PCM文件
.pcm:PCM(Pulse-code modulation)->脉冲编码调制。PCM可以将声音从模拟信号转换为数字信号,原理:利用一个固定的频率对模拟信号进行采样,采样后的信号在波形上看就像一串连续的幅值不一的脉冲,把这些脉冲的幅值按一定的精度进行量化,这些量化后的数值被连续地输出、传输、处理或记录到存储介质中,这便组成了数字音频的产生过程。
PCM数据时完全无损,音质优秀但体积庞大。
压缩方式:无损压缩(ALAC、APE、FLAC)
有损压缩(MP3、AAC、OGG、WMA)
一、了解音频
1.获取音频信息
def wav_infos(wav_path):
'''
获取音频信息
:param wav_path: 音频路径
:return: [1, 2, 8000, 51158, 'NONE', 'not compressed']
对应关系:声道,采样宽度,帧速率,帧数,唯一标识,无损
'''
with wave.open(wav_path, "rb") as f:
f = wave.open(wav_path)
return list(f.getparams())
2.读取音频文件内容
def read_wav(wav_path):
'''
读取音频文件内容:只能读取单声道的音频文件, 这个比较耗时
:param wav_path: 音频路径
:return: 音频内容
'''
with wave.open(wav_path, "rb") as f:
# 读取格式信息
# 一次性返回所有的WAV文件的格式信息,它返回的是一个组元(tuple):声道数, 量化位数(byte单位), 采
# 样频率, 采样点数, 压缩类型, 压缩类型的描述。wave模块只支持非压缩的数据,因此可以忽略最后两个信息
params = f.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
# 读取声音数据,传递一个参数指定需要读取的长度(以取样点为单位)
str_data = f.readframes(nframes)
return str_data
3.获取音频时长(秒)
def get_wav_time(wav_path):
'''
获取音频文件是时长
:param wav_path: 音频路径
:return: 音频时长 (单位秒)
'''
with contextlib.closing(wave.open(wav_path, 'r')) as f:
frames = f.getnframes()
rate = f.getframerate()
duration = frames / float(rate)
return duration
4.音频切片
# 音频切片,获取部分音频 时间的单位是毫秒
start_time = 13950
end_time = 15200
get_ms_part_wav(main_wav_path, start_time, end_time, part_wav_path)
# 音频切片,获取部分音频 时间的单位是秒
start_time = 35
end_time = 38
get_second_part_wav(main_wav_path, start_time, end_time, second_part_wav_path)
# 音频切片,获取部分音频 时间的单位是分钟和秒 样式:0:12
start_time = "0:35"
end_time = "0:38"
get_minute_part_wav(main_wav_path, start_time, end_time, minute_part_wav_path)
5.wav文件与pcm文件之间的相互转换
# wav文件转为pcm文件
wav_to_pcm(wav_path, pcm_path)
# pcm文件转为wav文件
pcm_to_wav(pcm_path, wav_path2)
6.画音频对应的波形图
wav_waveform(wav_path)
def wav_waveform(wave_path):
'''
音频对应的波形图
:param wave_path: 音频路径
:return:
'''
file = wave.open(wave_path)
# print('---------声音信息------------')
# for item in enumerate(WAVE.getparams()):
# print(item)
a = file.getparams().nframes # 帧总数
f = file.getparams().framerate # 采样频率
sample_time = 1 / f # 采样点的时间间隔
time = a / f # 声音信号的长度
sample_frequency, audio_sequence = wavfile.read(wave_path)
# print(audio_sequence) # 声音信号每一帧的“大小”
x_seq = np.arange(0, time, sample_time)
plt.plot(x_seq, audio_sequence, 'blue')
plt.xlabel("time (s)")
plt.show()
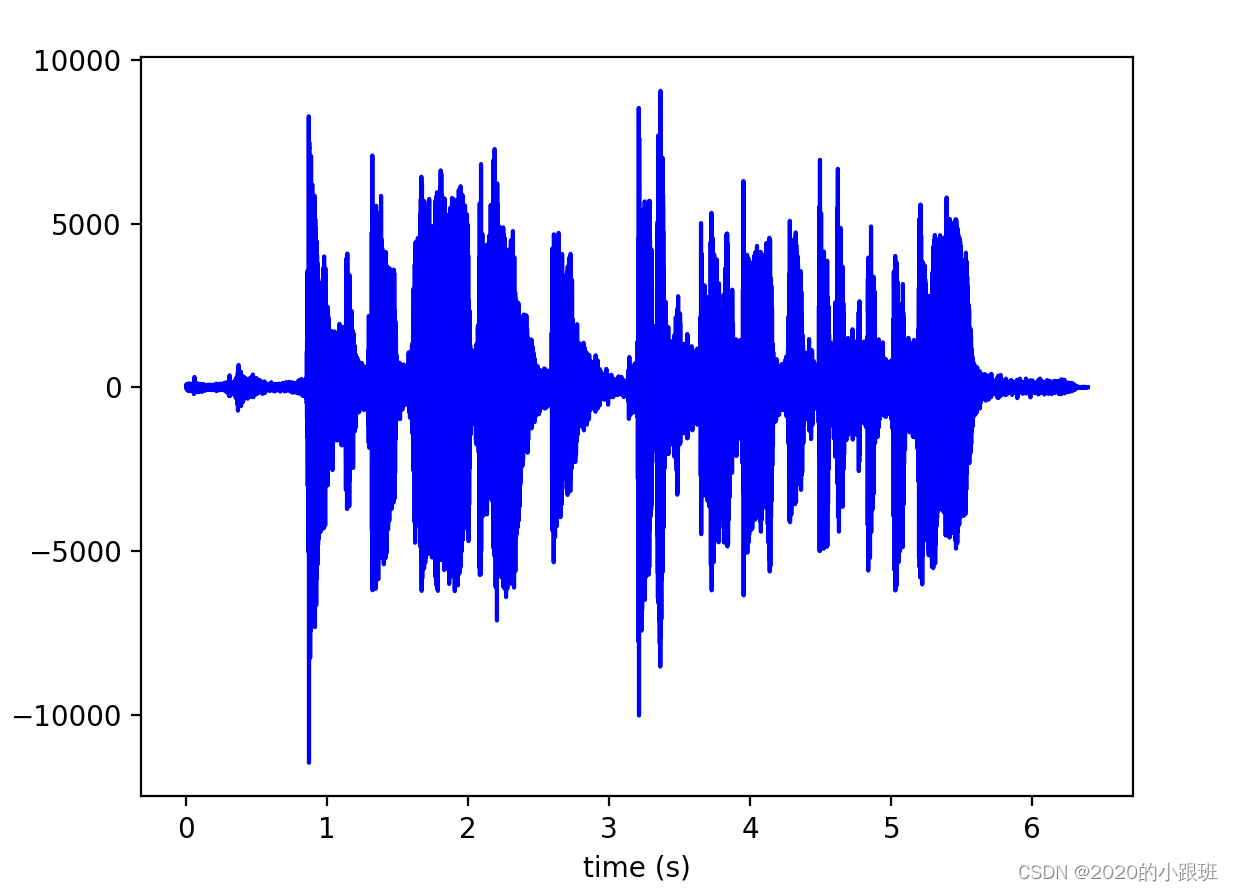
其中代码的调用来自于waveTools这个工具包(借鉴)
# -*- coding:utf8 -*-
'''
auth: Young
公众号:Python疯子 (Hold2Crazy)
'''
import wave
import contextlib
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
from pydub import AudioSegment
def wav_infos(wav_path):
'''
获取音频信息
:param wav_path: 音频路径
:return: [1, 2, 8000, 51158, 'NONE', 'not compressed']
对应关系:声道,采样宽度,帧速率,帧数,唯一标识,无损
'''
with wave.open(wav_path, "rb") as f:
f = wave.open(wav_path)
return list(f.getparams())
def read_wav(wav_path):
'''
读取音频文件内容:只能读取单声道的音频文件, 这个比较耗时
:param wav_path: 音频路径
:return: 音频内容
'''
with wave.open(wav_path, "rb") as f:
# 读取格式信息
# 一次性返回所有的WAV文件的格式信息,它返回的是一个组元(tuple):声道数, 量化位数(byte单位), 采
# 样频率, 采样点数, 压缩类型, 压缩类型的描述。wave模块只支持非压缩的数据,因此可以忽略最后两个信息
params = f.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
# 读取声音数据,传递一个参数指定需要读取的长度(以取样点为单位)
str_data = f.readframes(nframes)
return str_data
def get_wav_time(wav_path):
'''
获取音频文件是时长
:param wav_path: 音频路径
:return: 音频时长 (单位秒)
'''
with contextlib.closing(wave.open(wav_path, 'r')) as f:
frames = f.getnframes()
rate = f.getframerate()
duration = frames / float(rate)
return duration
def get_ms_part_wav(main_wav_path, start_time, end_time, part_wav_path):
'''
音频切片,获取部分音频 单位是毫秒级别
:param main_wav_path: 原音频文件路径
:param start_time: 截取的开始时间
:param end_time: 截取的结束时间
:param part_wav_path: 截取后的音频路径
:return:
'''
start_time = int(start_time)
end_time = int(end_time)
sound = AudioSegment.from_mp3(main_wav_path)
word = sound[start_time:end_time]
word.export(part_wav_path, format="wav")
def get_second_part_wav(main_wav_path, start_time, end_time, part_wav_path):
'''
音频切片,获取部分音频 单位是秒级别
:param main_wav_path: 原音频文件路径
:param start_time: 截取的开始时间
:param end_time: 截取的结束时间
:param part_wav_path: 截取后的音频路径
:return:
'''
start_time = int(start_time) * 1000
end_time = int(end_time) * 1000
sound = AudioSegment.from_mp3(main_wav_path)
word = sound[start_time:end_time]
word.export(part_wav_path, format="wav")
def get_minute_part_wav(main_wav_path, start_time, end_time, part_wav_path):
'''
音频切片,获取部分音频 分钟:秒数 时间样式:"12:35"
:param main_wav_path: 原音频文件路径
:param start_time: 截取的开始时间
:param end_time: 截取的结束时间
:param part_wav_path: 截取后的音频路径
:return:
'''
start_time = (int(start_time.split(':')[0])*60+int(start_time.split(':')[1]))*1000
end_time = (int(end_time.split(':')[0])*60+int(end_time.split(':')[1]))*1000
sound = AudioSegment.from_mp3(main_wav_path)
word = sound[start_time:end_time]
word.export(part_wav_path, format="wav")
def wav_to_pcm(wav_path, pcm_path):
'''
wav文件转为pcm文件
:param wav_path:wav文件路径
:param pcm_path:要存储的pcm文件路径
:return: 返回结果
'''
f = open(wav_path, "rb")
f.seek(0)
f.read(44)
data = np.fromfile(f, dtype=np.int16)
data.tofile(pcm_path)
def pcm_to_wav(pcm_path, wav_path):
'''
pcm文件转为wav文件
:param pcm_path: pcm文件路径
:param wav_path: wav文件路径
:return:
'''
f = open(pcm_path,'rb')
str_data = f.read()
wave_out=wave.open(wav_path,'wb')
wave_out.setnchannels(1)
wave_out.setsampwidth(2)
wave_out.setframerate(8000)
wave_out.writeframes(str_data)
# 音频对应的波形图
def wav_waveform(wave_path):
'''
音频对应的波形图
:param wave_path: 音频路径
:return:
'''
file = wave.open(wave_path)
# print('---------声音信息------------')
# for item in enumerate(WAVE.getparams()):
# print(item)
a = file.getparams().nframes # 帧总数
f = file.getparams().framerate # 采样频率
sample_time = 1 / f # 采样点的时间间隔
time = a / f # 声音信号的长度
sample_frequency, audio_sequence = wavfile.read(wave_path)
# print(audio_sequence) # 声音信号每一帧的“大小”
x_seq = np.arange(0, time, sample_time)
plt.plot(x_seq, audio_sequence, 'blue')
plt.xlabel("time (s)")
plt.show()
二、处理音频(截取音频)
方法一:
from pydub import AudioSegment
import os
import librosa
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import math
# 显示音频时域波形
file_path = 'E:\shipsEar_AUDIOS-20220902T005604Z-001\shipsEar_AUDIOS\96__A__Draga_4.wav'
fname, ext = os.path.split(file_path)
input_music = AudioSegment.from_wav(file_path)
# 开始截取时间
start = 0 * 1000
end = 60 *1000
number = math.floor((end-start)/(5*1000))
for i in range(number):
output_music = input_music[(start + i* 5*1000):(start + i*5*1000 + 5*1000)]
output_music.export('E:\shipsEar_AUDIOS-20220902T005604Z-001\Data_frame\96__A__Draga_' + str(i+1) + '.wav', format="wav")
方法二
将所有的音频放到同一个文件夹中,但是文件的命名会成为一个问题
import os
from pydub import AudioSegment
import numpy as np
########################开始批处理######################
file_path1 = r"E:\copy2"#输入路径
file_path2 = r"E:\dataset1" #输出路径
for filepath,dirnames,filenames in os.walk(file_path1):
for file in filenames: #遍历文件
path1 = filepath+'\\'+file
filename = file.split('.')[0] #不带 .wav的文件名
########################处理音频文件#######################
audio = AudioSegment.from_file(path1, "wav")
audio_time = len(audio) # 获取待切割音频的时长,单位是毫秒
cut_parameters = np.arange(0.3, audio_time / 1000, 0.3) # np.arange()函数第一个参数为起点,第二个参数为终点,第三个参数为步长(10秒)
start_time = int(0) # 开始时间设为0
########################根据数组切割音频####################
for t in cut_parameters:
stop_time = int(t * 1000) # pydub以毫秒为单位工作
# print(stop_time)
audio_chunk = audio[start_time:stop_time] # 音频切割按开始时间到结束时间切割
print("split at [{}:{}] ms".format(start_time, stop_time))
audio_chunk.export(file_path2 + '\\' + filename + "-{}.wav".format(int(t*10)), format="wav") #保存音频文件
start_time = stop_time
print('finish')