第一节描述了kubernetes的基本角色和组件功能,这一节主要描述kubernetes内部的资源描述和层级关系。
kubernetes在v1.2之后引入了一个Deployment的概念,主要用来描述kubernetes内部资源的生命周期。
对此,首先要认识一个最基本的事实,kubernetes是一个容器编排平台,最后用户的服务落地时必然以容器的形式存在,但kubernetes在容器之上抽象了一些新的诸如pod, RC,service的概念,下图主要揭示各种类型资源之间的关系。
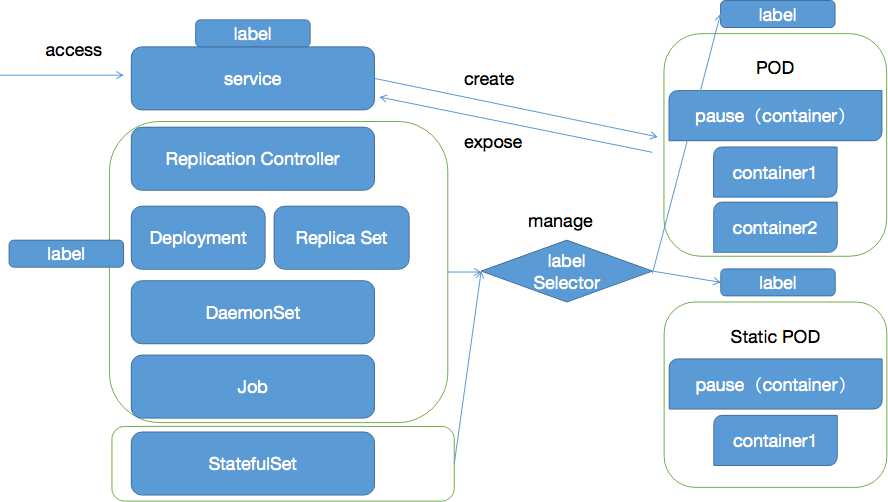
为了理解上述图谱,首先要理解两个概念:POD和LABEL。
上述图谱中,一个pod通常又一个pause容器加一系列用户容器组合而成。那么为何要这样设定呢?原因主要有两个:
1)用户定义了一系列容器组作为一个对外服务的整体,那么其中一部分容器挂死后怎样描述这个服务的状态?是部分可用吗?还是全部不可用?如果引入pause这个与业务无关且不易死亡的容器作为判断服务可用性的标准就简化了这个问题——pause活着即可用,死掉就不可用
2)这些pod内部的用户容器会共享pause容器的网络协议栈以及存储卷,可以简化pod内部的通信问题和文件共享问题
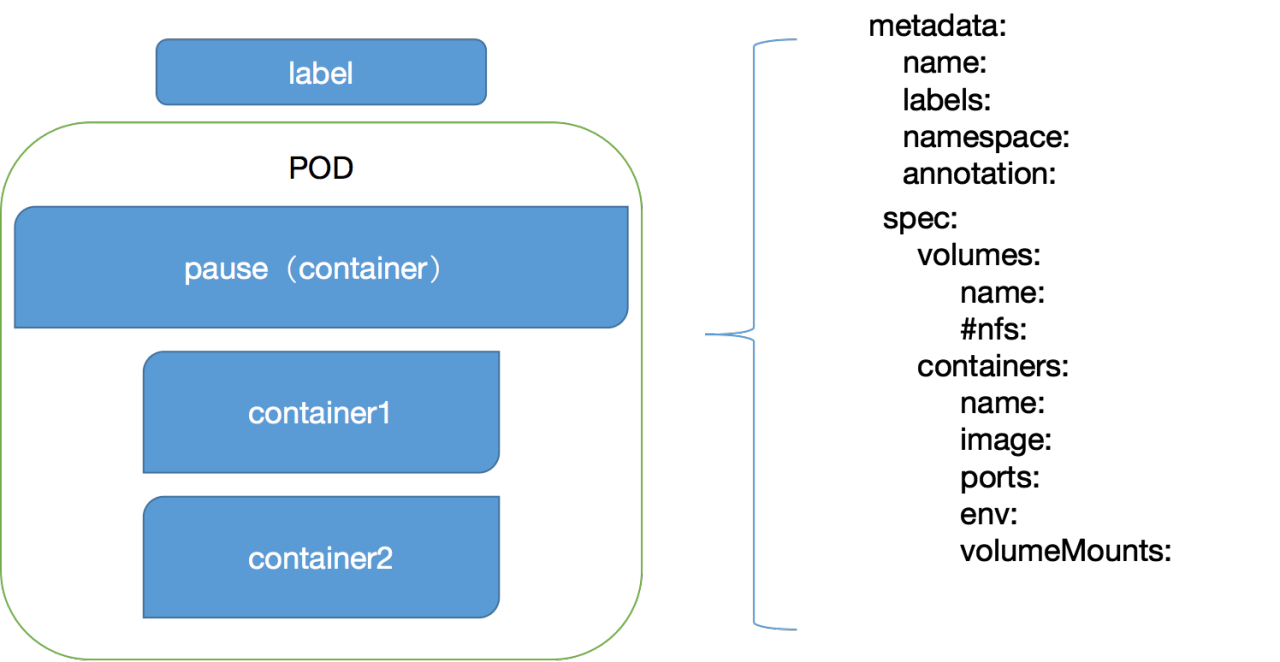
一个pod的定义主要分为两部分,一个是自身的定义,包括名字和标签等,另外一个是它的配置信息,如选择什么卷,镜像。
因为提到了卷,不得不提一下另外两个资源类型,一个是Volume,一个是Persistent Volume。PV主要和PVC联合使用,需要在POD之外声明。如果要使用,则需要在POD里面的volumes里面引用即可。它的调用链是PV声明存储空间的配置,PersistentVolumeClaim则需要定义用来申请该PV,他们直接的关联关系实验下来是按照空间大小来进行匹配的(如果多个pv大小一致怎么办?目前没有验证过),pod在volumes的引用该pvc即可。
需要注意的是该volume和docker的volume是不等价的。kubernetes内的volume定义在pod里面,被pod内的多个容器挂载到具体的目录下面,并且生命周期和pod是一致的,但生命周期和docker容器并不一致,但容器挂死后volume内的数据不会丢失。
除了共享存储外,pod还提供了共享网络协议栈,一方面保证pod内部的容器通信无障碍,另一方面保证了多个pod直接的网络协议栈不冲突的同时还能提供互相访问功能。
网络参数并没有在pod的配置里面具体体现(其实有,比如使用host网络),实际上依赖的是cni(container network interface),目前默认的网络模型是IP-Per-Pod模型,即一个pod获取一个IP地址,需要事先了解的是同一个节点上的pod的ip是从该节点的docker0网桥上面动态获取的,不同节点上的pod的ip地址也不相同,所以为了避免这种情况,需要一种机制保证kubernetes在创建时node节点的docker0网桥的ip也不能一样,还需要动态维护一个键值对,将pod的ip维护起来。目前默认使用的网络模型是flannel。
————————————————————————
了解为最基本的资源单位pod后,还需要了解一些它的上层控制类型的资源,主要分为两大类有状态资源(statefulset)和无状态资源(RC,Deployment,Job等)
首先要区分一下有状态和无状态两个概念。针对注入mysql,zookeeper集群这种
1)集群内部的节点的身份都是不一样的,集群内的成员可以通过这种身份实现互相发现和通信
2)集群规模固定,不能随意变动
3)集群内部节点有状态,需要持久化数据到永久存储中
4)节点异常可能导致集群功能异常
无状态则没有这种问题:
1)集群内部的节点全部对等,没有主从角色
2)集群内部的节点增删不会影响集群的功能
3)集群内部的节点通信和发现由外部组件控制
这样描述后,statefulset主要提供了有状态服务的配置,如RC,Deployment,实际上完成的是pod的副本数、生命周期、亲和性的管理。
在较早期的版本中,RC负责了如下几个主要功能:
1)Pod的副本数
2)筛选pod的目标node,LabelSelector
3)定义pod的模板,用于创建目标副本数的pod
在kubernetes版本演进的过程中,由Replica Set代替了RC的功能,他们之间的区别是,RC的LabelSelector是基于等式选择的,Replica Set则是基于集合的。
但目前很少直接使用Replica Set,通常都是由更高级的资源对象Deployment来负责统一编排。这个功能在服务灰度发布、回滚、弹缩时体现得比较明显,后面会展开描述。
对于Deployment,它最大的价值是展示了pod的部署进度,目前有如下几种场景:
1)生成Replica Set来完成pod的创建
2)检查Deployment的状态来确定pod的状态
3)通过更新Deployment来升级、回滚、挂起、恢复POD
4) 动态扩缩容,通常和HPA(Horizontal Pod AutoScaler)这个资源对象一起配合使用
5)清理旧版本RS
最后一个是DaemonSet,但需要在下面的label的概念讲完之后才能详细描述它。
——————————————————————————————————
描述完有状态和无状态后,还需要描述一个非常重要的概念label和annotation。
label和annotation都是键值对,label可以附加到诸如Node,Pod,Service,RC等资源对象上面,所以RC和RS的差异主要体现在键值对的筛选模式上面,如果是RC,则按照 a=b, c!=d这种模式筛选,而RS则可以按照 a in (b, c), d not in (f)这种模式进行筛选。
目前labelselector主要在一下的几种场景中使用:
1)kube-controller通过RC上定义的label selector来筛选要监控的pod的副本数,是的pod的数量始终符合预期
2)kube-proxy通过service的label selector来选择相应的pod自动建立service对应pod的请求转发路由表,从而实现service的访问的负载均衡
3)对于node定义的label,并在pod里面定义的 nodeselector这种标签调度策略,kube-scheduler可以实现pod的定向调度
annotation虽然也是键值对,但它的定义规则不如label,它主要提供给外部工具查找,这种类似注解的信息通常包括:配置信息、版本信息、开发负责人之类的内容
现在回过头来描述DaemonSet,它实际上和RC/Deployment等属于一种调度类型,不同的是后者有可能在同一个node上面运行多份pod副本,但DaemonSet不会,DaemonSet只会在一个节点上起一个副本的Pod,所以DaemonSet常常和label联合起来使用,将一些特定的服务存储、日志采集、监控这样的服务部署在节点上面,当然了它也可以单独使用,无须和label selector联合。
最后一个资源对象即Job,后续和cronjob一起展开描述。