文章目录
gpt-4
- 在越复杂任务上,GPT4越是强于chatgpt
- 与chatgpt虽然也是zero-shot,但不能超越sota不同,GPT4在大部分任务上可以超越sota
- gpt4在其他语言上依然拥有极佳的效果
- gpt4在openai内部被大量使用,并且被用来评估AI输出。
Visual inputs(视觉输入)
GPT-4可以接受包含文本和图像的提示,与仅文本设置并行,使用户可以指定任何视觉或语言任务。具体而言,它可以在包含交错文本和图像的输入下生成文本输出(自然语言、代码等)。在包括文本和照片、图表或屏幕截图的一系列领域中,GPT-4表现出与仅文本输入相似的能力。此外,它还可以使用针对仅文本语言模型开发的测试时技术进行增强,包括少量样本和连续思考提示。
相较于chatgpt的提升:尊重事实、可控性、安全角度都有长足的进步。
稳定性:在小规模的计算成本下可以精准预测大规模模型的性能。
Training process(训练过程)
与之前的GPT模型一样,GPT-4基础模型的训练目标是预测文档中的下一个单词,并使用公开可用的数据(如网络数据)以及我们许可的数据进行训练。数据是一个大规模的语料库,包括数学问题的正确和错误解决方案、弱和强的推理、自相矛盾和一致的陈述,代表了各种意识形态和思想。
因此,当给出问题时,基础模型可能会以各种方式作出回应,这可能与用户的意图相去甚远。为了使其符合用户的意图并设置合理的限制,我们使用人类反馈的强化学习(RLHF)对模型的行为进行微调。
需要注意的是,RLHF并不能提高在各类考试上的成绩,模型的能力主要依赖数据和算力的堆砌,用简单的language modeling loss得到结果,RLHF实际作用是对模型进行控制,让模型知道任务的意图,更能知道提问的意图,按照人类喜欢的方式进行回答。
Loss Prediction(损失预测)
GPT-4项目的一大重点是构建一个可预测扩展的深度学习堆栈。主要原因是,对于GPT-4这样的大型训练运行,进行广泛的特定于模型的调优是不可行的。为了解决这个问题,开发了基础设施和优化方法,在多个尺度上具有非常可预测的行为。这些改进使我们能够从较小的模型中可靠地预测GPT-4性能的某些方面。
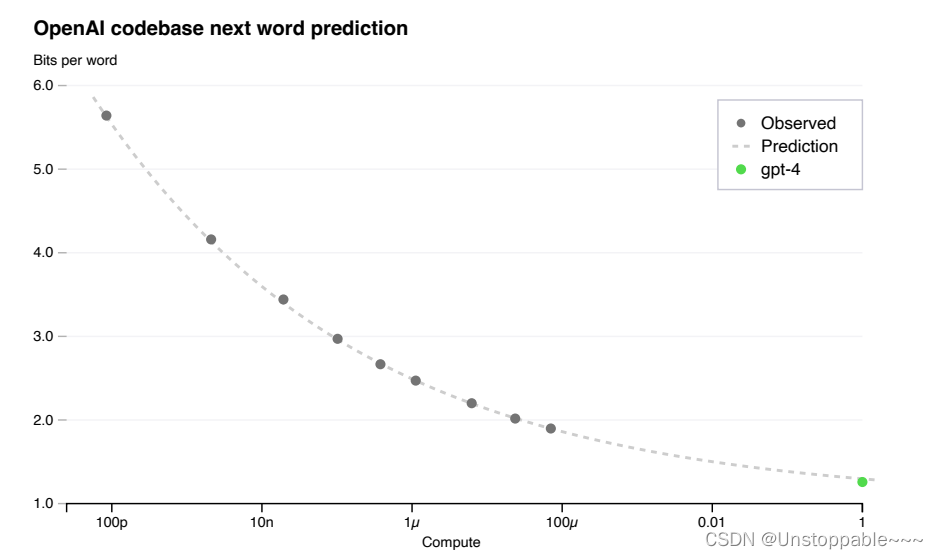
上图所示,由小模型的loss精确拟合出了gpt4的最终loss
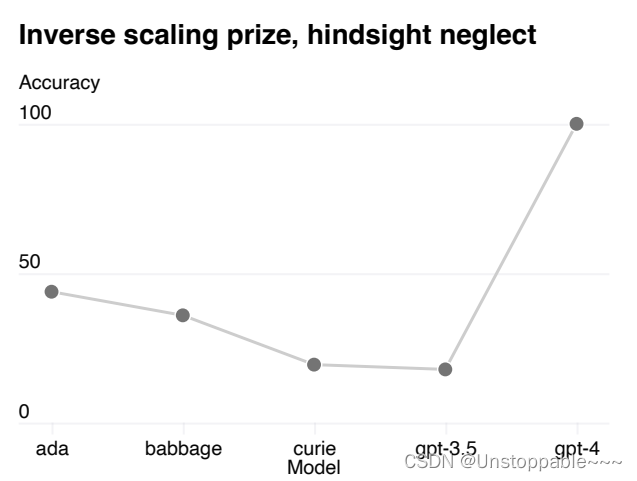
在hindsight neglect(马后炮)中模型越大,效果越差(模型倾向于通过最终的结果来进行决策而并非通过理性的因素来进行决策)但是在gpt-4这一现象得到逆转。从侧面印证,gpt4可能会有一定的推理能力。如下图所示,横轴从左到右模型变大。
Steerability(可控性)
与具有固定的冗长度、语气和风格的经典ChatGPT人格不同,开发人员(以及很快就是ChatGPT用户)现在可以通过在“系统”消息中描述这些指示来规定他们的AI的风格和任务。系统消息允许API用户在一定的范围内显著自定义其用户体验。例子:让gpt-4扮演苏格拉底式的老师对学生进行授课。
Limitations(限制)
- gpt4依然会一本正经胡说八道,但是会比chatgpt好很多,好了有40%。
- RLHF在生成事实性回答上确实很有用处
- gpt4依然存在部分偏见,但openai准备建立合理的默认行为,我对此并不看好,价值观的冲突是无法避免的,
特别是涉及政治 - gpt4和gpt3.5训练数据都是21年9月之前。
- gpt4依旧很容易轻信用户的虚假陈述。
- 一般的微调模型校准率很高,而做过RLHF之后的模型校准率很低,这就使得gpt4的logits值不具备任何意义。
GPT-4在其预测中也可能非常自信地犯错,不在可能犯错的情况下仔细检查工作。有趣的是,基础预训练模型的校准性很高(其预测的答案置信度通常与正确的概率相匹配)。然而,通过我们目前的事后训练过程,校准性会降低。
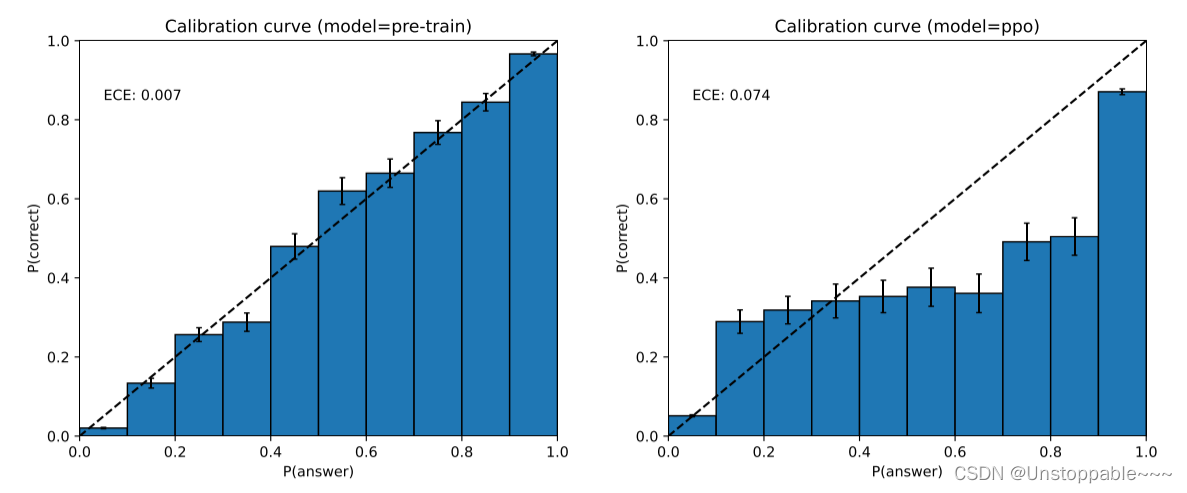
如上图所示,在MMLU子集上,预训练的GPT-4模型的校准图。模型对其预测的置信度与正确性的概率非常接近。虚线对角线代表完美的校准。右图:在相同的MMLU子集上,经过PPO事后训练的GPT-4模型的校准图。我们目前的过程会使校准性受到相当大的影响。
Risks & mitigations(风险和应对措施)
GPT-4面临着与以往模型类似的风险,例如生成有害建议、错误的代码或不准确的信息。然而,GPT-4的额外功能导致了新的风险面。
GPT-4将在RLHF训练期间引入额外的安全奖励信号,通过训练模型拒绝请求不安全内容(根据我们的使用指南定义)来减少有害输出。该奖励由一个GPT-4 zero-shot分类器提供,对安全相关提示的安全边界和完成风格进行评估。为防止模型拒绝有效请求,我们从各种来源收集了多样化的数据集(例如,标记的生产数据、人类红队、模型生成的提示),并在允许和不允许的类别上应用安全奖励信号(具有正面或负面价值)。
与GPT-3.5相比,我们的缓解措施显著改善了GPT-4的许多安全属性。我们将模型对于被禁止内容请求的响应率降低了82%,并且GPT-4根据我们的政策更频繁地回应敏感请求(例如,医疗建议),提高了29%。
总体而言,我们的模型层面干预措施增加了引发不良行为的难度,但仍然有可能发生。此外,仍然存在越狱的情况,可以生成违反我们使用准则的内容。