cAdvisor+Prometheus+Grafana 10分钟搞定Docker容器监控平台
cAdvisor(Container Advisor) 是 Google 开源的一个容器监控工具,可用于对容器资源的使用情况和性能进行监控。用于收集、聚合、处理和导出正在运行容器的有关信息。具体来说,该组件对每个容器都会记录其资源隔离参数、历史资源使用情况、完整历史资源使用情况的直方图和网络统计信息。cAdvisor 本身就对 Docker 容器支持,并且还对其它类型的容器尽可能的提供支持,力求兼容与适配所有类型的容器。
由以上介绍我们可以知道,cAdvisor 是用于监控容器引擎的,由于其监控的实用性,Kubernetes 已经默认将其与 Kubelet 融合作为容器监控指标的默认工具,所以,对于云原生集群直接使用 Kubelet 组件提供的指标采集地址即可。
cAdvisor部署
1、使用以下命令安装启动cAdvisor组件:
docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
--privileged \
--device=/dev/kmsg \
google/cadvisor:latest
2、此时,cAdvisor组件已经启动,我们可以使用浏览器访问 http://自己IP地址:8080 访问到cAdvisor组件的Web UI:


3、而在多主机的情况下,在所有节点上运行一个cAdvisor再通过各自的Web UI查看监控信息显然不太方便,同时cAdvisor默认只保存2分钟的监控数据。好消息是cAdvisor已经内置了对Prometheus的支持。访问http://自己的IP地址:8080/metrics即可获取到标准的Prometheus监控样本输出:
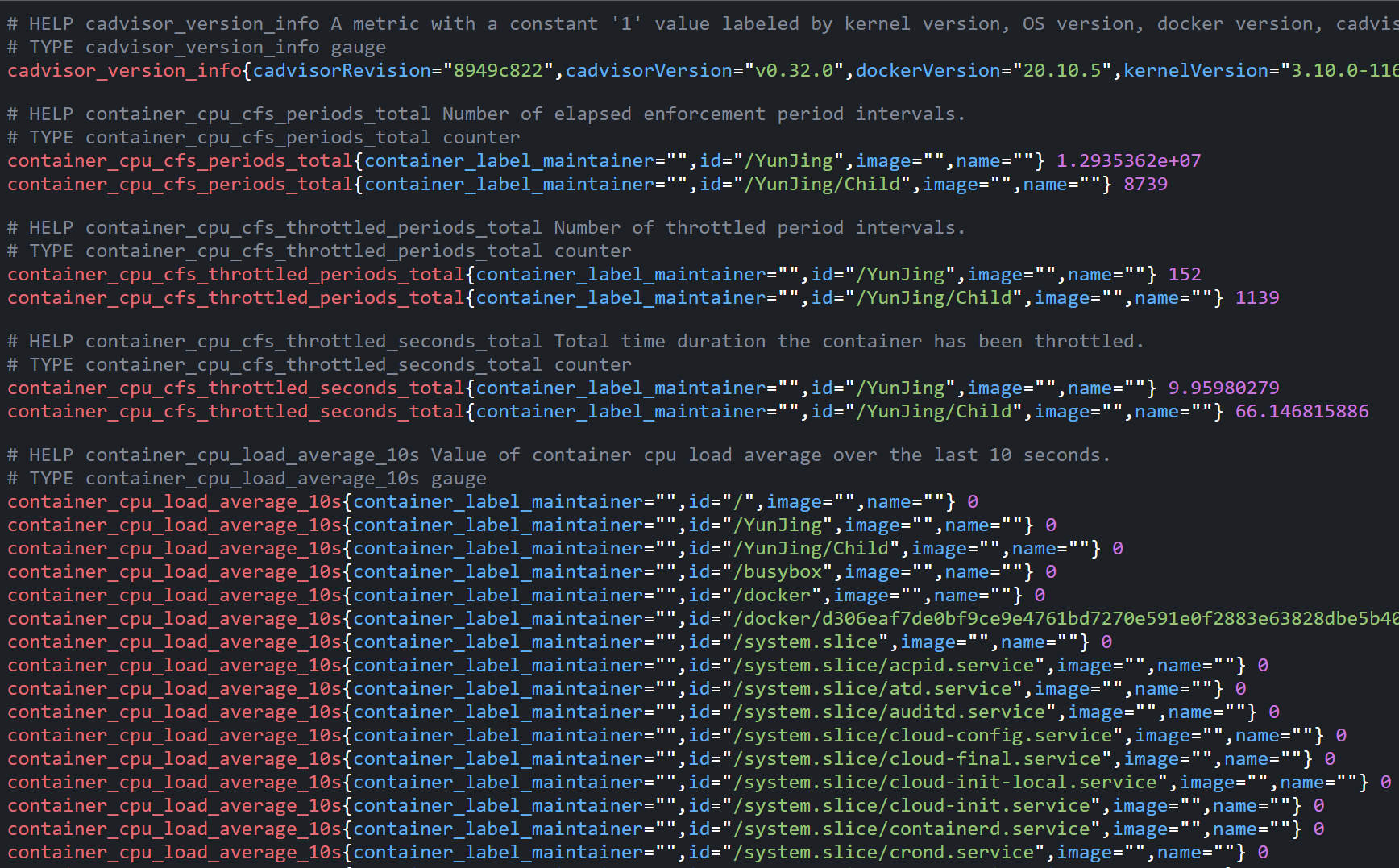
4、下面表格中列举了一些cAdvisor中获取到的典型监控指标:
| 指标名称 | 类型 | 含义 |
|---|---|---|
| container_cpu_load_average_10s | gauge | 过去10秒容器CPU的平均负载 |
| container_cpu_usage_seconds_total | counter | 容器在每个CPU内核上的累积占用时间 (单位:秒) |
| container_cpu_system_seconds_total | counter | System CPU累积占用时间(单位:秒) |
| container_cpu_user_seconds_total | counter | User CPU累积占用时间(单位:秒) |
| container_fs_usage_bytes | gauge | 容器中文件系统的使用量(单位:字节) |
| container_fs_limit_bytes | gauge | 容器可以使用的文件系统总量(单位:字节) |
| container_fs_reads_bytes_total | counter | 容器累积读取数据的总量(单位:字节) |
| container_fs_writes_bytes_total | counter | 容器累积写入数据的总量(单位:字节) |
| container_memory_max_usage_bytes | gauge | 容器的最大内存使用量(单位:字节) |
| container_memory_usage_bytes | gauge | 容器当前的内存使用量(单位:字节 |
| container_spec_memory_limit_bytes | gauge | 容器的内存使用量限制 |
| machine_memory_bytes | gauge | 当前主机的内存总量 |
| container_network_receive_bytes_total | counter | 容器网络累积接收数据总量(单位:字节) |
| container_network_transmit_bytes_total | counter | 容器网络累积传输数据总量(单位:字节) |
Prometheus部署
1、创建prometheus存储数据外挂目录,避免容器重启丢失:
mkdir -p /disk/docker-monitor/prometheus/data
chmod 777 /disk/docker-monitor/prometheus/data
2、prometheus配置文件外挂出来,方便修改,vi /disk/docker-monitor/prometheus/prometheus.yml:
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
rule_files:
- rule/record/*.yml
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "cadvisor"
static_configs:
- targets: ["124.222.45.207:8080"]
job_name: "prometheus"配置抓取Prometheus自身相关指标;
job_name: "cadvisor"配置抓取之前配置的cAdvisor组件指标。
3、Docker部署Prometheus:
docker run -d -p 9090:9090 --name prometheus \
-v /disk/docker-monitor/prometheus/conf:/opt/bitnami/prometheus/conf \
-v /disk/docker-monitor/prometheus/data:/opt/bitnami/prometheus/data \
bitnami/prometheus:2.42.0 \
--web.enable-lifecycle --web.enable-admin-api\
--config.file=/opt/bitnami/prometheus/conf/prometheus.yml\
--storage.tsdb.path=/opt/bitnami/prometheus/data
–web.enable-lifecycle --web.enable-admin-api提供rest api接口方式管理prometheus,比如配置热加载:curl -XPOST http://localhost:9090/-/reload。
注意:这里将prometheus配置文件和存储目录外挂出来,避免容器重启后数据丢失。
4、Prometheus启动完成后,浏览器访问:
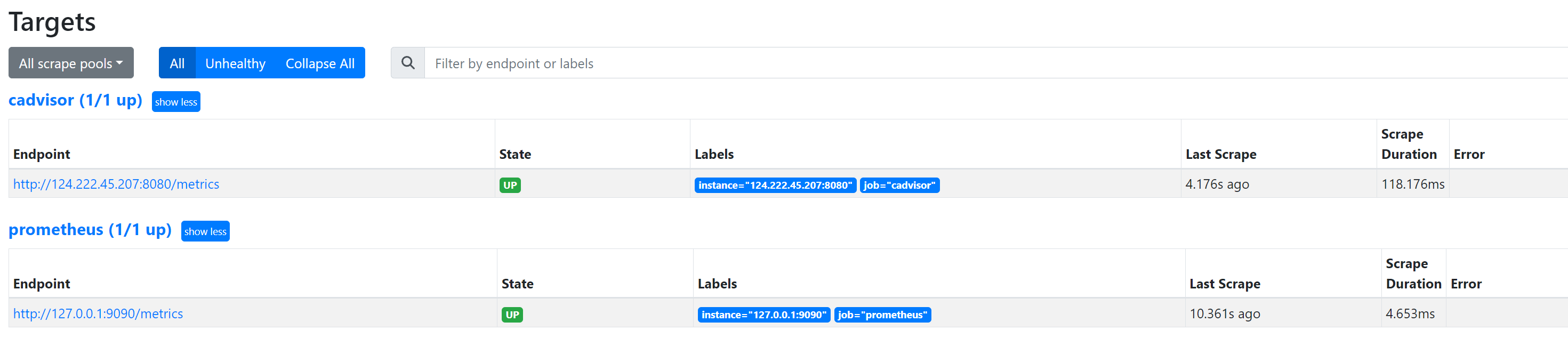
访问Status -> Targets页面,发现配置的两个抓取Job已经显示,并且State是绿色UP,则接入成功。
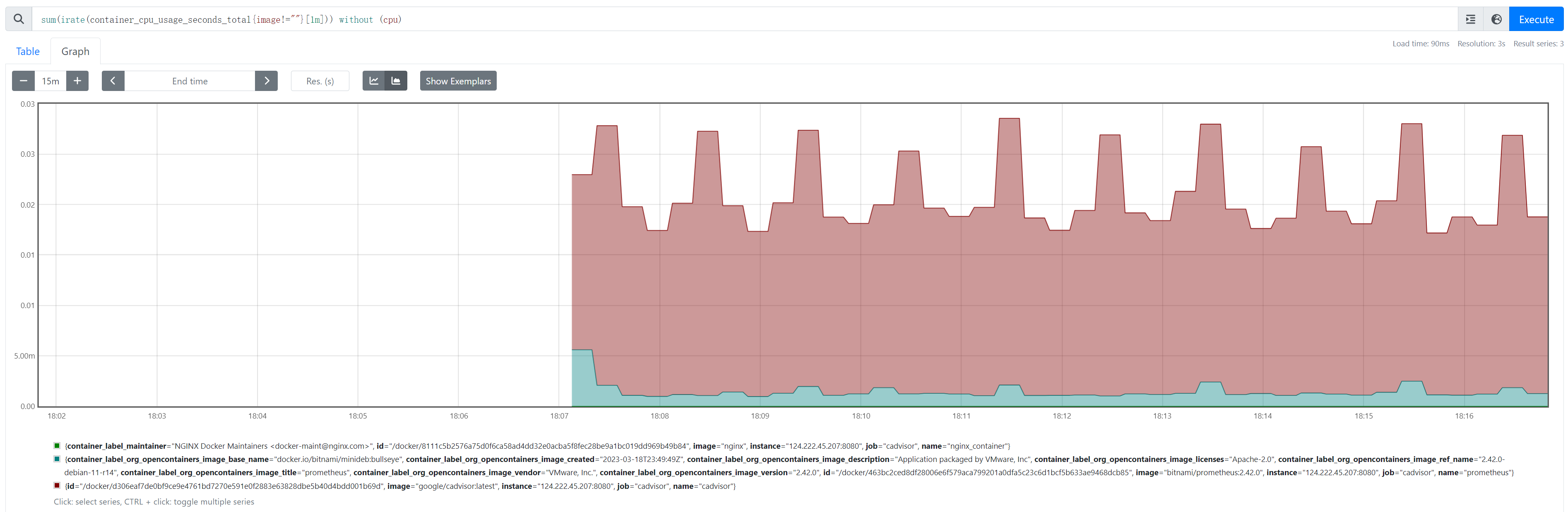
5、当能够正常采集到cAdvisor的样本数据后,可以通过以下表达式计算容器的CPU使用率:sum(irate(container_cpu_usage_seconds_total{image!=""}[1m])) without (cpu)
Grafana部署
1、部署Grafana:
docker run -d --name=grafana -p 3000:3000 -v grafana:/var/lib/grafana grafana/grafana
/var/lib/grafana路径外挂出来,该目录存储Grafana插件、数据信息,避免Docker容器重启数据丢失。
2、访问:http://自己的IP:3000/login,输入账号admin/admin:
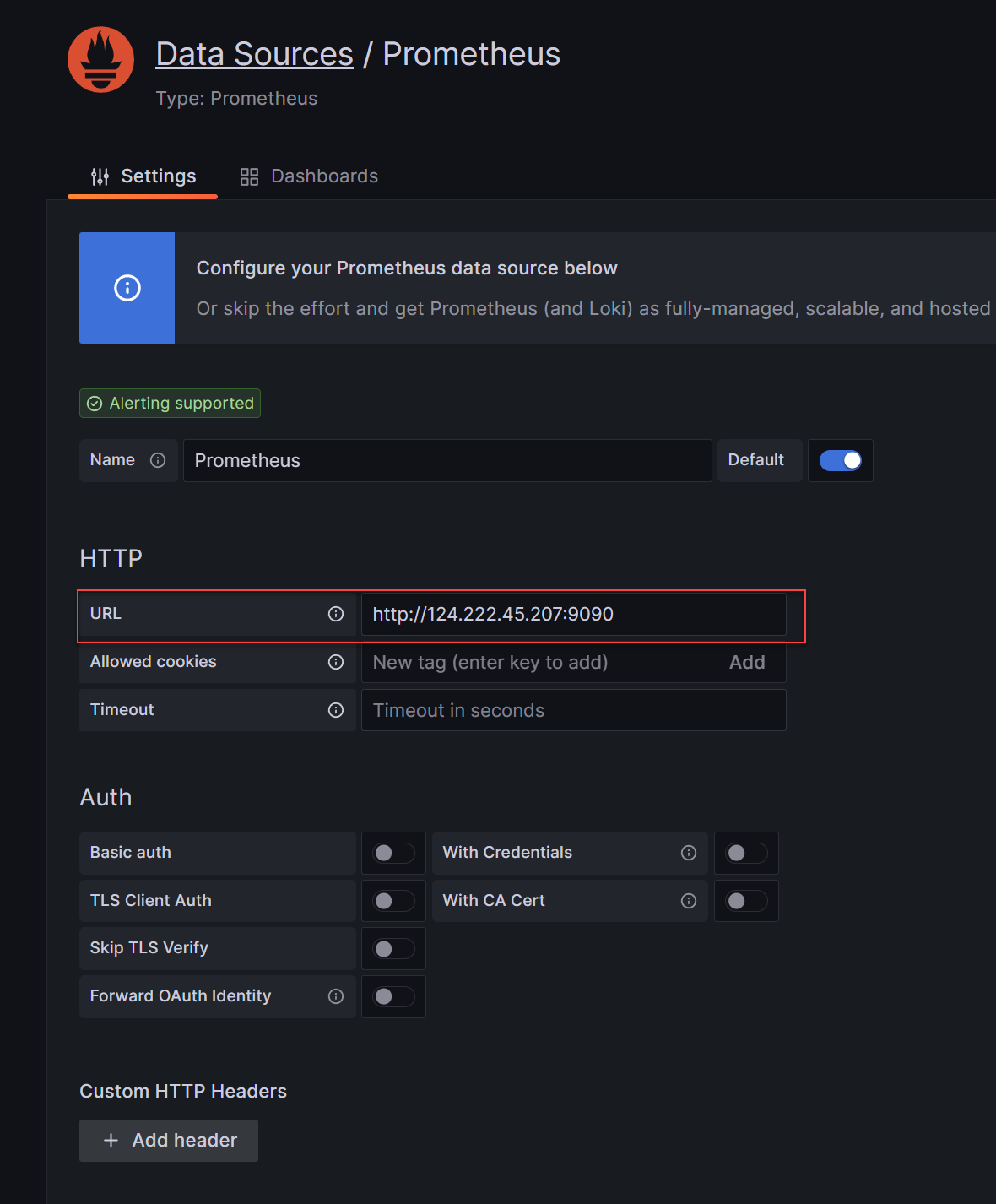
3、创建Prometheus类型数据源,指向刚才搭建的Prometheus:
4、导入Docker容器监控面板,这里使用11277:
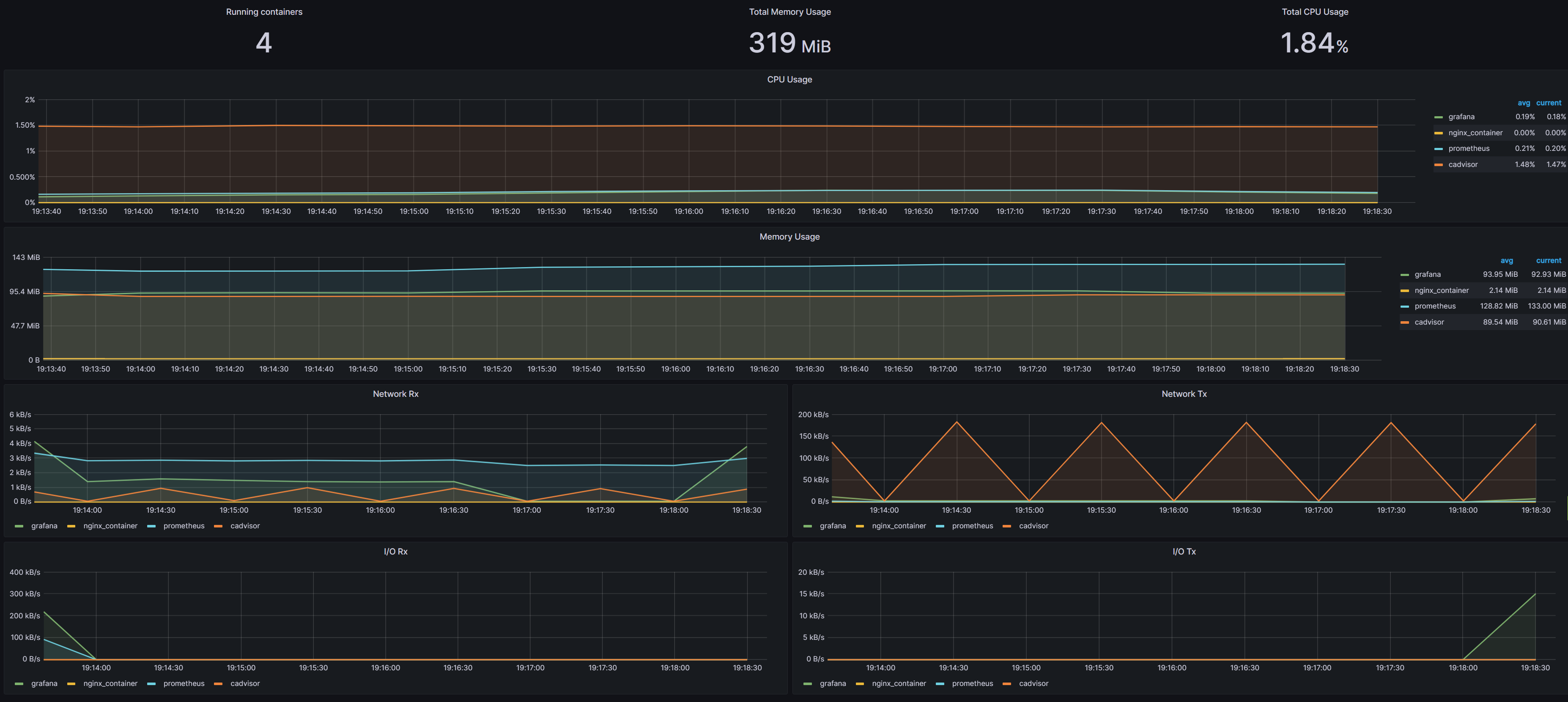
5、监控面板就可以看到Docker容器运行情况,如下图,当前运行中容器有4个,总占用内存319MB,总CPU使用率大概1.84%,并以曲线方式展示每个容器的CPU使用率、内存使用率、网络IO和磁盘IO等。