容量规划离不开对业务场景的分析,分析出场景后,就要对这些场景进行模拟,也就是容量的压力测试,用来真实地验证系统容量和性能是否可以满足极端业务场景下的要求。同时,在这个过程中还要对容量不断进行扩缩容调整,以及系统的性能优化。
一、压测粒度
1.单机单应用压力测试
优先摸清单个应用的访问模型是怎样的,再根据模型进行单机单应用压力测试。这时我们就可以拿到单个应用和单个应用集群的容量水位,这个值就是后续我们根据业务模型分析之后扩容的基础。
2.单链路压力测试
获取到单个应用集群的容量水位之后,就要开始对某些核心链路进行单独的压力测试,比如商品详情浏览链路、加购物车链路、订购下单链路等等。
3.多链路 / 全链路压力测试
当单链路的压测都达标之后,我们就会组织多链路,或者全链路压测。多链路本质上就是多个单链路的组合,全链路就是多链路的组合。
二、压测接口及流量构造方式
1.线上流量回放
这种方式直接利用了线上流量模型,比较接近真实业务场景,常见的技术手段如 TCPCopy,或者 Tcpdump 抓包保存线上请求流量。但是这种方式也存在一些代价,比如需要镜像请求流量,当线上流量非常大的时候就很难全部镜像下来,而且还需要大量额外的机器来保存流量镜像。到了回放阶段,还需要一些自动化的工具来支持,还要解决各种 session 问题,真正实施的时候,还是会有不少的工作量。
2.线上流量引流
压测的主要是 HTTP 和 RPC 两种类型的接口,为了保证单个应用的流量压力足够大,这里可以采取两种模式。
一个是将应用集群中的流量逐步引流到一台主机上,直到达到其容量阈值;另一个方案是,可以通过修改负载均衡中某台主机的权重,将更多的流量直接打到某台主机上,直到达到其容量阈值。
这个过程中,可以设定单台主机的 CPU、Load 或者 QPS、RT 等阈值指标,当指标超出正常阈值后就自动终止压测,这样就可以获取到初步的容量值。这种方式的好处是,不需要额外的流量模拟,直接使用最真实的线上流量,操作方便,且更加真实。下图是两种引流的方案示例。
3.流量模拟
上述两种流量模拟方式,更适合日常单机单应用的容量压测和规划,但是对于大促这种极端业务场景,真实流量就很难模拟了,因为这种场景只有特定时刻才会有,我们在日常是无法通过线上流量构造出来的。
所以这里就需要利用数据工厂,最终通过流量平台来形成压测流量。这里的工具用到了 Gatling,是一款开源的压测工具,用 Scala 开发的,后来我们针对自己的需求,比如自动生成压测脚本等,做了一些二次开发。

如果会有多种流量模型的话,就要生成多个流量模型,具体可见下图:
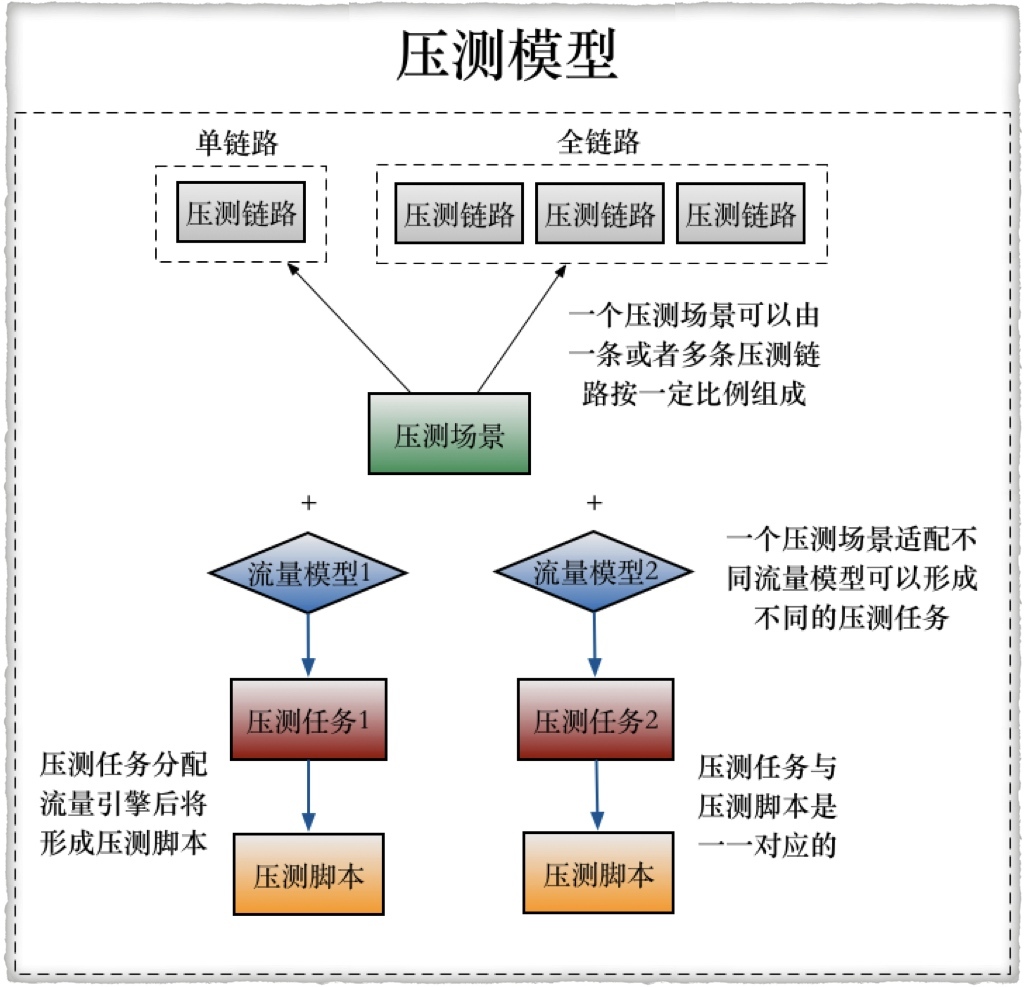
三、施压方式
施压方式是通过上百台的机器根据压测脚本和压测数据对系统施压的。
1. 通过实现在 Web 控制台配置好的压测场景,自动生成压测脚本。
2. 利用数据工厂构造出压测数据,这个就是业务场景的模拟,像阿里做得比较完善,就可以借助 AI 和 BI 的技术手段生成很多压测模型,且基本都接近于现实情况下的业务场景。
3. 通过 Web 控制台,根据压测脚本和压测数据,生成压测任务,推送到压测集群的 Master 节点,再通过 Master 节点推动到上百台的 Slave 节点,然后就开始向线上系统施加模拟的流量压力了。
关于施压机的分布,大部分仍然是跟线上系统在同机房内,少量会在公有云节点上。但是对于阿里这样的企业,因为其自身的 CDN 节点遍布全球,所以他就可以将全球(主要是国内)的 CDN 节点作为施压机,更加真实地模拟真实用户从全球节点进入的真实访问流量。
四、数据读写
压测过程中,对于读的流量更好构造,因为读请求本身不会对线上数据造成任何变更,但是对于写流量就完全不一样了,如果处理不好,会对线上数据造成污染,对商家和用户造成资损。
所以,对于写流量就要特殊处理,这块也有比较通用的解决方案,就是对压测的写请求做专门的标记。当请求要写数据库时,由分布式数据库的中间件框架中的逻辑来判断这个请求是否是压测请求,如果是压测写请求则路由到对应的影子库中,而不是直接写到线上正式的库中。
此文章为4月Day7 学习笔记,内容来源于极客时间《赵成的运维体系管理课》,推荐该课程。