前言:
本文为本系列最后一篇,介绍键值查找的相关知识。
键值查找是具有聚集索引的表上的一个书签查找,键值查找用于SQLServer查询一些非键值列的数据。使用非聚集索引的查询不会有键值查找,但是所有键值查找会伴随非聚集索引出现。这里特别提醒的是键值查找总是伴有嵌套循环关联。
准备工作:
下面将创建一个表,通过执行计划看看键值查找的不同效果。为了产生键值查找,需要两件事情:
1、 聚集索引
2、 非聚集索引
当你在非聚集索引键值上有谓词时,查询的字段又不全部包含在非聚集索引上,需要通过聚集索引去查找,此时会产生键值查找。执行下面操作产生测试表:
[sql] view plain copy
1. USE AdventureWorks
2. GO
- 3.
- 4.
5. IF OBJECT_ID('SalesOrdDetailDemo') IS NOT NULL
- 6. BEGIN
- 7. DROP TABLE SalesOrdDetailDemo
- 8. END
9. GO
- 10.
- 11.
- 12.
13. SELECT *
14. INTO SalesOrdDetailDemo
15. FROM Sales.SalesOrderDetail
16. GO
步骤:
1、 在测试表SalesOrdDetailDemo上创建一个聚集索引和一个非聚集索引:
[sql] view plain copy
1. CREATE UNIQUE CLUSTERED INDEX idx_SalesDetail_SalesOrderID ON SalesOrdDetailDemo(SalesOrderID,SalesOrderDetailID)
2. GO
- 3.
4. CREATE NONCLUSTERED INDEX idx_non_clust_SalesOrdDetailDemo_ModifiedDate ON SalesOrdDetailDemo(ModifiedDate)
5. GO
2、 执行下面的查询,并开启实际执行计划:
[sql] view plain copy
1. SELECT ModifiedDate
2. FROM SalesOrdDetailDemo
3. WHERE ModifiedDate = '2004-07-31 00:00:00.000'
4. GO
3、 从执行计划的截图中看到,使用了一个非聚集索引(执行计划中叫做索引)查找:

如果你使用了文本化的执行计划,会看到:
| StmtText ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |--Index Seek(OBJECT:([AdventureWorks].[dbo].[SalesOrdDetailDemo].[idx_non_clust_SalesOrdDetailDemo_ModifiedDate]), SEEK:([AdventureWorks].[dbo].[SalesOrdDetailDemo].[ModifiedDate]=CONVERT_IMPLICIT(datetime,[@1],0)) ORDERED FORWARD) |
4、 对上面的查询语句进行少许的改动,多查询几列:
[sql] view plain copy
1. SELECT ModifiedDate ,
- 2. SalesOrderID ,
- 3. SalesOrderDetailID
4. FROM SalesOrdDetailDemo
5. WHERE ModifiedDate = '2004-07-31 00:00:00.000'
6. GO
5、 再检查执行计划:

它的文本化执行计划如下:
| StmtText ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |--Index Seek(OBJECT:([AdventureWorks].[dbo].[SalesOrdDetailDemo].[idx_non_clust_SalesOrdDetailDemo_ModifiedDate]), SEEK:([AdventureWorks].[dbo].[SalesOrdDetailDemo].[ModifiedDate]=CONVERT_IMPLICIT(datetime,[@1],0)) ORDERED FORWARD) |
6、 在上面的查询中添加的列均包含在聚集索引和非聚集索引中,现在增加更多的列:
[sql] view plain copy
1. SELECT ModifiedDate ,
- 2. SalesOrderID ,
- 3. SalesOrderDetailID ,
- 4. ProductID ,
- 5. UnitPrice
6. FROM SalesOrdDetailDemo
7. WHERE ModifiedDate = '2004-07-31 00:00:00.000'
8. GO
7、 查看执行计划,此时出现了两个新的操作符——键值查找和嵌套循环,如图:
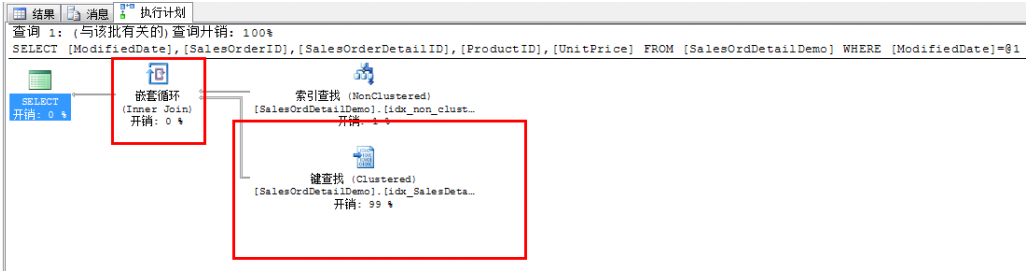
| StmtText ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |--Nested Loops(Inner Join, OUTER REFERENCES:([AdventureWorks].[dbo].[SalesOrdDetailDemo].[SalesOrderID], [AdventureWorks].[dbo].[SalesOrdDetailDemo].[SalesOrderDetailID], [Expr1004]) WITH UNORDERED PREFETCH) |--Index Seek(OBJECT:([AdventureWorks].[dbo].[SalesOrdDetailDemo].[idx_non_clust_SalesOrdDetailDemo_ModifiedDate]), SEEK:([AdventureWorks].[dbo].[SalesOrdDetailDemo].[ModifiedDate]='2004-07-31 00:00:00.000') ORDERED FORWARD) |--Clustered Index Seek(OBJECT:([AdventureWorks].[dbo].[SalesOrdDetailDemo].[idx_SalesDetail_SalesOrderID]), SEEK:([AdventureWorks].[dbo].[SalesOrdDetailDemo].[SalesOrderID]=[AdventureWorks].[dbo].[SalesOrdDetailDemo].[SalesOrderID] AND [AdventureWo |
8、 同时可以看到在键值查找上的百分比相当高,此时先试一下使用hint来改变优化器的行为:
[sql] view plain copy
1. SELECT ModifiedDate ,
- 2. SalesOrderID ,
- 3. SalesOrderDetailID ,
- 4. ProductID ,
- 5. UnitPrice
6. FROM SalesOrdDetailDemo WITH ( INDEX=idx_SalesDetail_SalesOrderID )
7. WHERE ModifiedDate = '2004-07-31 00:00:00.000'
8. GO
9、 此时优化器使用了聚集索引,但是不能在上面进行查找,只能扫描,如图:

10、上图中显示的聚集索引扫描在返回少量数据的时候并不高效,所以应该考虑就近是聚集索引扫描好还是键值查询好,现在来再开启SET STATISTICS IO 来监控一下IO情况,这次将三个查询都放到一起,其中两个是使用hint来分别把聚集索引和非聚集索引强制使用:
[sql] view plain copy
1. SET STATISTICS IO ON
2. GO
3. SELECT ModifiedDate ,
- 4. SalesOrderID ,
- 5. SalesOrderDetailID ,
- 6. ProductID ,
- 7. UnitPrice
8. FROM SalesOrdDetailDemo
9. WHERE ModifiedDate = '2004-07-31 00:00:00.000'
10. GO
- 11.
12. SELECT ModifiedDate ,
- 13. SalesOrderID ,
- 14. SalesOrderDetailID ,
- 15. ProductID ,
- 16. UnitPrice
17. FROM SalesOrdDetailDemo WITH ( INDEX=idx_SalesDetail_SalesOrderID )
18. WHERE ModifiedDate = '2004-07-31 00:00:00.000'
19. GO
- 20.
- 21.
22. SELECT ModifiedDate ,
- 23. SalesOrderID ,
- 24. SalesOrderDetailID ,
- 25. ProductID ,
- 26. UnitPrice
27. FROM SalesOrdDetailDemo WITH ( INDEX=idx_non_clust_SalesOrdDetailDemo_ModifiedDate )
28. WHERE ModifiedDate = '2004-07-31 00:00:00.000'
29. GO
30. SET STATISTICS IO OFF
31. GO
11、观察执行计划的开销情况:
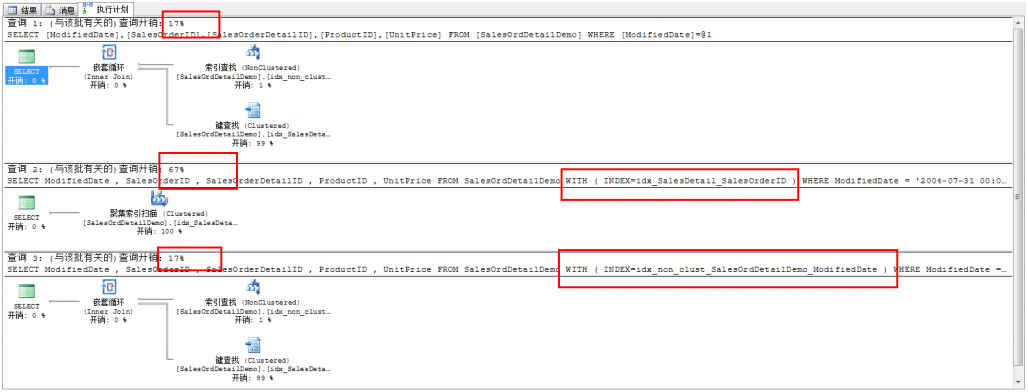
然后观察一下IO情况:

12、通过对比,带有键值查找的非聚集索引貌似有更好的性能,但是如果移除了键值查找会不会更好?现在来尝试一下,这里先删除原有索引并创建一个覆盖索引或者带有INCLUDE列的索引。通知先清空一下缓存:
[sql] view plain copy
1. DROP INDEX idx_non_clust_SalesOrdDetailDemo_ModifiedDate ON SalesOrdDetailDemo
2. GO
- 3.
4. CREATE NONCLUSTERED INDEX idx_non_clust_SalesOrdDetailDemo_ModifiedDate ON SalesOrdDetailDemo(ModifiedDate)
5. INCLUDE (ProductID,UnitPrice)
6. GO
- 7.
8. --不要在生产环境执行下面语句:
9. DBCC FREEPROCCACHE
10. DBCC DROPCLEANBUFFERS
11. GO
13、再次执行没有hint的查询
14、从执行计划中可以看到这次成功去除了键值查找:

同时可以观察到IO,发现从305次已经降到了3次

分析:
在第二步中,查询带有一个谓词来筛选ModifiedDate,所以非聚集索引将进行查找,且索引键上就有所需的数据,所以此时不需要再进行任何查找。
在第四步中,在SELECT列中添加了SalesOrderID和SalesOrderDetailID,由于这两列在聚集索引中,所以此时依旧可以使用非聚集索引引用聚集索引的方式来实现。
在第六步中,再次添加了新列,这些列不在任何索引的索引键中,所以非聚集索引必须通过聚集索引的叶子节点查找这两列新增列的数值,此时键值查找和嵌套循环关联就会出现。由于键值查找是高开销的操作,所以在第八步中使用了hint来强制优化器使用聚集索引。但是此时使用了聚集索引扫描而不是查找,所以现在要思考哪种方式更快?
为了得到答案,在第十步中把三个查询放到一起。一个是没有hint,一个是使用聚集索引hint,另外一个使用非聚集索引hint。
从第十一步的百分比看到,SQLServer使用了带有键值查找的非聚集索引来代替聚集索引扫描。
现在可以初步得出带有键值查找的非聚集索引查找比较快,但是是否有更快的方法?
因为UnitPrice和ProductID不在的时候键值查找会消失,但是有时候确实需要这些列,所以使用覆盖索引或者带有INCLUDE列的非聚集索引来代替普通的非聚集索引。通过12、13步可以看出已经移除了键值查找并有更好的性能。
出现键值查找的主要原因之一是因为谓词中出现了符合非聚集索引的规则,但是在SELECT中的字段不存在于聚集索引键值或者非聚集索引键值中。此时聚集索引必须通过键值查找来找出这些数据。