1:查询表中的若干列
(1)查询全部列
例1:从students表中查询全体学生的详细记录。(两种写法都可以)
select * from students;
select id,sex,name,age,department from students;(2)查询经过计算的值
例:从students表中查询全体学生的姓名以及出生年份。
由于目前只知道学生的年龄,要显示学生的出生年份,只需要将当前年份减去学生的年龄即可得出学生的出生年份。
select name,2022-age from students;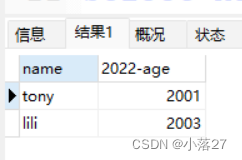
例:从students表中查询全体学生的姓名,出生年份和所在院系,要求用小写字母表示系名。
前面我们知道了怎么显示出生年份,现在需要知道怎么显示将所有的字母都用小写字母显示出来。
lower(字段名)----将所有的英文字母变成小写、upper(字段名)---将所有的英文字母转换成大写。
select name,2022-age,lower(department) from students;
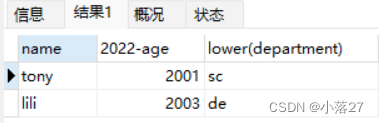
此外。还可以通过取别名的方式,使得查询的结果显示的更加清楚。
取别名的格式: 字段名+空格或者as+要显示的名称。
以下我将2022-age取名为birth,将lower(department)取名为department。为了区分两种情况都可以,我将2022-age 用as的形式取别名,lower(deparment)用空格的形式取别名。
select name ,2022-age as birth,lower(department) department from students;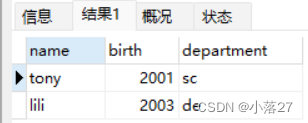
2:查询表中的若干元组
(1)消除值重复的元组(消除重复的行),这里只需要用到distinct关键字即可消除重复行。
例:从students表中查询年龄不同的学生。
select distinct age from students;
(2)查询满足条件的元组(满足条件的行/记录)
1:<>和!=是同样的意思:不等于
2:取值在某个范围应该使用:between a and b (在a和b之间,包括了a和b) 或者 not between a and b(不在a和b之间)
例:从students表中查询性别为男的学生姓名。(以下三种查询的结果均相同)
select name from students where sex = '男';
select name from students where sex != '女';
select name from students where sex <>'女';当属性值确定的时候,可以用in/not in来查找属性值属于指定集合的元组。
例:从students表中查找计算机科学系(cs),数学系(ma),信息系(is)的学生姓名和性别。
select name,sex from students where department in ('cs','ma','is');想要查找只包含某个字符的所有元组:用like来进行字符串的匹配。
例:从students表中查找姓刘的学生的姓名(name),学号(id)和性别(sex)。
select name,id,sex from students where name like '刘%';字符串的匹配:用到的词是like,字符串,因此like后要接英文单引号。
%(百分号):代表任意长度的字符串(长度可以为0),_(下横线):表示任意单个字符,注意:当数据库字符集为ASCII时一个汉字需要两个__,当字符集为GBK时,一个汉字只需要一个_。
举例:a%b:表示以a开头,以b结尾的任意长度的字符串。
因此上面的例题要查找姓刘的学生,就只需要查找姓名以刘开头的字符串,即 name like '刘%'。
例:从students表中查询姓名为"欧阳"且全名为三个汉字的学生姓名。
select name from students where name like '欧阳_';注意看这句话:当数据库字符集为ASCII时一个汉字需要两个__,当字符集为GBK时,一个汉字只需要一个_。
例:从Course表中查询DB_Design课程的课程号(Cid)和学分(credit)。
select Cid,credit from Course where name like 'DB\_Design' escape'\';escape ' \ ' 表示' \ '为换码字符,将DB_Design中的_ 转义成普通的_。
例:从Course表中查询以DB_开头,且倒数第三个字符为i的课程情况。
select * from Course where name like'DB\_%i_ _' escape '\' ;这里只需要将DB后面的_转义成普通字符就可以了,而i后面的_均为普通的_。
判断某个属性中是否含有空值,只能用is null 或者is not null。
例:从students表中查询学生的成绩(grade)为空的学号。
select id from students where grade is null;多重条件查询:用逻辑运算符AND和OR连接,AND的优先级高于OR,通过括号可以改变优先级。
例:从students表中查找年龄在16-20岁之间且性别为女的学生姓名和年龄。
select name, age from students where age between 16 and 20 and sex = '女';3:order by 字句
order by 字句用于对查询结果进行升序(asc)或降序(desc)排序,默认是升序排列。对于空值的排序,具体由系统决定。
例:从students表中查找姓名和年龄,按年龄降序,学号升序排列。
select name,age from students
order by id,age desc;4:聚合函数
为了增强索引功能,SQL提供了多种聚合函数,主要有:
①:count()----统计元组的个数(或一列中值的个数),例:统计(成绩大于60的)人数
②:sum()----计算一列值的总和,例:计算学生的总成绩
③:avg()----计算一列值的平均值,例:计算(计算机系的)学生的平均成绩
④:max()----计算一列的值的最大值,例:查询学生中,年龄最大的值
⑤:min()----计算一列的值最小值,例:查询成绩的最低分(前提是不为0)
注意:(1):当聚合函数遇到空值时,除了count(*)外,都跳过空值只处理非空值。(2):聚合函数只能用于select子句和group by 子句中的having子句中。
例:从students表中查询性别为男的年龄的最大值的姓名,性别和年龄。
select name,sex,max(age) from students where sex = '男';5:group by 子句
group by 子句是将查询结果按照某一列或多列的值进行分组,值相等的为一组。
group by 子句后面可以接having短语,having短语后接聚合函数,用于给分组以后的数据进行处理。注意:where 子句作用于基本表或视图,从中选择满足条件的元组,而having 短语作用于组,从中选择满足条件的组。
例:从学生选课表(student_class)中查询平均成绩大于90分的学生学号和平均成绩。
先查询学生的平均成绩,按照学号进行分组,再在组中找到平均成绩大于90的学生。
select id , avg(grade)
from student_class
group by id
having avg(grade) >= 90;以上是我个人对数据库单表查询的笔记编写,例题也是我个人认为值得掌握的例题,也不要仅限我掌握我的那些例题,想要掌握好,当然还是要多动手,多练习,大家一起加油吧~