.text_encoded[idx]
#print(center_word)
#中心词索引
#这里__getitem__函数是个迭代器,idx代表了所有的单词索引。
pos_indices = list(range(idx-C, idx)) + list(range(idx+1, idx+C+1))
#周围词索引的索引,比如idx=0时。pos_indices = [-3, -2, -1, 1, 2, 3]
#C表示前后周围是3的单词,前3后3个单词
pos_indices = [i%len(self.text_encoded) for i in pos_indices]
#range(idx+1, idx+C+1)超出词汇总数时,需要特别处理,取余数
pos_words = self.text_encoded[pos_indices]
#周围词索引,就是希望出现的正例单词
#print(pos_words)
neg_words = torch.multinomial(self.word_freqs, K * pos_words.shape[0], True)
#负例采样单词索引,torch.multinomial作用是对self.word_freqs做K * pos_words.shape[0]次取值,输出的是self.word_freqs对应的下标。
#取样方式采用有放回的采样,并且self.word_freqs数值越大,取样概率越大。
#每个正确的单词采样K个,pos_words.shape[0]是正确单词数量
#print(neg_words)
return center_word, pos_words, neg_words
⑦创建dataset和dataloader
dataset = WordEmbeddingDataset(text, word_to_idx, idx_to_word, word_freqs, word_counts)
# list(dataset) 可以把尝试打印下center_word, pos_words, neg_words看看
dataloader = tud.DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
测试一下dataloader
优化器选择SGD
optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE)
for e in range(NUM_EPOCHS):
for i,(input_labels,pos_lables,neq_labels) in enumerate(dataloader):
print(input_labels,pos_lables,neq_labels)
if i>5:
break
测试一下dataset
dataset.idx_to_word[:100]
dataset.word_freqs[:100]
dataset.word_counts[:100]
⑧定义PyTroch模型
class EmbeddingModel(nn.Module):
def __init__(self, vocab_size, embed_size):
''' 初始化输出和输出embedding
'''
super(EmbeddingModel, self).__init__()
self.vocab_size = vocab_size #30000
self.embed_size = embed_size #100
initrange = 0.5 / self.embed_size
self.out_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)
#模型输出nn.Embedding(30000, 100)
self.out_embed.weight.data.uniform_(-initrange, initrange)
#权重初始化的一种方法
self.in_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)
#模型输入nn.Embedding(30000, 100)
self.in_embed.weight.data.uniform_(-initrange, initrange)
#权重初始化的一种方法
def forward(self, input_labels, pos_labels, neg_labels):
'''
input_labels: 中心词, [batch_size]
pos_labels: 中心词周围 context window 出现过的单词 [batch_size * (window_size * 2)]
neg_labelss: 中心词周围没有出现过的单词,从 negative sampling 得到 [batch_size, (window_size * 2 * K)]
return: loss, [batch_size]
'''
batch_size = input_labels.size(0) #input_labels是输入的标签,tud.DataLoader()返回的。相已经被分成batch了。
input_embedding = self.in_embed(input_labels)
# B * embed_size
#这里估计进行了运算:(128,30000)*(30000,100)= 128(B) * 100 (embed_size)
pos_embedding = self.out_embed(pos_labels) # B * (2*C) * embed_size
#同上,增加了维度(2*C),表示一个batch有B组周围词单词,一组周围词有(2*C)个单词,每个单词有embed_size个维度。
neg_embedding = self.out_embed(neg_labels) # B * (2*C * K) * embed_size
#同上,增加了维度(2*C*K)
#torch.bmm()为batch间的矩阵相乘(b,n.m)*(b,m,p)=(b,n,p)
log_pos = torch.bmm(pos_embedding, input_embedding.unsqueeze(2)).squeeze() # B * (2*C)
log_neg = torch.bmm(neg_embedding, -input_embedding.unsqueeze(2)).squeeze() # B * (2*C*K)
#unsqueeze(2)指定位置升维,.squeeze()压缩维度。
#下面loss计算就是论文里的公式
log_pos = F.logsigmoid(log_pos).sum(1)
log_neg = F.logsigmoid(log_neg).sum(1) # batch_size
loss = log_pos + log_neg
return -loss
def input_embeddings(self): #取出self.in_embed数据参数
return self.in_embed.weight.data.cpu().numpy()
⑨定义一个模型以及把模型移动到GPU
model = EmbeddingModel(VOCAB_SIZE, EMBEDDING_SIZE)
#得到model,有参数,有loss,可以优化了
if USE_CUDA:
model = model.cuda()
⑩训练模型
optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE)
for e in range(NUM_EPOCHS):
for i,(input_labels,pos_lables,neq_labels) in enumerate(dataloader):
input_labels = input_labels.long()
pos_labels = pos_labels.long()
neg_labels = neg_labels.long()
if USE_CUDA:
input_labels = input_labels.cuda()
pos_labels = pos_labels.cuda()
neg_labels = neg_labels.cuda()
optimizer.zero_grad()
loss = model(input_labels, pos_labels, neg_labels).mean()
loss.backward()
optimizer.step()
if i % 100 == 0:print("epoch: {}, iter: {}, loss: {}".format(e, i, loss.item()))
完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as tud
from torch.nn.parameter import Parameter
import numpy as np
import random
import math
import pandas as pd
import scipy
import sklearn
from collections import Counter #计算某个单词出现的次数
from sklearn.metrics.pairwise import cosine_similarity
USE_CUDA = torch.cuda.is_available()
# 为了保证实验结果可以复现,我们经常会把各种random seed固定在某一个值
random.seed(53113)
np.random.seed(53113)
torch.manual_seed(53113)
if USE_CUDA:
torch.cuda.manual_seed(53113)
# 设定一些超参数
K = 100 # number of negative samples
C = 3 # nearby words threshold
NUM_EPOCHS = 2 # The number of epochs of training
MAX_VOCAB_SIZE = 30000 # the vocabulary size
BATCH_SIZE = 128 # the batch size
LEARNING_RATE = 0.2 # the initial learning rate
EMBEDDING_SIZE = 100
def word_tokenize(text):
return text.split()
with open("./text8.train.txt", "r") as fin:
text = fin.read()
text = text.split()
vocab = dict(Counter(text).most_common(MAX_VOCAB_SIZE-1))
vocab["<unk>"] = len(text) - np.sum(list(vocab.values()))
idx_to_word = [word for word in vocab.keys()]
word_to_idx = {
word:i for i, word in enumerate(idx_to_word)}
word_counts = np.array([count for count in vocab.values()], dtype=np.float32)
word_freqs = word_counts / np.sum(word_counts)
word_freqs = word_freqs ** (3./4.)
word_freqs = word_freqs / np.sum(word_freqs) # 用来做 negative sampling
VOCAB_SIZE = len(idx_to_word)
#定义dataloader
class WordEmbeddingDataset(tud.Dataset):
def __init__(self, text, word_to_idx, idx_to_word, word_freqs, word_counts):
''' text: a list of words, all text from the training dataset
word_to_idx: the dictionary from word to idx
idx_to_word: idx to word mapping
word_freq: the frequency of each word
word_counts: the word counts
'''
super(WordEmbeddingDataset, self).__init__()
self.text_encoded = [word_to_idx.get(t, VOCAB_SIZE-1) for t in text]
self.text_encoded = torch.Tensor(self.text_encoded).long()
self.word_to_idx = word_to_idx
self.idx_to_word = idx_to_word
self.word_freqs = torch.Tensor(word_freqs)
self.word_counts = torch.Tensor(word_counts)
def __len__(self):
''' 返回整个数据集(所有单词)的长度
'''
return len(self.text_encoded)
def __getitem__(self, idx):
''' 这个function返回以下数据用于训练
- 中心词
- 这个单词附近的(positive)单词
- 随机采样的K个单词作为negative sample
'''
center_word = self.text_encoded[idx]
pos_indices = list(range(idx-C, idx)) + list(range(idx+1, idx+C+1))
pos_indices = [i%len(self.text_encoded) for i in pos_indices]
pos_words = self.text_encoded[pos_indices]
neg_words = torch.multinomial(self.word_freqs, K * pos_words.shape[0], True)
return center_word, pos_words, neg_words
dataset = WordEmbeddingDataset(text, word_to_idx, idx_to_word, word_freqs, word_counts)
dataloader = tud.DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
# 定义模型
class EmbeddingModel(nn.Module):
def __init__(self, vocab_size, embed_size):
''' 初始化输出和输出embedding
'''
super(EmbeddingModel, self).__init__()
self.vocab_size = vocab_size
self.embed_size = embed_size
initrange = 0.5 / self.embed_size
self.out_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)
self.out_embed.weight.data.uniform_(-initrange, initrange)
self.in_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)
self.in_embed.weight.data.uniform_(-initrange, initrange)
def forward(self, input_labels, pos_labels, neg_labels):
'''
input_labels: 中心词, [batch_size]
pos_labels: 中心词周围 context window 出现过的单词 [batch_size * (window_size * 2)]
neg_labelss: 中心词周围没有出现过的单词,从 negative sampling 得到 [batch_size, (window_size * 2 * K)]
return: loss, [batch_size]
'''
#batch_size = input_labels.size(0)
input_embedding = self.in_embed(input_labels) # B * embed_size
pos_embedding = self.in_embed(pos_labels) # B * (2*C) * embed_size
neg_embedding = self.in_embed(neg_labels) # B * (2*C * K) * embed_size
input_embedding = input_embedding.unsqueeze(2)
log_pos = torch.bmm(pos_embedding, input_embedding.unsqueeze(2)).squeeze() # B * (2*C)
log_neg = torch.bmm(neg_embedding, -input_embedding.unsqueeze(2)).squeeze() # B * (2*C*K)
log_pos = F.logsigmoid(log_pos).sum(1)
log_neg = F.logsigmoid(log_neg).sum(1) # batch_size
loss = log_pos + log_neg
return -loss
def input_embeddings(self):
return self.in_embed.weight.data.cpu().numpy()
#模型训练
model = EmbeddingModel(VOCAB_SIZE, EMBEDDING_SIZE)
if USE_CUDA:
model = model.cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE)
for e in range(NUM_EPOCHS):
for i,(input_labels,pos_lables,neq_labels) in enumerate(dataloader):
input_labels = input_labels.long()
pos_labels = pos_labels.long()
neg_labels = neg_labels.long()
if USE_CUDA:
input_labels = input_labels.cuda()
pos_labels = pos_labels.cuda()
neg_labels = neg_labels.cuda()
optimizer.zero_grad()
loss = model(input_labels, pos_labels, neg_labels).mean()
loss.backward()
optimizer.step()
if i % 100 == 0:print("epoch: {}, iter: {}, loss: {}".format(e, i, loss.item()))
Ⅲ、模型评估
评估的测试集simlex-999.txt、men.txt、wordsim353.csv下载
放到和项目所在同一路径下
def evaluate(filename, embedding_weights):
if filename.endswith(".csv"):
data = pd.read_csv(filename, sep=",")
else:
data = pd.read_csv(filename, sep="\t")
human_similarity = []
model_similarity = []
for i in data.iloc[:, 0:2].index:
word1, word2 = data.iloc[i, 0], data.iloc[i, 1]
if word1 not in word_to_idx or word2 not in word_to_idx:
continue
else:
word1_idx, word2_idx = word_to_idx[word1], word_to_idx[word2]
word1_embed, word2_embed = embedding_weights[[word1_idx]], embedding_weights[[word2_idx]]
model_similarity.append(float(sklearn.metrics.pairwise.cosine_similarity(word1_embed, word2_embed)))
human_similarity.append(float(data.iloc[i, 2]))
return scipy.stats.spearmanr(human_similarity, model_similarity)# , model_similarity
def find_nearest(word):
index = word_to_idx[word]
embedding = embedding_weights[index]
cos_dis = np.array([scipy.spatial.distance.cosine(e, embedding) for e in embedding_weights])
return [idx_to_word[i] for i in cos_dis.argsort()[:10]]
在 MEN 和 Simplex-999 数据集上做评估
embedding_weights = model.input_embeddings()
print("simlex-999", evaluate("./simlex-999.txt", embedding_weights))
print("men", evaluate("./men.txt", embedding_weights))
print("wordsim353", evaluate("./wordsim353.csv", embedding_weights))
寻找nearest neighbors
for word in ["good", "fresh", "monster", "green", "like", "america", "chicago", "work", "computer", "language"]:
print(word, find_nearest(word))
单词之间的关系
man_idx = word_to_idx["man"]
king_idx = word_to_idx["king"]
woman_idx = word_to_idx["woman"]
embedding = embedding_weights[woman_idx] - embedding_weights[man_idx] + embedding_weights[king_idx]
cos_dis = np.array([scipy.spatial.distance.cosine(e, embedding) for e in embedding_weights])
for i in cos_dis.argsort()[:20]:
print(idx_to_word[i])