前端发送文件下载请求,接收后端发送的csv文件,关于乱码问题的处理
成功界面展示,关于乱码,测试了很多别人的编码方案,没能实现效果,这里实际应用如下。
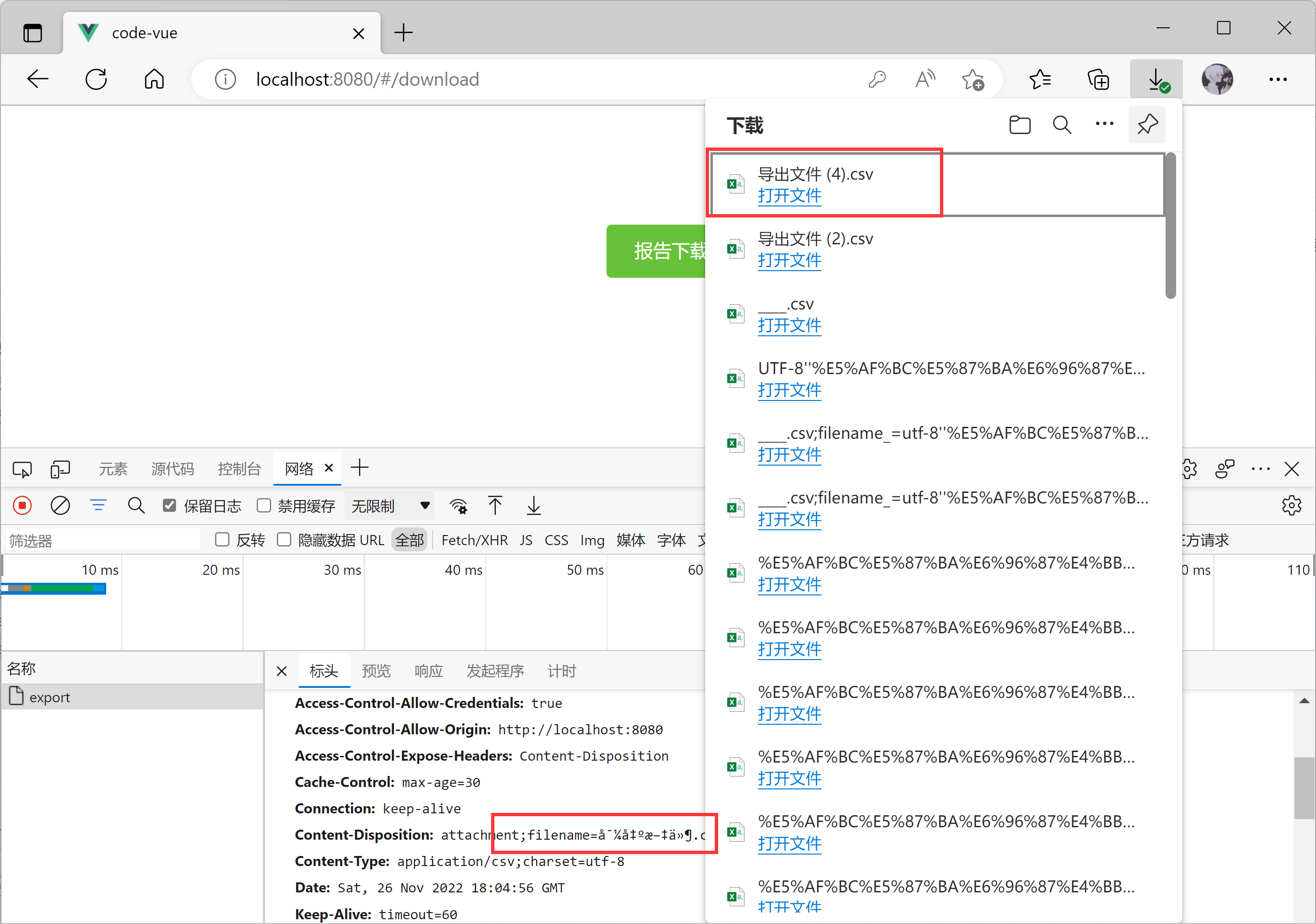
1、前端发送导出文件请求
downLoadFile(){
this.$http.get('/export').then(res => {
var disposition = res.headers["content-disposition"];
var fileName = decode(disposition.substring(disposition.indexOf("=") + 1), "UTF-8");
console.log(fileName)
let link = document.createElement('a');
link.href = window.URL.createObjectURL(new Blob(['\uFEFF' + res.data]))
link.download = fileName;
link.click();
URL.revokeObjectURL(link.href);
if (document.body.contains(link)) {
document.body.removeChild(link);
}
}, (response) => {
console.error(response)
});
},
2、后端下载并导出Csv文件
@RequestMapping(value = "/export")
public void getSkuList1(HttpServletRequest request, HttpServletResponse response) throws Exception {
LinkedHashSet<ShortLinks> linkedHashSet = ParseUrl.getLinkedHashSet();
List<Object[]> cellList = new ArrayList<>();
if (null == linkedHashSet || linkedHashSet.isEmpty()){
System.out.println("导出数据中没有处理的数据!");
}else {
for (ShortLinks sl : linkedHashSet) {
Object[] object = {
sl.getCreate_time(), sl.getShort_link(), sl.getDomain_name(), sl.getIp_address(), sl.getIp_territorial(),
sl.getRecord_status(), sl.getDomain_type()};
cellList.add(object);
}
String[] tableHeaderArr = {
"录入时间","短链接名", "对应域名", "对应IP", "IP归属地", "备案状态", "域名状态", "域名类型"};
String fileName = "导出文件.csv";
byte[] bytes = ExportCSVUtil.writeCsvAfterToBytes(tableHeaderArr, cellList);
ExportCSVUtil.responseSetProperties(fileName, bytes, request, response);
}
}
3、下载文件的工具类(这里编码问题做了处理)
package com.example.util;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.List;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.csv.CSVFormat;
import org.apache.commons.csv.CSVPrinter;
import org.apache.commons.io.ByteOrderMark;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class ExportCSVUtil {
private static final Logger logger = LoggerFactory.getLogger(ExportCSVUtil.class);
public static byte[] writeDataAfterToBytes(String[] tableHeaderArr, List<String> cellList) {
byte[] bytes = new byte[0];
ByteArrayOutputStream byteArrayOutputStream = null;
OutputStreamWriter outputStreamWriter = null;
BufferedWriter bufferedWriter = null;
try {
byteArrayOutputStream = new ByteArrayOutputStream();
outputStreamWriter = new OutputStreamWriter(byteArrayOutputStream,StandardCharsets.UTF_8);
bufferedWriter = new BufferedWriter(outputStreamWriter);
bufferedWriter.write(new String(ByteOrderMark.UTF_8.getBytes()));
StringBuilder sb = new StringBuilder();
String tableHeader = String.join(",", tableHeaderArr);
sb.append(tableHeader + StringUtils.CR + StringUtils.LF);
for (String rowCell : cellList) {
sb.append(rowCell + StringUtils.CR + StringUtils.LF);
}
bufferedWriter.write(sb.toString());
bufferedWriter.flush();
bytes = byteArrayOutputStream.toString(StandardCharsets.UTF_8.name()).getBytes();
return bytes;
} catch (IOException e) {
logger.error("writeDataAfterToBytes IOException:{}", e.getMessage(), e);
} finally {
try {
if (bufferedWriter != null) {
bufferedWriter.close();
}
if (outputStreamWriter != null) {
outputStreamWriter.close();
}
if (byteArrayOutputStream != null) {
byteArrayOutputStream.close();
}
} catch (IOException e) {
logger.error("iostream close IOException:{}", e.getMessage(), e);
}
}
return bytes;
}
public static byte[] writeCsvAfterToBytes(String[] headers, List<Object[]> cellList) {
byte[] bytes = new byte[0];
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(byteArrayOutputStream, StandardCharsets.UTF_8);
BufferedWriter bufferedWriter = new BufferedWriter(outputStreamWriter);
CSVPrinter csvPrinter = null;
try {
csvPrinter = new CSVPrinter(bufferedWriter, CSVFormat.DEFAULT.withHeader(headers));
csvPrinter.printRecords(cellList);
csvPrinter.flush();
bytes = byteArrayOutputStream.toString(StandardCharsets.UTF_8.name()).getBytes();
} catch (IOException e) {
logger.error("writeCsv IOException:{}", e.getMessage(), e);
} finally {
try {
if (csvPrinter != null) {
csvPrinter.close();
}
if (bufferedWriter != null) {
bufferedWriter.close();
}
if (outputStreamWriter != null) {
outputStreamWriter.close();
}
if (byteArrayOutputStream != null) {
byteArrayOutputStream.close();
}
} catch (IOException e) {
logger.error("iostream close IOException:{}", e.getMessage(), e);
}
}
return bytes;
}
public static void responseSetProperties(String fileName, byte[] bytes, HttpServletRequest request, HttpServletResponse response) {
try {
response.setCharacterEncoding(StandardCharsets.UTF_8.name());
response.setHeader("Pragma", "public");
response.setHeader("Cache-Control", "max-age=30");
fileName = new String(fileName.getBytes(), "ISO-8859-1");
response.setHeader("Content-Disposition","attachment;filename=" + fileName);
response.setHeader("Access-Control-Expose-Headers","Content-Disposition");
response.setHeader("content-Type", "application/csv;charset=utf-8");
OutputStream outputStream = response.getOutputStream();
outputStream.write(new byte[]{
(byte) 0xEF, (byte) 0xBB,(byte) 0xBF});
outputStream.write(bytes);
outputStream.flush();
} catch (IOException e) {
logger.error("isstream error:{}", e.getMessage(), e);
}
}
}