这是个人做错了的题目,记录到该博客,题目后面会附带上网上搜索到的资料以及个人理解,如果有不正确的地方,请拍砖。
1、结构型模式中最体现扩展性的模式是()
A.装饰模式
B.合成模式
C.桥接模式
D.适配器
答案:A
解析:结构型模式是描述如何将类对象结合在一起,形成一个更大的结构,结构模式描述两种不同的东西:类与类的实例。故可以分为类结构模式和对象结构模式。
在GoF设计模式中,结构型模式有:
适配器模式 Adapter
适配器模式是将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
两个成熟的类需要通信,但是接口不同,由于开闭原则,我们不能去修改这两个类的接口,所以就需要一个适配器来完成衔接过程。
桥接模式 Bridge
桥接模式将抽象部分与它的实现部分分离,使它们都可以独立地变化。它很好的支持了开闭原则和组合锯和复用原则。实现系统可能有多角度分类,每一种分类都有可能变化,那么就把这些多角度分离出来让他们独立变化,减少他们之间的耦合。
组合模式 Composite
组合模式将对象组合成树形结构以表示部分-整体的层次结构,组合模式使得用户对单个对象和组合对象的使用具有一致性。
装饰模式 Decorator
装饰模式动态地给一个对象添加一些额外的职责,就增加功能来说,它比生成子类更灵活。也可以这样说,装饰模式把复杂类中的核心职责和装饰功能区分开了,这样既简化了复杂类,又去除了相关类中重复的装饰逻辑。装饰模式没有通过继承原有类来扩展功能,但却达到了一样的目的,而且比继承更加灵活,所以可以说装饰模式是继承关系的一种替代方案。
外观模式 Facade
观模式为子系统中的一组接口提供了统一的界面,外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
外观模式中,客户对各个具体的子系统是不了解的,所以对这些子系统进行了封装,对外只提供了用户所明白的单一而简单的接口,用户直接使用这个接口就可以完成操作,而不用去理睬具体的过程,而且子系统的变化不会影响到用户,这样就做到了信息隐蔽。
享元模式 Flyweight
享元模式为运用共享技术有效的支持大量细粒度的对象。因为它可以通过共享大幅度地减少单个实例的数目,避免了大量非常相似类的开销。.
享元模式是一个类别的多个对象共享这个类别的一个对象,而不是各自再实例化各自的对象。这样就达到了节省内存的目的。
代理模式 Proxy
为其他对象提供一种代理,并由代理对象控制对原对象的引用,以间接控制对原对象的访问。
2、下面代码的输出是什么?
public class Base
{
private String baseName = "base";
public Base()
{
callName();
}
public void callName()
{
System. out. println(baseName);
}
static class Sub extends Base
{
private String baseName = "sub";
public void callName()
{
System. out. println (baseName) ;
}
}
public static void main(String[] args)
{
Base b = new Sub();
}
}A.null
B.sub
C.base
答案:A
解析:首先要清楚对象的初始化过程:
- 父类静态代码区和父类静态成员
- 子类静态代码区和子类静态成员
- 父类非静态代码区和普通成员
- 父类构造函数
- 子类非静态代码区和普通成员
- 子类构造函数
此题中Base b = new Sub();语句创建Sub对象,并向上转型为其父类Base类型,根据对象初始化的顺序,父类、子类中都没有静态成员跟静态代码块,所以先给父类的成员baseName赋值,然后执行父类的构造器函数,父类的构造方法中调用了callName()方法,而子类重写了该方法,所以这里调用的是子类的callName()方法,子类的callName()方法方法输出的是子类的baseName,而在这里,初始化的过程还没有执行到为baseName赋值的语句,所以baseName是null,结果输出了null。
3、以下代码执行的结果是多少()?
public class Demo {
public static void main(String[] args) {
Collection<?>[] collections =
{new HashSet<String>(), new ArrayList<String>(), new HashMap<String, String>().values()};
Super subToSuper = new Sub();
for(Collection<?> collection: collections) {
System.out.println(subToSuper.getType(collection));
}
}
abstract static class Super {
public static String getType(Collection<?> collection) {
return “Super:collection”;
}
public static String getType(List<?> list) {
return “Super:list”;
}
public String getType(ArrayList<?> list) {
return “Super:arrayList”;
}
public static String getType(Set<?> set) {
return “Super:set”;
}
public String getType(HashSet<?> set) {
return “Super:hashSet”;
}
}
static class Sub extends Super {
public static String getType(Collection<?> collection) {
return "Sub"; }
}
}A. Sub:collection
Sub:collection
Sub:collection
B. Sub:hashSet
Sub:arrayList
Sub:collection
C. Super:collection
Super:collection
D. Super:hashSet
Super:arrayList
Super:collection
答案:C
解析:Sub继承类Super,但是Sub类中的getType方法是静态的,静态方法是静态绑定的,在编译期间就确定了会调用哪个方法,而不是在运行期间根据具体对象的类型进行绑定(多态绑定),因为定义的变量类型是Super,所以在编译期间就确定了调用父类的getType方法,而且传入getType方法的参数是Collection类型,所以调用了父类的getType(Collection<?> collection)方法。
static方法可以被子类继承,但是不能被子类重写(覆盖),可以被子类隐藏。(这里意思是说如果父类里有一个static方法,它的子类里如果没有对应的方法,那么当子类对象调用这个方法时就会使用父类中的方法。而如果子类中定义了相同的方法,则会调用子类的中定义的方法。唯一的不同就是,当子类对象上转型为父类对象时,不论子类中有没有定义这个静态方法,该对象都会使用父类中的静态方法。因此这里说静态方法可以被隐藏而不能被覆盖。这与子类隐藏父类中的成员变量是一样的。隐藏和覆盖的区别在于,子类对象转换成父类对象后,能够访问父类被隐藏的变量和方法,而不能访问父类被覆盖的方法)。
4、Java类Demo中存在方法func0、func1、func2、func3和func4,请问该方法中,哪些是不合法的定义?( )
public class Demo {
float func0()
{
byte i=1;
return i;
}
float func1()
{
int i=1;
return;
}
float func2()
{
short i=2;
return i;
}
float func3()
{
long i=3;
return i;
}
float func4()
{
double i=4;
return i;
}
}
A.func1
B.func2
C.func3
D.func4
答案: A D
解析:数据类型的转换,分为自动转换和强制转换。自动转换是程序在执行过程中 “ 悄然 ” 进行的转换,不需要用户提前声明,一般是从位数低的类型向位数高的类型转换;强制类型转换则必须在代码中声明,转换顺序不受限制。
自动数据类型转换
自动转换按从低到高的顺序转换。不同类型数据间的优先关系如下:
低 ———————————————> 高
byte,short,char-> int -> long -> float -> double
运算中,不同类型的数据先转化为同一类型,然后进行运算,转换规则如下:
| 操作数1类型 | 操作数2类型 | 转换后类型 |
|---|---|---|
| byte 、 short 、 char | int | int |
| byte 、 short 、 char 、 int | long | long |
| byte 、 short 、 char 、 int 、 long | float | float |
| byte 、 short 、 char 、 int 、 long 、 float | double | double |
强制数据类型转换
强制转换的格式是在需要转型的数据前加上 “( )” ,然后在括号内加入需要转化的数据类型。有的数据经过转型运算后,精度会丢失,而有的会更加精确。
5、下面语句错误的是:
byte b1=1,b2=2,b3,b6,b8;
final byte b4=4,b5=6,b7;
b3=(b1+b2); /*语句1*/
b6=b4+b5; /*语句2*/
b8=(b1+b4); /*语句3*/
b7=(b2+b5); /*语句4*/
System.out.println(b3+b6);A.语句1
B.语句2
C.语句3
D.语句4
答案:A C D
解析:Java表达式转型规则由低到高转换:
- 所有的byte,short,char型的值将被提升为int型;
- 如果有一个操作数是long型,计算结果是long型;
- 如果有一个操作数是float型,计算结果是float型;
- 如果有一个操作数是double型,计算结果是double型;
- 被fianl修饰的变量不会自动改变类型,当2个final修饰相操作时,结果会根据左边变量的类型而转化。
语句1错误:b3=(b1+b2);
自动转为int,所以正确写法为b3=(byte)(b1+b2);或者将b3定义为int;
语句2正确:b6=b4+b5;
b4、b5为final类型,不会自动提升,所以和的类型视左边变量类型而定,即b6可以是任意数值类型;
语句3错误:b8=(b1+b4);
虽然b4不会自动提升,但b1仍会自动提升,所以结果需要强转,b8=(byte)(b1+b4);
语句4错误:b7=(b2+b5); 同上。
同时注意b7是final修饰,即只可赋值一次,便不可再改变。
6、 哈希查找中k个关键字具有同一哈希值,若用线性探测法将这k个关键字对应的记录存入哈希表中,至少要进行( )次探测。
A.k
B.k+1
C.k(k+1)/2
D.1+k(k+1)/2
答案:C
解析:线性探测直接使用数组来存储数据。可以想象成一个停车问题,若当前车位已经有车,则你就继续往前开,直到找到下一个为空的车位。
当碰撞发生时,直接检测散列表中的下一位置。这样线性探测可能发生三种结果:
- 命中–该位置的键和被查找的键相同(填入,替换值)
- 未命中–键为空(该位置没有键,直接填入)
- 继续查找–该位置的键和被查找的键不同(再次探测)
线性探测容易产生“聚集”现象。当表中的第i、i+1、i+2的位置上已经存储某些关键字,则下一次哈希地址为i、i+1、i+2、i+3的关键字都将企图填入到i+3的位置上,这种多个哈希地址不同的关键字争夺同一个后继哈希地址的现象称为“聚集”。聚集对查找效率有很大影响。
对于该题目:k个键冲突,第一个不冲突,直接填入数组,算1次,第二个跟第一个冲突了,那么需要填到第二个桶号,需要2次,……,第k个跟前面k-1个都产生冲突,然后填入数组,需要k次,所以一共需要k(k+1)/2。
但是我看到了一样的题目,答案是k(k-1)/2,这样的答案是直接填入数组时不算探测,所以是0 + 1 + 2 + … + k - 1,所以是k(k-1)/2。
7、对{05,46,13,55,94,17,42}进行基数排序,一趟排序的结果是:
A.05,46,13,55,94,17,42
B.05,13,17,42,46,55,94
C.42,13,94,05,55,46,17
D.05,13,46,55,17,42,94
答案是:C
基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或bin sort,顾名思义,它是透过键值的部份资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用,基数排序法是属于稳定性的排序。
先对个位进行排序,再到十位…
如图(网上找来的):

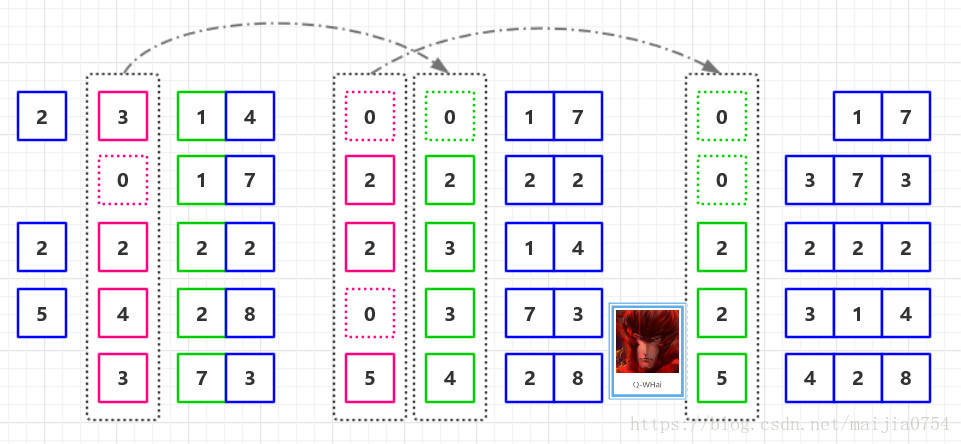
所以上图一趟排序的结果是42,13,94,05,55,46,17。
8、若一颗二叉树的前序遍历为a,e,b,d,c,后序遍历为b,c,d,e,a,则根节点的孩子节点()
A.只有e
B.有e,b
C.有e,c
D.不确定
答案:A
解析:二叉树是每个节点最多有两个子树的树结构。
先序遍历
首先访问根,再先序遍历左(右)子树,最后先序遍历右(左)子树。
中序遍历
首先中序遍历左(右)子树,再访问根,最后中序遍历右(左)子树。
后序遍历
首先后序遍历左(右)子树,再后序遍历右(左)子树,最后访问根。
该题目中,前序遍历为a,e,b,d,c,所以根节点为a。假设a有两个子节点,由于前序遍历中a的后面是e,所以e必定属于a的左子树中的节点。后序遍历中a的前面紧挨着的是e,所以e必定是a右子树的节点,相互矛盾,所以a只有一个孩子节点。而且在前序遍历中a跟e是紧挨着的,所以e是a的子节点。
9、下面哪种情况会导致持久区jvm堆内存溢出?
A.循环上万次的字符串处理
B.在一段代码内申请上百M甚至上G的内存
C.使用CGLib技术直接操作字节码运行,生成大量的动态类
D.不断创建对象
答案:C
解析:建议看看这篇博客,入门通俗易懂 http://blog.csdn.net/sivyer123/article/details/17139443
简单的来说 java的堆内存分为两块:permantspace(持久带)和heap space。
持久带中主要存放用于存放静态类型数据,如 Java Class, Method 等,与垃圾收集器要收集的Java对象关系不大。
而heapspace分为年轻带和年老带 ,
年轻代的垃圾回收叫Young GC,年老代的垃圾回收叫Full GC。
在年轻代中经历了N次(可配置)垃圾回收后仍然存活的对象,就会被复制到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象 。
年老代溢出原因有:循环上万次的字符串处理、创建上千万个对象、在一段代码内申请上百M甚至上G的内存,既A B D选项。
持久代溢出原因:动态加载了大量Java类而导致溢出。
10、一棵124个叶结点的完全二叉树,最多有()个结点
A.247
B.248
C.249
D.250
E.251
答案:B
解析:由于该树是完全二叉树,所以叶子节点只会存在于第h层跟第h-1层,假设第h-1层的叶子节点数为x,第h层的叶子结点数为y,那么有x + y=124。根据完全二叉树的性质,可以得知第h-1层的数量是2的N次方,那么可以确定h-1层的节点数有64个,可以得到x + y/2(向上取整)=64,可以解得y=120或y=121,取y=121,可以有1 + 2 + 4 + 8 +16 +32 + 64 +121 = 248。(解题时也是这么算的,居然算错了,尴尬)。
看了别人的解析,根据完全二叉树的性质:
n=n0+n1+n2
n:节点总数
n0:度为0的节点个数,也就是叶子节点
n1:度为1的节点个数,在完全二叉树中值有0和1这两种情况
n2:度为2的节点个数
又因为 n0=n2+1 所以n2=123,n1取较大的1
结论 n=n0+n1+n2=124+1+123=248
11、已知串S=′aaab′,其Next数组值为()
A.0123
B.1123
C.1231
D.1211
答案:A
解析:Next数组的解法:
next数组的求解方法是:第一位的next值为0,第二位的next值为1,后面求解每一位的next值时,根据前一位进行比较。首先将前一位与其next值对应的内容进行比较,如果相等,则该位的next值就是前一位的next值加上1;如果不等,向前继续寻找next值对应的内容来与前一位进行比较,直到找到某个位上内容的next值对应的内容与前一位相等为止,则这个位对应的值加上1即为需求的next值;如果找到第一位都没有找到与前一位相等的内容,那么需求的位上的next值即为1。
对于本题,求next值的过程:
前两位:next数组值前两位一定为01,即aaab中的前两位aa对应01,如上表中next第1,2位为0和1.其实这就可以选出答案了.
第三位:3a前面是2a(2a表示序号为2的a),2a的next数组值为1,将2a和1a相比,两者相同,都是a,则3a的next值为2a的next值加1,即2;
第四位:4b前3a的next为2,3a与2a相比,二者相同,则其next值为2a的next加1,为3.
结果为0123,选A
如果比较的时候碰到与前一位字符“不同”怎么办?那就以前一位的next值为序号,找到这个序号对应的字符,再进行比较,如果与之相同,就用这一位的next值+1,如果不同就继续重复这个操作直到找到相同的字符为止。如果一直重复到第一位还找不到,则将所求位的next值置为1。
此种解法请看:https://blog.csdn.net/iamyvette/article/details/77433991
看了其他博客:https://blog.csdn.net/gesanghuazgy/article/details/52214718
此种解法答案为:-1012
还有博客:https://blog.csdn.net/maotianwang/article/details/34466483
https://blog.csdn.net/to_be_better/article/details/49086075
则答案为:0120
可能Next数组的解法跟KMP算法实现有关,所以会有不同的解法或者他人的博客有错误也不一定,找个时间好好看看KMP算法。
12、关于计数排序的叙述中正确的是( )
A.计数排序是一种基于比较的排序算法
B.计数排序的时间复杂度为O(n+k)
C.计数排序的空间复杂度为 O(k)
D.计数算法是原地排序算法
答案:B C
计数排序:计数排序是一个非基于比较的排序算法,该算法于1954年由 Harold H. Seward 提出。它的优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中k是整数的范围),快于任何比较排序算法。当然这是一种牺牲空间换取时间的做法,而且当O(k)>O(n*log(n))的时候其效率反而不如基于比较的排序(基于比较的排序的时间复杂度在理论上的下限是O(n*log(n)), 如归并排序,堆排序)。
算法思想:
计数排序对输入的数据有附加的限制条件:
- 输入的线性表的元素属于有限偏序集S;
- 设输入的线性表的长度为n,|S|=k(表示集合S中元素的总数目为k),则k=O(n)。
在这两个条件下,计数排序的复杂性为O(n)。
计数排序的基本思想是对于给定的输入序列中的每一个元素x,确定该序列中值小于x的元素的个数(此处并非比较各元素的大小,而是通过对元素值的计数和计数值的累加来确定)。一旦有了这个信息,就可以将x直接存放到最终的输出序列的正确位置上。例如,如果输入序列中只有17个元素的值小于x的值,则x可以直接存放在输出序列的第18个位置上。当然,如果有多个元素具有相同的值时,我们不能将这些元素放在输出序列的同一个位置上,因此,上述方案还要作适当的修改。
算法过程:
假设输入的线性表L的长度为n,L=L1,L2,..,Ln;线性表的元素属于有限偏序集S,|S|=k且k=O(n),S={S1,S2,..Sk};则计数排序可以描述如下:
1、扫描整个集合S,对每一个Si∈S,找到在线性表L中小于等于Si的元素的个数T(Si);
2、扫描整个线性表L,对L中的每一个元素Li,将Li放在输出线性表的第T(Li)个位置上,并将T(Li)减1。