- Hadoop 生产环境的现状
hadoop目前主流的分支有俩个版本 apache hadoop和cloudera hadoop,俩者都是开源产品。CDH对apache hadoop的所发布的版本上做了梳理并打了相应的patch,提供了较好的产品向下兼容性,并对hadoop的feature做了大量的迭代测试,提供bug和feature的patch。从笔者经历的几个公司,大的7百台,小的也有50台集群规模,都已将cdh作为事实上的大数据生产环境的部署标准。CDH在部署和升级相比于apache hadoop有着极大的便利。CDH将所有组件进行打包,统一放到yum源,或者apt源,用户的安装部署相对简单。为了方便多机器的部署,分布式环境的运营维护,方便整合hadoop生态圈,cloudera在cdh之上提供了一个更加方便的工具,cloudera manager(这个在下文会有详细的介绍)。综合安装使用,环境运维,项目组件运营,人员操作等方面的成本。建议也将cdh作为我们生产和对外产品推广的标准组件之一。
- 公司现状和问题
响应公司的技术趋势,尝试对大数据基础组建进行docker化。目前我是这样做的(我们),举个栗子:hdfs满足线上要求最少需要5个服务,我们编写了5个dockerfile。通过docker-compose来管理我们的服务,通过rancher进行容器编排和动态参数调整。之后我们添加了yarn,我们对hdfs的hdfs-site,yarn-site等配置文件进行调整,然后重新编译打包上传。但是这种方式太低效了,所以我们变更了一种方式,将参数尽可能的通过rancher进行动态传参数。但是引入了新的问题,由于需要动态传参数(大数据基础组建参数很多eg:hadoop config 4天王的参数配置项),我们引入了几个shell脚本,和定义了大量的参数,编写了大量sed 替换代码。解决上面的问题后,还需要考虑一个问题俩个服务必须在一个容器,这时候我们必须回到重新编译打包上传。我不知道后面维护这些dockerfile的同学会不会崩溃。至少做为作者的我隔了一周再去看这些代码,我体会到了。编写好docker后需要对容器进行编排,我们使用rancher的编排和调度。所以我需要对所有的服务器进行针对各个组建一一进行统一的标签化,eg:hdfs定义标签hd.role.namenode=true,hd.role.datanode=true,yarn定义标签yarn.role.rm=true,yarn.role.nm=true,etc,确保的服务能够正确的部署到我想要去的服务器。思考下图dockerfile中的服务如何才能更好在docker中进行管理和部署?如果还有其他的组件呢hive,hbase,kafka,zookeeper?
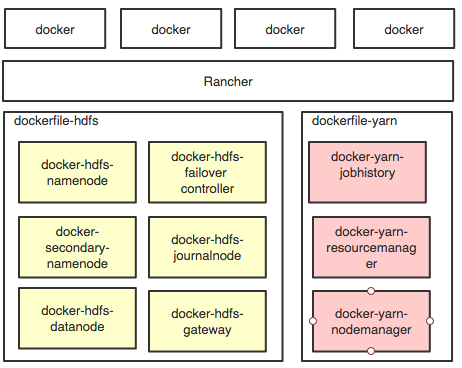
小结:上面的流程是一个最基本的在开发环境所需要考虑的问题,在线上生产环境,我还需要考虑到
- 管理
- 多集群管理
- 资源的统一管理
- 日志统一管理和搜索定位
- 节点健康检查
- 集群更改历史
- 部署
- 部署升级
- 配置调优和管理
- 多服务融合进当个docker角色管理
- 安全
- 对不同组建的不同指标的定义的监测整断
- 安全认证
- 报警
等等方面的因数。势必会存在单个docker对应多个服务。docker如何管理容器内的服务?这是我们还将思考的具体问题!
好了,对上面的所遇到的问题,我抽象成俩个问题。
- 通过rancher结合docker更好实现单个组件多个服务的编排,以及满足线上要求的服务与配置管理(eg:一个hdfs完成的组建有8个(namenode,secondarynamenode,datanode,journalnode,failover controller etc)
- 如何通过rancher集合docker更好管理多个组件组合的服务编排和以及满足线上要求的服务与配置管理。
- 架构方案的重构
在谈这之前,我们看看CLOUDERA MANAGER(CDM)
下图是cloudera manager架构
(https://www.cloudera.com/documentation/manager/5-1-x/Cloudera-Manager-Introduction/cm5i_primer.html)

Agent:安装在每台主机上。该代理负责启动和停止的过程,拆包配置,触发装置和监控主机。
Management Service:由一组执行各种监控,警报和报告功能角色的服务。
Database:存储配置和监视信息。通常情况下,多个逻辑数据库在一个或多个数据库服务器上运行。
Cloudera Repository:软件由Cloudera 管理分布存储库。
Clients:组要包含俩个
1)Admin Console - 基于Web的用户界面与管理员管理集群和Cloudera管理。
2)API - 与开发人员创建自定义的Cloudera Manager应用程序的API。
一句话总结下CDM:核心组建是Management Service,该服务承载管理控制台的Web服务器和应用程序逻辑,并负责安装软件,配置,启动和停止服务,以及管理上的服务运行群集。通过cdm管理management service,agent等自带的几个服务,能够完成单个组件对自生多个服务的管理,实际上cdm对大数据组件的管理方式,也是用了同样的一种方式。cdm将cloudera management service划分成一个类似hadoop集群来进行管理。cdm可以管理多个集群,集群间不互相影响,而且能够在单个集群下管理多个组件。下图是部署的截图。

通过对cdm的定位,架构,和功能了解,可以知道他可以解决我们管理单个组件的多个服务,管理多个组件之间的组合这俩个最根本痛点。而docker在快速部署,弥合环境环境差异有很好的表现,所以docker和rancher的定位仅仅只是快速帮助我们初始化服务器的基础环境 eg:初始化ssh,ntp等服务。也就是说,在基于现有的情况下,在大数据平台里面,docker和vm和宿主机的定位是一样的。ps:wiki上有篇《cloudera manager 功能调研和功能展示》,可以快速了解下cdm的功能。
通过对上面信息聚合,抽象成的部署架构图如下
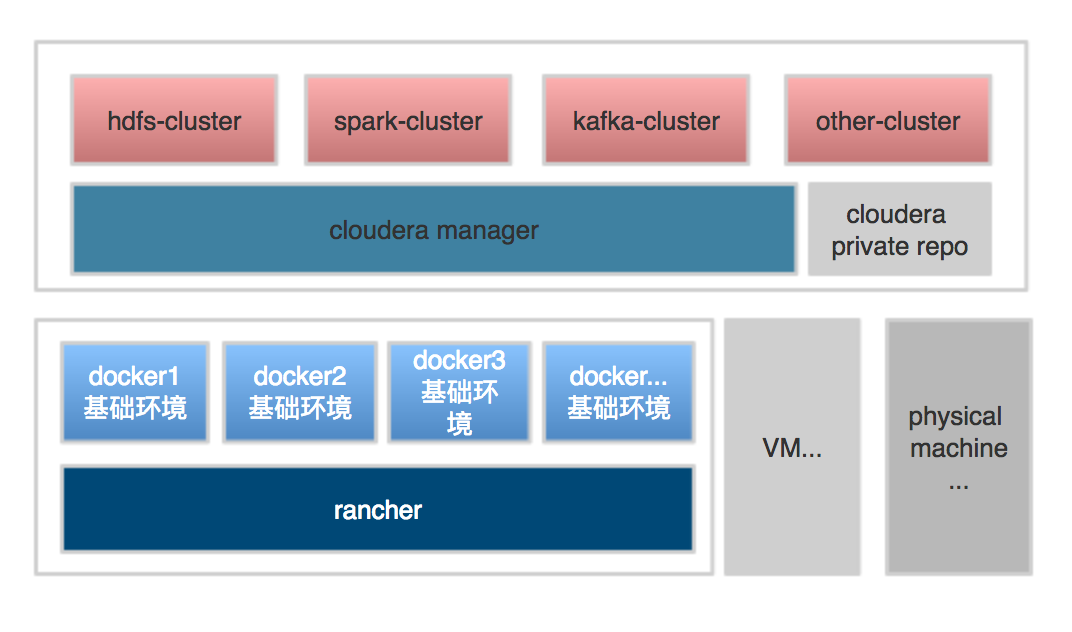
- rancher,只用于管理docker集群
- docker,只用于准备cdm,server和agent节点所需要的基础环境,eg:ntp,ssh等服务(不可否认用docker来搭建这些简单基础服务非常快捷方便),有rancher拉起多个docker节点,然后被cdm通过IP将docker节点纳入到基础资源中,用于部署大数据基础组件
- Cloudera manager用于用于部署大数据所需要的服务,在上面可以快速构建hdfs,spark,yarn等集群,而且能够很好处理组件之间的组合,eg:hdfs-yarn

4. Cloudera private repo,搭建安装所需要的私服
对应的实际的环境中部署架构
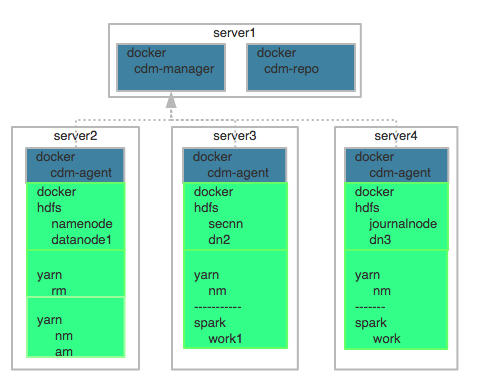
如图,这边我们启动了8个docker,其中3个cdm-agent,3个用于部署大数据组建
在rancher的大数据环境上我已经部署了服务fino-cdm-cluster。Cloudera manager web:http://118.89.65.168:7180。用户和密码:admin/admin。由于服务器的资源实在实在是太少了,某些服务起不来,导致一些错误eg:查询 Host Monitor 时发生内部错误。
- 遗留的问题
- 在第三点,我们根据在部署上的痛点,针对性提出了解决方案,解决了部署大数据组件的繁琐,和引入docker所带来的部署难度提升,解决在针对大数据组件的监控,管理等运维上的繁杂,让开发人员从大量的dockerfile中脱离,能够更加专心应对集群上的问题,和业务上的问题。但是影响一个项目交付成本,除了上面的一些内容外,结合docker性能优化这块是重中之重,需要进行长期探索。从本地文件系统的选择,内存参数设置,网络方式选择和参数,CPU参数设置,
- hadoop,spark等大数据组件的服务需要常驻。也就是说docker不能运算结束后销毁。eg:client 提交任务yarn,yarn根据docker所占剩余的资源,进行任务的分配。在docker中以若干linux container的形式存在。如果抛去第三点我对docker使用进行反常规使用。社区上有人提到那docker又能给大数据平台带来哪些改变?画个图慢慢思考,哈哈~
