最近接到一个需求,需要准备大量的音频,其中需要自己录制的音频进行处理。
Python模块:PyAudio PyAudio · PyPI
安装方法: pipwin install pyaudio
注:pipwin 安装时有时会因为网络超时,导致安装失败。可以更换安装源。
录制音频基础代码如下:
def audio_record(slef, file_name, rec_time):
chunk = 1024
formate = pyaudio.paInt16 #16bit编码格式(2个字节)
channels = 1 #单声道
rate = 16000 #采样率
p = pyaudio.PyAudio()
stream = p.open(format = formate,
channels= channels,
rate =rate,
input= True,
frames_per_buffer=chunk)
print("开始录制")
#录制的音频数据
frames = []
for i in range(0, int(rate / chunk * rec_time)):
data = stream.read(chunk)
frames.append(data)
#录制完成
stream.stop_stream()
stream.close()
p.terminate()
print("完成录制")
# wave是录音时用的标准的WINDOWS文件格式,文件的扩展名为WAV
# 保存录音
file = wave.open(file_name, "wb")
file.setnchannels(channels)
file.setsampwidth(p.get_sample_size(formate)) #或者sampwidth=2(2个字节16位); file.setsampwidth(sampwidth)
file.setframerate(rate) #帧速率
file.writeframes(b''.join(frames)) #把数据加进去,存到硬盘中
file.close()音频相关理解:
现实生活中,我们听到的声音都是时间连续的,我们称为这种信号叫模拟信号。模拟信号需要进行数字化以后才能在计算机中使用。
声音处理过程:
采样(将下图中一段音频模拟信息信号转换为数字信号)----> 量化(每个样本的大小)----> 二进制编码
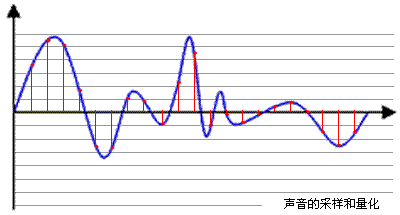
采样率rate:
采样率:1s采集多少次声音,也是所得的数字信号的每秒样本数。采样率越高,声音的还原就越真实自然,但同时它占的资源比较多。常见有 16000、44100
采样位数formate:
而采样位数是指声卡在播放时所使用数字信号的二进制位数,代表声卡处理声音的解析度,客观地反映了数字信号对输入信号描述的准确程度。
简单来讲,就是代表每个采样点(上图中小红点)的大小。一般有8,16可选, 这个数值越大,解析度就越高,声音越真实。
8位代表2的8次方——256,16位则代表2的16次方——64K。比较一下,一段相同的音乐信息
16位声卡能把它分为64K个精度单位进行处理,而8位声卡只能处理256个精度单位,这会造成较
大的信号损失,所以最终的采样效果自然是采样位数越高越好
帧frame per buffer:
音频在量化得到二进制的码字后,需要进行变换,而变换是以块为单位(block)进行的,一个块由多个(120或128)样本组成。而一帧内会包含一个或者多个块。帧的常见大小有960、1024、2048、4096等。一帧记录了一个声音单元,它的长度是样本长度和声道数的乘积。不同的编码方式帧不同,比如AAC规定1024采样sample,mp3为1152采样。
比如:
一个AAC原始帧包含一段时间内1024个采样及相关数据
假如:音频总时长为5s
一个音频帧的时间 = 一个AAC帧对应的采样样本的个数/采样频率
= 1024 / 16000 * 1000 = 64ms
音频总帧数 = 音频总时长time / 一个音频帧的时间 = 5000 / 64 =78.125
音频总帧数 = 采样率rate * 音频总时长time / 帧 frame per buffer
= 音频总采样数 / 每帧采样数
= 16000 * 5 / 1024 = 78.125
单位: 秒