前言
在我们的日常工作中,有时候会遇到这种需求,就是需要不停的刷新当前页面,看看是否有变化,但是又不想手动去刷新。
当然了,在浏览器的开发者工具里面点击拓展,会发现有一些现成的工具,但是不一定好用,而且很难同时刷新多个网页。因此本篇博客利用python编写了31行代码,可实现上述功能
优势:
- 运行简单,只需要配置好了python环境
- 可同时刷新多个网页
- 刷新的时间间隔可随机,时长可自己设置
- 甚至不需要打开浏览器
正文
代码我已经给了相关的注释,你只需要做两件事。
第一: 创建一个txt文档用于保存你所需要刷新的网页。(源代码中,txt文件名默认是web.txt,无论是否修改了,请记得保持一致)
第二: 将代码复制到python的编译器中直接运行即可。
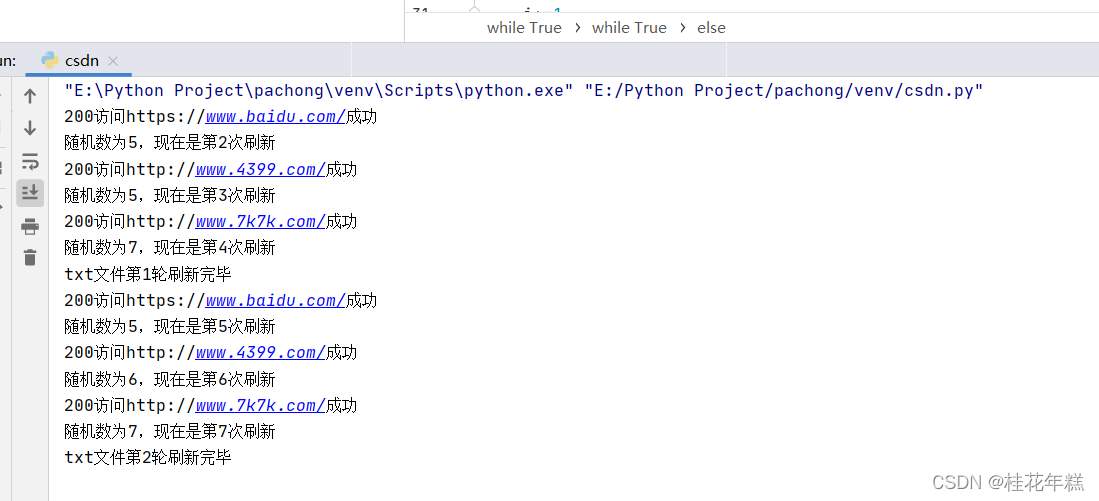
具体代码和演示效果如下:
import requests #访问网页所必须用到的头文件
from bs4 import BeautifulSoup #访问网页所必须用到的头文件
import time #用于控制访问间隔
import random #用于生成一个随机数
i=1 #记录下当前是第几轮(在刷新多个网页时可以看到)
count=1; #记录下当前总共刷新了多少次
while True:
file=open('web.txt', 'r',encoding='utf-8',errors='ignore')
while True:
url=file.readline().rstrip()
header={
"user-agent":"Mozilla/5.0"}
try:
data=requests.get(url=url,headers=header)
except ValueError:
break
else:
print(data.status_code,end='')
if(data.status_code == 200):
print(f"访问{
url}成功")
else:
print(f"访问{
url}失败")
k=random.randint(5, 10); #生成一个5-10s的随机数 可以自己调整
time.sleep(k)
count+=1;
print(f"随机数为{
k},现在是第{
count}次刷新");
file.close()
print(f"txt文件第{
i}轮刷新完毕")
time.sleep(30) #防止被网页认出你是恶意刷新,当然可以修改
i+=1

补充
如果不想随机刷新的话,可以把随机数去掉,另外,刷新间隔可以自己调整,第30行代码去掉也没关系。
最后
如果觉得对你有所帮助的话,希望能点赞收藏一波,您的鼓励就是对我最大的支持,谢谢!