1、起因
接触爬虫之后,爬取某一网站的新闻标题,两端会出现的‘\t’,‘\r’,‘\n’等字符,小白的我喜欢用 .replace('\t', '').replace('\r', '').replace('\n', ''),把出现的‘\t’,‘\r’,‘\n’等字符置为空,虽然这样可以达到为想要的结果,但是代码量很大,代码很长,不提倡
2、改进及了解
某次在浏览网上大佬的代码发现他们写的爬虫喜欢在爬取标题的 xpath 后面添加 .strip() ,一查之下,发现了 strip() 的好用之处
2.1 用法
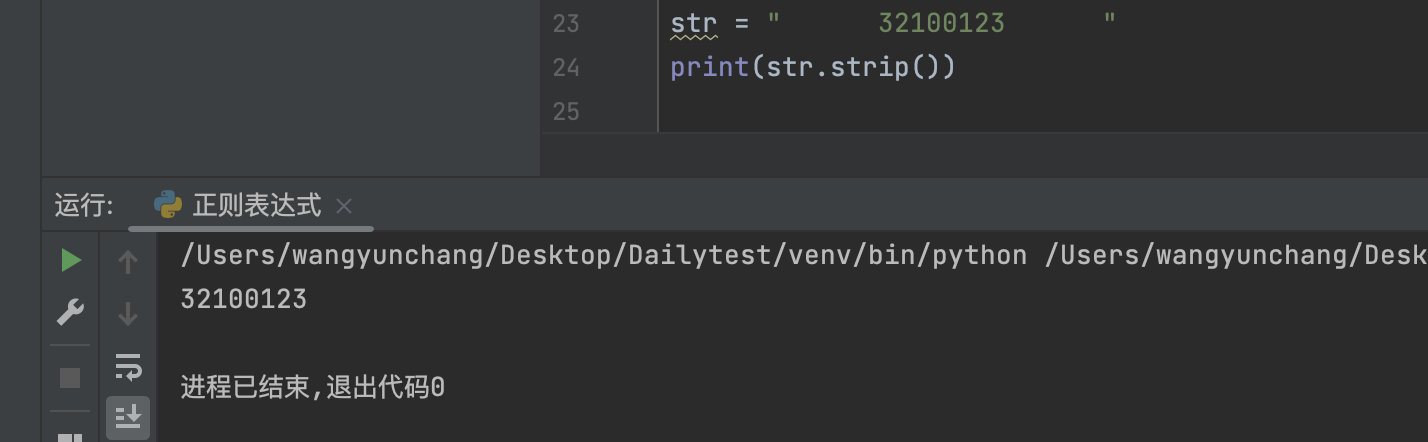
默认情况是切除字符串两端的空格、包括‘\t’,‘\r’,‘\n’
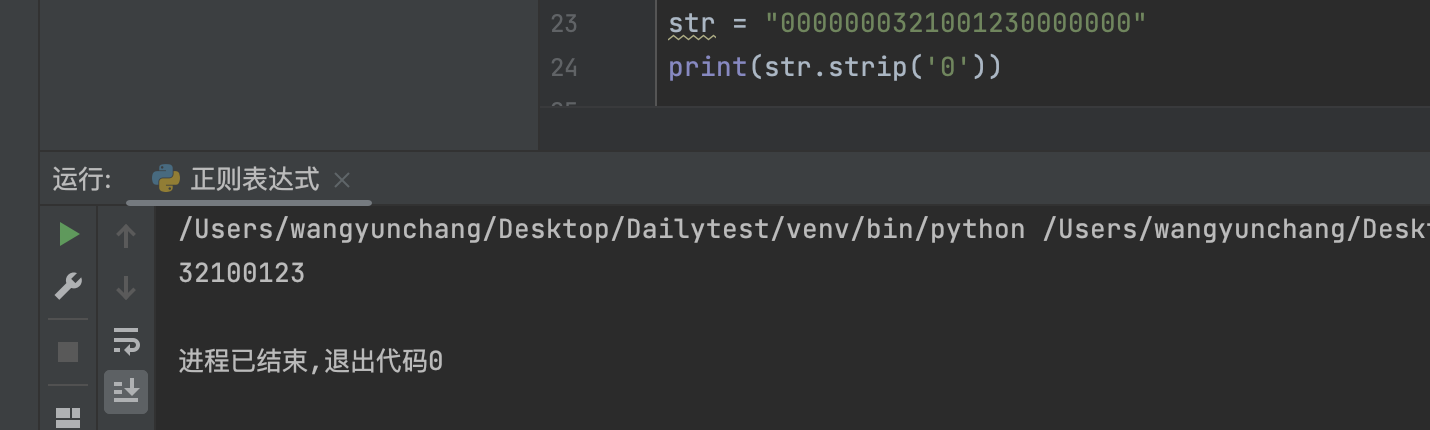
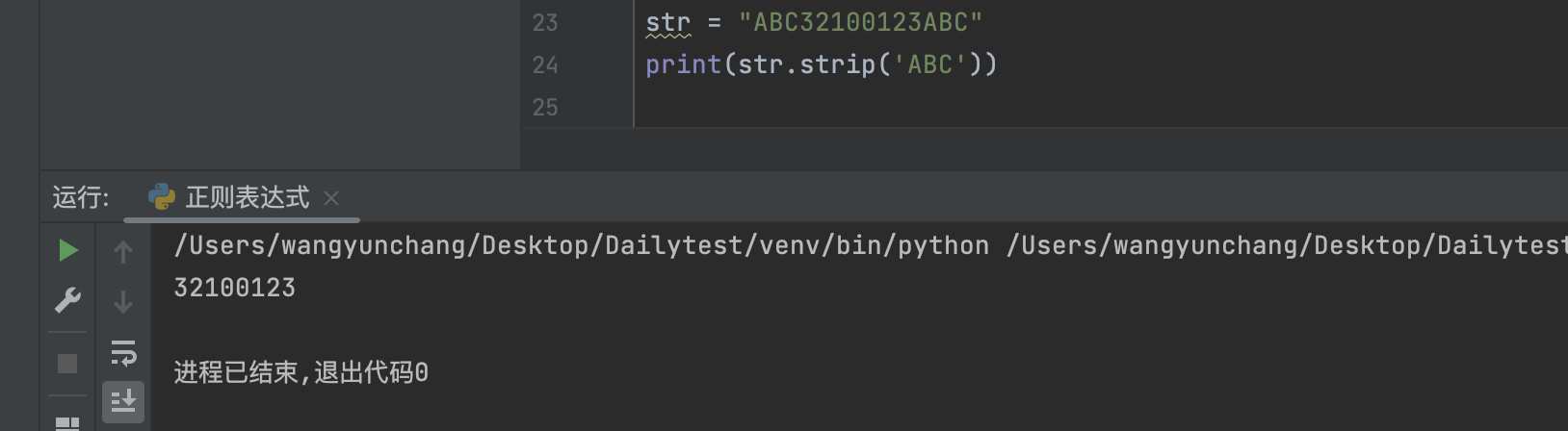
加入了参数之后就是去除字符串头尾指定的字符。
2.2 语法
Python中strip()语法:s.strip([chars])
2.3 样例