这里写目录标题
参考
1.聊一聊CV中的backbone结构
2.人人都爱(玩)Backbone(1)
3.Backbone发展与语义分割网络发展
4.深度学习框架-Backbone汇总
5.关于卷积神经网络(CNN)骨干结构的思考
6.神经网络的Backbone
常用结构
backbone主要包括:
VGG、ResNet(ResNet18,50,100)、ResNeXt、DenseNet、SqueezeNet、Darknet(Darknet19,53)、MobileNet、ShuffleNet、DetNet、DetNAS、SpineNet、EfficientNet(EfficientNet-B0/B7)、CSPResNeXt50、CSPDarknet53;
head
one-stage:RPN、SSD、YOLO、RetinaNet、CornerNet、CenterNet、MatrixNet、FCOS;
two-stage:Faster R-CNN、R-FCN、Mask RCNN (anchor based)、RepPoints(anchor free);
neck
SPP、ASPP、RFB、FPN、NAS-FPN、Fully-connected FPN、BiFPN等;
backbone
- 在神经网络中,尤其是CV领域,一般先对图像进行特征提取(常见的有vggnet,resnet,谷歌的inception),这一部分是整个CV任务的根基,因为后续的下游任务都是基于提取出来的图像特征去做文章(比如分类,生成等等)。
解释:主干网络(提取特征的网络)
**作用:一般先对图像进行特征提取(**常见的有vggnet,resnet,谷歌的inception),生成特征图feature map,供后面的网络使用,
这一部分是整个CV任务的根基,因为后续的下游任务都是基于提取出来的图像特征去做文章(比如分类,生成等等)。
这些网络经常使用的是resnet VGG等,而不是我们自己设计的网络,因为这些网络已经证明了在分类等问题上的特征提取能力是很强的。
在用这些网络作为backbone的时候,都是直接加载官方已经训练好的模型参数,后面接着我们自己的网络。
让网络的这两个部分同时进行训练,因为加载的backbone模型已经具有提取特征的能力了,在我们的训练过程中,会对他进行微调,使得其更适合于我们自己的任务
具体解释使用
理解抽象
用抽象的方法,把算法简洁明了的说明和对比,目的不是为了说明算法的细节,而是从算法的思想上去解析算法的演化流程和特点,以及贡献点。
这样分析大家也会就会明白,Backbone会如何给不同的算法提供Feature,不同算法的会从不同的角度去挖掘(玩)Feature中的信息。


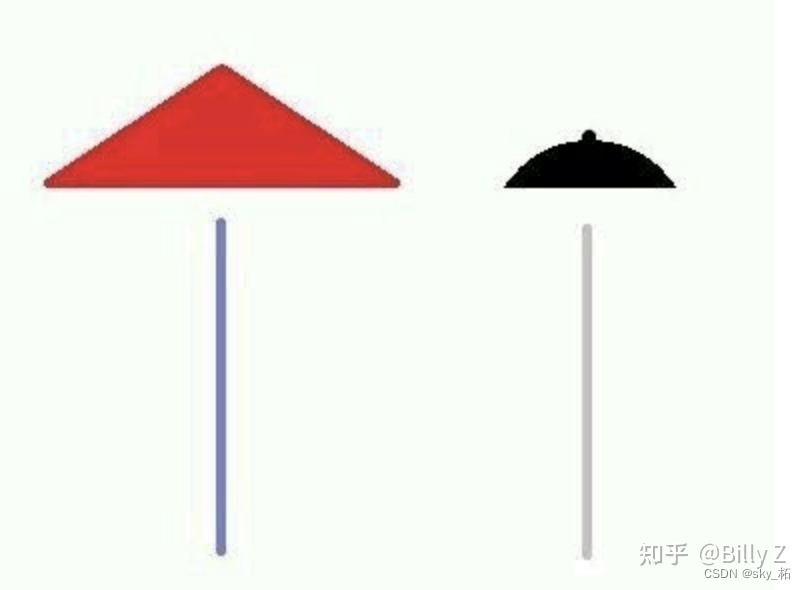
虽然这些图这么的抽象,但是不不耽误大家能认出这个图是在描绘哪个片段。
抽象其实不耽误大家对于一个事情本质的了解,甚至能加深了解
那怎么把不同算法中的Backbone给抽象出来呢,请看下图:

把”帽子”当做 Backbone,然后只把Backbone看做一个无情的提取Feature的机器,
那么顺理成章,Head就可以看成Backbone的前处理,Neck和Tail可以看成Backbone后处理。
梳理下来,很多算法的创新点就在Head/Neck/Tail上。
参考目标检测
《目标检测》-第2章-Backbone与Detection head
前面提到了backbone网络这一字眼,所谓的backbone,直接翻译过来就是“骨干”,很明显,这个单词的含义就表明了它并不是整体的网络。既然两个任务具有相似性,再加之迁移学习思想的普及,为什么还会要用这么个单词来描述它呢?事实上,尽管OD和图像分类两个任务具有相似性,但不完全是等价的,OD的目标是实现对物体的定位和分类,而图像分类仅仅是对图像中的物体进行分类,而不会去定位。于是,就在“定位”这一点上,完全将分类网络搬过来使用显然是不恰当的
(准确来说,是将ImageNet上训练的参数直接加载进来,作为初始参数再去微调是不恰当,而不是网络模型本身,网络模型本身只是个架构,完全可以随机初始化去训练的。因为在ImageNet上训练出来的参数已经掉进了分类任务的一个局部最优点,那么在不改变现有模型任何架构——不增加网络层也不删减网络层——的情况下,通这种局部最优点在OD任务上是否合适呢?或者说,模型能通过微调就跳出这个“旧”的极值点走进“新”的极值点吗?我难以下个普适的定论。仅根据我个人的经验,这个过程比较困难。)。
解决的办法相当简单,既然仅仅靠分类网络的参数是不行的,但是我们还需要它(那时候的数据量和训练tricks还不足以有效支撑train from scratch),那么我们就在后面加一些(训练时随机初始化的)网络层,让这些额外加进来的网络层去弥补分类网络无法定位的先天缺陷。
于是,这条脉络就非常清晰了:
分类网络迁移过来,用作特征提取器,后续的网络负责从这些特征中,检测目标的位置和类别。当然,两部分会合到一起在OD数据集上去训练,使得它提取出来的特征更适合OD任务
那么,我们就将分类网络所在的环节称之为“Backbone”也就是情理之中的了。而后续连接的网络层由于主要是服务于detection任务,因此称之为“Detection head”。
(在backbone这一部分,花些心思和功夫,倒也能够在顶会上做出些工作。只是,目前来看,手里没有太多卡的话,还是不推荐了。)
随着技术的发展,除了backbone和head这两部分,更多的新奇的技术和模块被提了出来,最著名的,莫过于FPN了——《Feature Pyramid NetworksforObject Detection》提出的FPN结构,在不同的尺度(实际上就是不同大小的feature map)上去提取不同尺度的信息,并进行融合,充分利用好backbone提取的所有的特征信息,从而让网络能够更好地检测物体。有了FPN,backbone提取出的信息可以被利用的更加充分,使得detector能够很好地应对多尺度情况——图像中,目标的大小不一,大的、中等的、小的,都有,尤其是小物体,几乎成为了目标检测这一块的单独研究点。
FPN之后的各种变体也很多,如BiFPN、NAS-FPN以及PAN等等,都极大促进了detector在应对目标尺寸多变问题上的性能。
除了FPN这种新颖的结构,还有诸如ASFF、RFB、SPP等好用的模块,都可以插在backbone和detection head之间。由于其插入的位置的微妙,故而将其称之为**“neck”**,有些文章中直接把它翻译成“瓶颈”或“脖子”,无论哪种翻译,都怪怪的,没内味儿……neck这部分的作用就是更好地融合/提取backbone所给出的feature,然后再交由后续的head去检测,从而提高网络的性能。
因此,现在一个完整的目标检测网络主要由三部分构成:
detector=backbone+neck+head
目前的话,neck这一部分的研究点还是相对来说比较多的,只需要提出一个好的结构或模块,加到现有的sota的网络中,看涨不涨点,涨点了,那就可以发文章了(此类增量式工作也是很有价值的,不断扩充OD领域的武器库,手里家伙多了,收拾“敌人”的手段也就五花八门了)~
而head这一部分,它的作用上面也说到了,就是分类+定位的,结构没什么新颖的,(就我所知)研究的似乎也比较少。
最后再说一点backbone。
有了充足的数据量,似乎Pretrain on ImageNet就不是必需环节了,迁移+微调也可以省掉了。于是,train from scratch的路线就回来了。注意,这里用的是“回来”,因为这一路线是很朴素的,甚至不值得挂在嘴边。网络参数随机初始化去训练本就是个基本操作,而imagenet pretrained model能在OD领域中盛行,主要还是因为OD本身数据就不够,外加大家还有点舍不得ImageNet这么丰富的图像数据库。当然,也是因为不是每个人都有足够的算力去支撑train from scratch的,这点是不容忽视的~
尽管现在学术界已经知道了不用那些在ImageNet上预训练的模型作为backbone,而是自己搭建backbone网络或者使用随机初始化的分类网络,也能够达到同样的效果,但是这样的代价就是需要花更多的实践来训练,如何对数据进行预处理也是要注意的,换句话说,给调参带来了更多的压力。关于这一点,感兴趣的读者可以阅读Kaming He的《Rethinking ImageNet Pre-training》。
即便如此,大家还是会优先使用预训练模型,毕竟省时省力。不是每个人都有那么充足的算力去调参的。
backbone这部分可以说很大程度上决定了detector的性能,所以,这部分的研究意义也很大,不过,很吃GPU这点还是很现实的,毕竟要先在imagenet上去pretrain一下,这就花不少时间,然后再替换现有的detector的backbone网络,去COCO上训练看涨点否,这又得花一大把时间……
什么?你有64张v100??啊!!对不起!对不起!打扰了!
后话:
这篇文章是具有时效性的。2020年开始,除了这一框架之外,初露锋芒的基于transformer结构的新的目标检测范式正如荼如火、势不可挡地横扫CV各个领域。对此,我就难以做过多的介绍了,感兴趣的可以DETR工作开始了解。
图像分割
FCN
方法概述
全卷积分割
Backbone作用:
- 提供feature的位置:最后一层
- 提供feature的作用:给后面的反卷积模块提供特征
Feature里被挖掘的信息(如何被挖掘):
前景和背景像素的信息(由Pixel-level的监督分类来学习)

SegNet
方法概述
全卷积分割
Backbone作用:
提供feature的位置:最后一层
提供feature的作用:给后面的升采样模块提供特
Feature里被挖掘的信息(如何被挖掘):
前景和背景像素的信息(由Pixel-level的监督来学习)

Unet
方法概述
全卷积分割
Backbone作用:
提供feature的位置:中间多层
提供feature的作用:给后面的升采样模块提供特征
Feature里被挖掘的信息(如何被挖掘):
前景和背景像素的信息(由Pixel-level的监督分类来学习

DeepLabV3
方法概述
加入了空洞卷积,多尺度的atrous rates的ASPP模块
Backbone作用:
提供feature的位置:最后一层
提供feature的作用:给后面的ASPP模块提供特征
Feature里被挖掘的信息(如何被挖掘):
前景和背景像素的信息(由Pixel-level的监督分类来学习)

PSPNet
方法概述
采用金字塔池化模块(Pyramid Pooling Module)来对backbone提取的特征进行处理
Backbone作用:
提供feature的位置:最后一层
提供feature的作用:给后面的金字塔池化模块(Pyramid Pooling Module)提供特征
Feature里被挖掘的信息(如何被挖掘):
前景和背景像素的信息(由Pixel-level的监督分类来学习)

怎么选择
宏观是transformer体系结构,包括但不限于vit,swin-t,convnext,VITDet
Transformer 系列
利用transformer 结构作为backbone主要有三个方向:
预训练,transformer+CNN,transformer完全替代CNN
transformer + cnn
-
BoTNet: BoTNet像是一种模块,类似SE net这种,有一些即插即用的感觉,用Multi-Head Self-Attention (MHSA)来替换3 × 3 convolution,不过论文中还是基于resnet设计了BoTNet 网络结构实现了效果的超越。
Only transformer
VIT :VIT 算是用transformer完全替代CNN的鼻祖了,因为后面很多文章也都会和VIT模型做对比。VIT模型有一点大力出奇迹的做法,即直接将图像分块(patch),每一个patch当作一个token直接送入transformer中。不过VIT模型直接在imagenet上训练效果比同级别resnet效果差一些,不过作者发现在更大的数据集上做pretrain,然后在imagenet上finetune,VIT就干掉了resnet,嗯,大力出奇迹,简单粗暴。
Tokens-to-Token ViT: T2T Vit 是在VIT 的基础上设计了Tokens-to-Token 模块,逐层tokens到token(T2T)转换,通过递归聚集相邻对象,逐步将图像结构化的Tokens变成一个token,这样就可以对周围token表示的局部结构进行建模,并可以减少token长度,而后再接一个VIT,实现了直接在imagenet上训练对resnet的超越
TNT:Transformer in Transformer 也可以看作是VIT的改进版本,是类比network in network,设计了Transformer in Transformer 结构,也获得了效果的提升。
近期利用transformer来来作为backbone 的结构还包括Deit,Swim Transformer等等,结构实在是有点多,个人表示根本follow不过来,不过有些结构有试过,确实能比对应resnest101 效果和速度都会好一些,模型上线之后还拿到一些创新收益。
个人感觉利用transformer完全替代CNN这块很多大佬都在发力,这里也只是罗列效果相对较好的算法。VIT算是打开了only transformer 的大门,让大家看到了希望,Tokens-to-Token ViT、TNT、Deit,Swim Transformer 等等算是实现了突破,可能从指标来看涨点并不像当年CNN横空出世的时候那么惊艳,但也算是提供了一个新的方向,毕竟CV目前内卷也已经相当严重了,希望这个坑后面能够产出更佳的效果。
head
是获取网络输出内容的网络,利用之前提取的特征,head利用这些特征,做出预测。
neck
neck:是放在backbone和head之间的,是为了更好的利用backbone提取的特征
GAP
Global Average Pool全局平均池化,就是将某个通道的特征取平均值,经常使用AdaptativeAvgpoold(1),在pytorch中,这个代表自适应性全局平均池化,说人话就是将某个通道的特征取平均值
bottleneck
瓶颈的意思
通常指的是网络输入的数据维度和输出的维度不同,输出的维度比输入的小了许多,就像脖子一样,变细了。经常设置的参数 bottle_num=256,指的是网络输出的数据的维度是256 ,可是输入进来的可能是1024维度的。
Embedding
深度学习方法都是使用线性和非线性转换对复杂的数据进行自动特征抽取,并将特征表示为“向量”(vector),这一过程一般也称为“嵌入”(embedding)
end to end
其实就是给了一个输入,我们就给出一个输出,不管其中的过程多么复杂,但只要给了一个输入,机会对应一个输出。
比如分类问题,你输入了一张图片,肯定有网络有特征提取,全链接分类,概率计算什么的,但是跳出算法问题,单从结果来看,就是给了一张输入,输出了一个预测结果。
End-To-End的方案,即输入一张图,输出最终想要的结果,算法细节和学习过程全部丢给了神经网络。
domain adaptation 和domain generalization 域适应和域泛化
域适应中,常见的设置是源域D_S完全已知,目标域D_T有或无标签。
域适应方法试着将源域知识迁移到目标域。第二种场景可以视为domain generalization域泛化。这种更常见因为将模型应用到完全未知的领域,正因为没有见过,所以没有任何模型更新和微调。这种泛化问题就是一种开集问题,由于所需预测类别较多,所以比较头疼
pretext task和downstream task
用于预训练的任务被称为前置/代理任务(pretext task),
用于微调的任务被称为下游任务(downstream task)
temperature parameters
论文中经常能看到这个温度参数的身影,那么他都有什么用处呢?比如经常看到下面这样的式子:

里面的beta就是temperature parameter,可以起到平滑softmax输出结果的作用,
当beta>1的时候,可以将输出结果变得平滑,当beta<1的时候,可以让输出结果变得差异更大一下,更尖锐一些。如果beta比较大,则分类的crossentropy损失会很大,可以在不同的迭代次数里,使用不同的beta数值,有点类似于学习率的效果。
热身Warm up
Warm up指的是用一个小的学习率先训练几个epoch,这是因为网络的参数是随机初始化的,一开始就采用较大的学习率容易数值不稳定。
mask
yolov5目标检测神经网络——损失函数计算原理
用选定的图像、图形或物体,对处理的图像(全部或局部)进行遮挡,来控制图像处理的区域或处理过程。
数字图像处理中**,掩模为二维矩阵数组**,有时也用多值图像,
图像掩模主要用于:
①提取感兴趣区,用预先制作的感兴趣区掩模与待处理图像相乘,得到感兴趣区图像,感兴趣区内图像值保持不变,而区外图像值都为0。
②屏蔽作用,用掩模对图像上某些区域作屏蔽,使其不参加处理或不参加处理参数的计算,或仅对屏蔽区作处理或统计。
③结构特征提取,用相似性变量或图像匹配方法检测和提取图像中与掩模相似的结构特征。
④特殊形状图像的制作。
什么是mask掩码?
神经网络对一张图像分割成的8080网格预测了38080个预测框,那么每个预测框都存在检测目标吗?
显然不是。
所以在训练时首先需要根据标签作初步判断,哪些预测框里面很可能存在目标?
mask掩码为这样的一个38080的bool型矩阵:38080个bool值与380*80个预测框一一对应,根据标签信息和一定规则判断每个预测框内是否存在目标,如果存在则将mask矩阵中对应位置的值设置为true,否则设置为false。
mask掩码有什么用?
神经网络对8080网格的每个格子都预测三个矩形框,因此输出了380*80个预测框,每个预测框的预测信息包括矩形框信息、置信度、分类概率。实际上,并非所有预测框都需要计算所有类别的损失函数值,而是根据mask矩阵来决定:
-
仅mask矩阵中对应位置为true的预测框,需要计算矩形框损失;
-
仅mask矩阵中对应位置为true的预测框,需要计算分类损失;
-
所有预测框都需要计算置信度损失,但是mask为true的预测框与mask为false的预测框的置信度标签值不一样。
【masks其实就是每个像素都要标定这个像素属不属于一个物体,bounding box是比较粗略的】