在linux中,会常用到这些命令进行文件下载,软件安装以及url访问,但总是分不清楚什么时候用什么命令去下载或者安装和访问。这里将这几个命令的用法和区别进行一个说明,方便大家学习和记忆。
1.首先是wget跟curl
wget:
wget是用来下载文件的,默认是下载到当前目录的。wget比较稳定,它在带宽很窄的时候和不稳定网络中适应性很强,当网络不稳定导致下载失败的时候,wget会不断尝试,直到整个文件下载完毕。如果是服务器打断下载过程,也会再联到服务器从停止的地方继续下载。这对从那些限定链接时间的服务器上下载大文件非常有用。
语法为:wget + 选项 + 参数
常用选项有:
-b:进行后台的方式运行wget
-c:继续执行上次终端的任务
-r:递归下载方式
-O:指定文件名(-O (大写的O):指定下载文件的路径)
例如:
wget -O /tmp/1.txt www.baidu.com-nc:文件存在时,下载文件不覆盖原有文件
-nv:下载时只显示更新和出错信息,不显示指令的详细执行过程
-P:指定下载目录
--no-check-certificate:下载https网站资源时可能需要使用该选项跳过证书检测的过程
参数:
URL:下载指定的URL地址
例1:使用wget下载单个文件
wget http://www.xxx.net/xxx.zip #使用wget下载zip压缩包文件(下载到当前目录下)例2:使用wget下载文件到指定目录
wget -P /opt/test http://www.xxx.net/xxx.zip #使用wget下载zip压缩包文件到test目录下例3:下载并以不同的文件名保存
可以使用-O选项
wget -O /tmp/1.txt www.baidu.com 将访问www.baidu.com的index.html的内容下载到/tmp/1.txt文件中去(可以理解为将下载的index.html文件重命名为/tmp目录下的1.txt)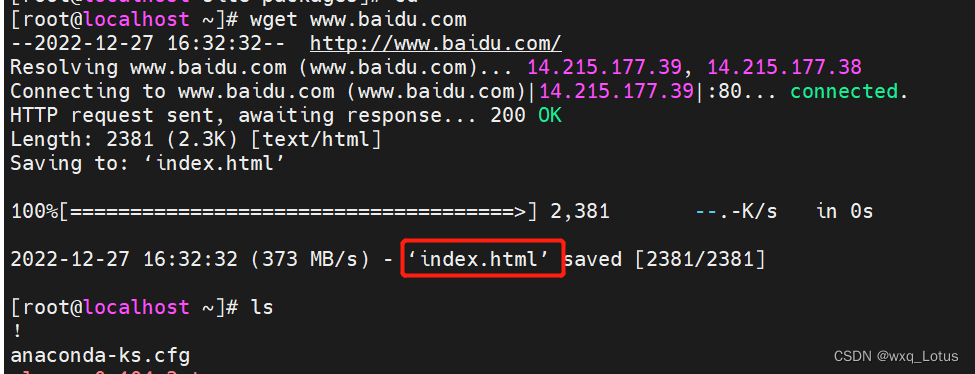
![]()
例4:使用wget断点续传
wget -c http://www.xxx.net/xxx.zip #即使用wget -c重启下载中断的文件,对于下载大文件时由于网络不稳定导致中断时很有帮助,从而可以继续接着上次中断的地方继续下载,节省时间和链接服务器的时长。例5:使用wget后台下载
对下载非常大的文件时,这个命令很有帮助,可以干别的事情,不影响其他工作,使用-b参数后台进行下载
wget -b http://www.xxx.net/xxx.zip
Continuing in background, pid 1840.
Output will be written to `wget-log'.例六:解决wget下载https开头的网址域名时报错 --no-check-certificate
如果使用 wget下载https开头的网址域名时报错,需要加上 --no-check-certificate (不检查证书)选项
wget https://pypi.python.org/packages/88/28/79162bfc351a3f1ab44d663ab3f03fb495806fdb592170990a1568ffbf63/IPy-0.83.tar.gz --no-check-certificatecurl:
curl是用来访问链接的,常用的命令行工具,用来请求web服务器。
语法:curl + 选项 + url
常用选项:
-X(大写):参数指定http请求方法。
-H参数添加http请求标头
-d:参数用于发送POST请求的数据体
使用-d参数,自动将请求转为POST方法,可省略-X POST
例:语法curl -X POST -H '请求头参数' -d '文件的json格式' -i + url
curl -X POST -H 'Content-Type:application/json' -d '@data.json' -i https://iam.cn-north-4.myhuaweicloud.com/v3/auth/tokens -d参数可以读取本地文本的数据,向服务器发送
如是json格式的body,则必须要上传文件的json格式
curl -XPOST -d '@data.json' -i https://xxx.com/xxx/xxx/tokens
curl -XPOST -T data.json -i https://xxx.com/xxx/xxx/tokens(-T 与上面-d一样,只是少了@)-i参数打印出服务器回应的http标头。(获取相应头中的信息需要加上该选项)
-o参数将服务器的回应保存成文件即将输出写入文件,等同于wget命令
curl -o namefile.tar http://a/b/c/d.tar
curl -o namefile.gz http://a/b/c/d.gz-O参数把某文件或压缩包下载到本地当前目录
curl -O http://a/b/c/d.tar
curl -O http://a/b/c/d.gz-k参数指定跳过ssl检测
-A/--user-agent[string],设置HTTP Request头部的user-agent,通过curl访问网站的默认user-agent是'curl/版本号'
curl -A 'xxxxx ' www.baidu.com
curl -A 'GET或POST' www.baidu.com-e/--referer[string],设置HTTP Request头部的referer,即来源网站的host
curl -e 'referer:www.bing.com或IP地址' www.baidu.com-H/--header<line>,添加自定义的HTTP头部
curl -H 'testHeader:test123456' www.baidu.com-l/--list-only,列出ftp目录下的文件名称
curl -l xxx.xxxxx.xxx/pub/-s/silent,不输出任何内容
curl -s www.baidu.com-u/--user user[:password],指定服务器认证的用户名和密码
-U/--proxy-user user[:password],指定代理认证的用户名、密码
-w/--wirte-out [format],完成后输出什么
curl -o /dev/null www.baidu.com -w 'Hello!'-v/--verbose,显示详细的操作信息
-T/--upload-file FILE 将文件上传到指定位置
-x/--proxy [protocol://]host[:port],在指定端口上使用代理
-a/append,添加要上传的文件
-L,自动重定向到新网址
curl -vLo /dev/null www.baidu.com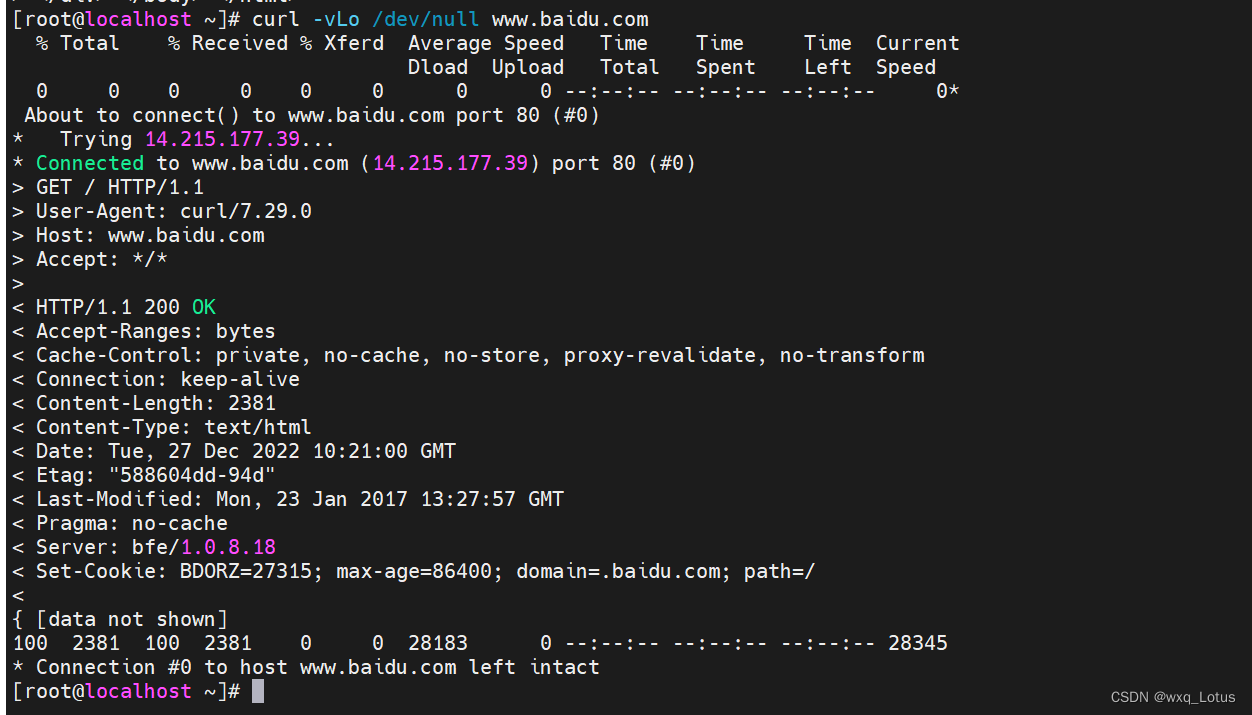
curl www.baidu.com #不带选项,返回的是网站源码
curl -Ik www.baidu.com #查看返回信息的响应头信息
curl -I www.baidu.com #查看一个链接的标头
curl -i -X TRACE http://xxx.xxx.xxx.xxx:xxx
curl -i -X TRACK http://xxx.xxx.xxx.xxxx:xxx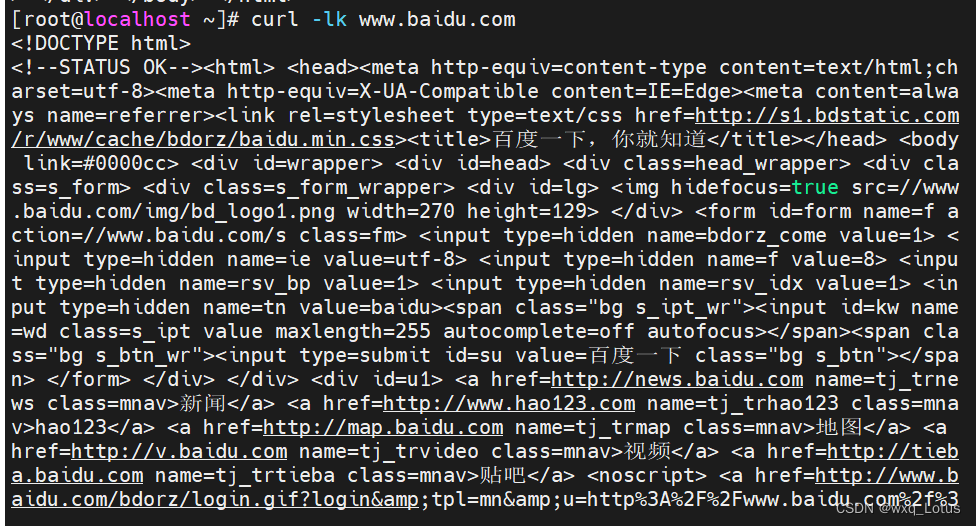
git-clone:
git clone是将项目从github上clone到本地,git clone命令将存储库克隆到新目录中(专门用来下载github上的文件)
语法:git clone <github上的下载链接以.git结尾的> <本地目录名即下载路径>,在github上下载使用git clone下载是最快的
例:
git clone https://github.com/vulhub/vulhub.git /root/test #将从github上下载下来的文件保存到test目录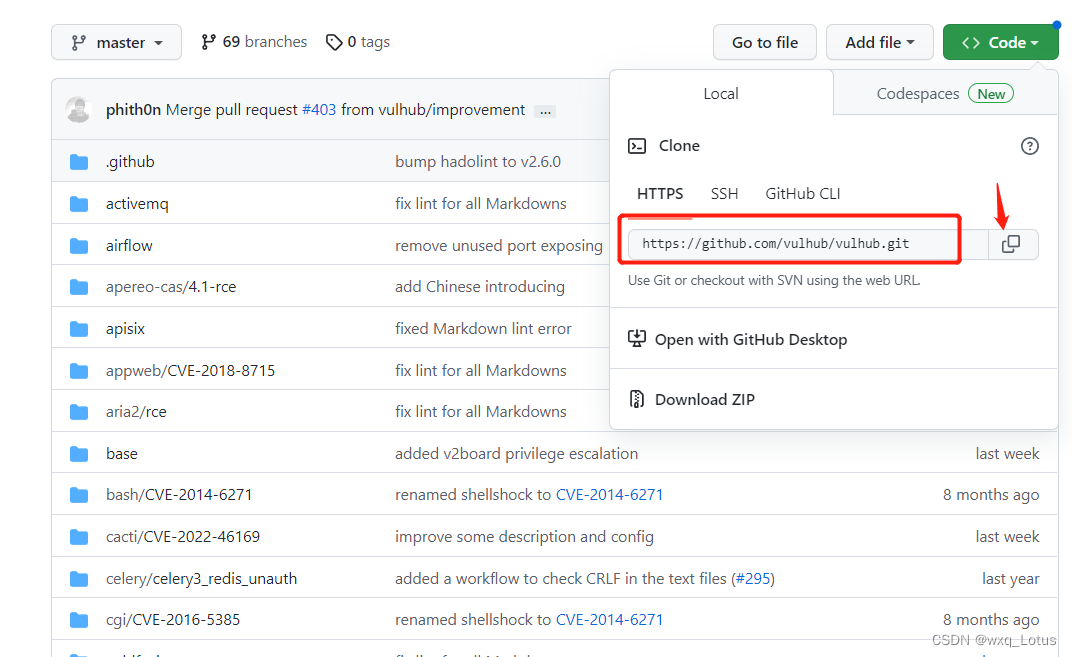
git clone https://github.com/vulhub/vulhub.git #使用git clone下载不指定目录(路径)的话,默认会自动生成一个除"git url"里最后一级目录名的'.git'的后辍去掉,做为新克隆(clone)项目的目录名,这里会生成一个vulhub的目录名git clone <版本库网址.git结尾的网址> <本地目录名> #使用git clone命令下载并指定下载目录(路径)apt-get和pip的区别
apt-get是用来安装系统软件和更新源的,可用来更新Ubuntu的典型依赖包,但只是安装最新或者最近发布的那个的单一版本,不能决定要安装的依赖包的版本或者选择它之前的版本。
pip是用来安装来自Pypi的python所有的依赖包并且可以选择安装在Pypi已上传的先前版本的依赖包。pip安装即编程语言级别的包。pip安装包一般在python虚拟环境中使用即linux中安装了Python,可以不受python library版本的影响,根据编程中使用的包版本安装相应版本的包。
apt-get和pip什么情况下使用
在需要安装最新版本的python依赖包,可以使用apt-get来安装,如果需要安装以前版本的python依赖包时可以使用pip来安装。
apt-get常用命令:
apt-get source package #下载包的源代码
sudo apt-get build-dep package #安装相关的编译环境
sudo apt-get clean && sudo apt-get autoclean #清理无用的包
sudo apt-get dist-upgrade #升级系统
sudo apt-get -f install #修复安装
sudo apt-get install/delete package #安装或者删除包
sudo apt-get upgrade #更新已安装的包pip常用命令:
pip install package #安装相应的包yum:
yum是在fedora和redhat以及CentOS中的shell前端软件包管理器,是基于rpm包管理,能够从指定的服务器自动下载rpm包并安装,能自动处理依赖性关系,并且一次安装所有依赖的软件包,不需要一次次的下载安装。yum可以提供查找、安装、删除某一个、一组甚至全部软件包的命令。
yum语法格式:
yum -opt command package #command为要进行的操作,package是操作对象
yum常用选项:
-h:帮助选项
-y:安装过程提示选择全部为yes
-q:不显示安装过程
yum常用命令:
yum clean packages #清除缓存目录下的软件包,即清空的是(/var/cache/yum)下的缓存
yum clean headers #清除缓存目录下的headers
yum clean oldheaders #清除缓存目录下旧的headers
yum clean yum clean all (yum clean packages;yum clean oldheaders) #清除缓存目录下的软件包及旧的headers
为什么要清除缓存:yum安装软件时会把软件包下载到本地指定的目录中(类似windows中下载的文件压缩包会到暂时保存在C盘的下载目录中,占用C盘磁盘空间),未来节省磁盘空间,就可以使用清除缓存命令清除缓存
yum list #显示所有已经安装和可以安装的软件包
yum list <package_name> #显示安装包信息rpm,显示installed
yum list repolist all #查询所有的yum仓库
yum info <package_name> #显示安装包rpm的详细信息
yum groupinfo <group_name> #显示程序组group信息
yum search string #根据关键字string查找安装包
yum deplist <package_name> #仅查看程序rpm依赖情况
yum provides */命令 #查看命令是由那个包提供的
yum install -y <package_name> #不加-y询问是否安装,控制包安装就不要加-y,自动安装加-y
yum isntall --downloadonly --downloaddir=/xxx/xxx/ #只下载软件不安装
yumdownloader nfs-utils --destdir /tmp/nfs-utils --resolve #可以一次性下载 nfs-utils的RPM 软件包及其所有依赖包,并保存在/tmp/nfs-utils目录下
yum remove <package_name> #卸载程序包,可卸载命令yum或rpm安装包生效,编译安装不生效
yum groupremove <group_name> #删除程序组group
yum check-update #检查可更新的软件有那些
yum update #更新升级所有软件包
yum update <package_name> #更新指定程序包package
yum upgrade <package_name> #升级指定程序包package
yum grouplist #查看那些组可以安装