背景介绍
项目采用分布式框架(Dubbo、Zookeeper)进行开发,项目初期,为了按计划上线就没有搭建日志收集分析平台,日志都保存在各个服务器本地。随着项目推进,基础服务越来越多,各个服务都是集群部署,服务器的数量也快速增长,此时就暴露出了很多的问题:
- 问题排查困难,查询一个服务的日志,需要登录多台服务器;
- 日志串接困难,一个流程有多个节点,要把整个流程的日志串接起来工作量大;
- 运维管理困难,不是每个同事都有登录服务器查看日志的权限,但又需要根据日志排查问题,就需要有权限的同事下载日志后给到相应负责的同事。
- 系统预警困难,无法实现服务出现异常后,及时通知到相应的负责人。
所以需要搭建一套集中式的日志收集、存储、分析系统,将所有节点的日志统一收集、管理。
经技术调研,ELK提供了一套解决方案,能解决上述问题,下面简单介绍一下ELK。
一、ELK简介
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana ,
- Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等
- Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
- Kibana可以为 Logstash 和 ElasticSearch 通过报表、图形化数据进行可视化展示 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
二、解决方案分析:
方案一:
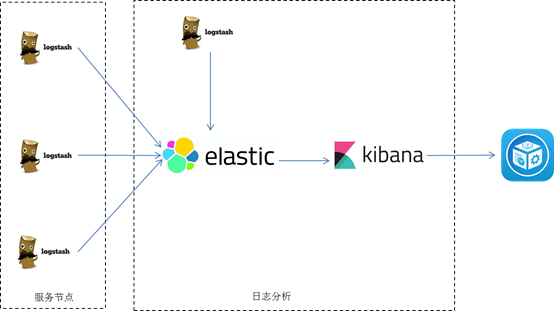
Logstash部署到每个节点,收集相关的日志,并经过分析过滤后发送到Elasticsearch进行存储,Elasticsearch将数据以分片的形式压缩存储,通过kibana对日志进行图形化的展示,
优点:此架构搭建简单,容易上手
缺点:1、每个节点部署logstash,运行时占用CUP、内存大,会对节点性能造成一定的影响;
2、没有将日志数据进行缓存,存在丢失的风险。
方案二:
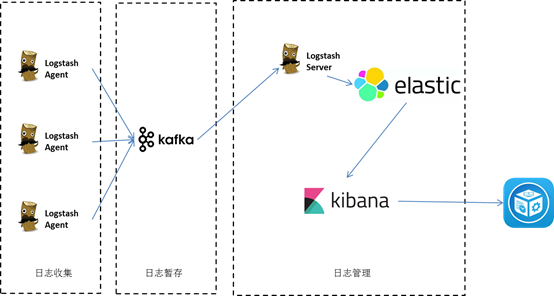
logstash agent 监控并过滤日志,将过滤的日志内容发给 kafka或redis,logstashServer 将日志收集一起交给elasticsearch。引入了消息队列机制作为缓存池,即使logstashServer出现异常,由于日志暂存在kafaka消息队列中,能避免日志数据丢失,但是还是没有解决性能问题。
方案三:
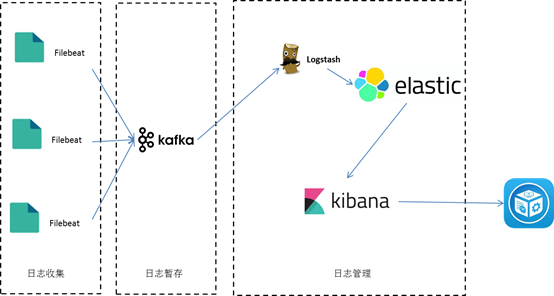
Filebeat是一个日志文件托运工具,做为一个agent安装到服务器上,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件;
将filebeat 作为日志收集器,相比logstach,filebeat更轻量,占用资源更少,filebeat采集日志后,发送到消息队列kafaka或redis暂存起来,起到一个缓冲池的作用,能缓解日志峰值处理压力;
然后logstash去消息队列中获取,利用filter功能过滤分析,然后存储到elasticsearch中,再通过kibana图形化直观展示。缺点就是部署较复杂,如果是正式环境还要考虑集群部署,避免单点。
该选择哪个方案需根据项目实际情况考虑,没有最完美的方案,只有最适合的方案。