ISIM: Iterative Self-Improved Model for Weakly Supervised Segmentation
摘要
论文链接
代码链接
由于CAM是从分类网络中获得的,它们对对象中最具鉴别性的部分感兴趣,从而为分割任务产生不完整的先验信息。
为了获得更连贯的带有分割标签的CAM,我们提出了一种框架,该框架在改进的基于编码器-解码器的分割模型中采用迭代方法,同时支持分类和分割任务。由于没有给出真实的分割标签,该模型还利用密集条件随机场(dCRF)生成伪分割标签。因此,所提出的框架成为一个迭代的自我改进模型。
方法
利用CAMs提出了一个通用框架,迭代改进了基于编码器-解码器架构的语义分割模型
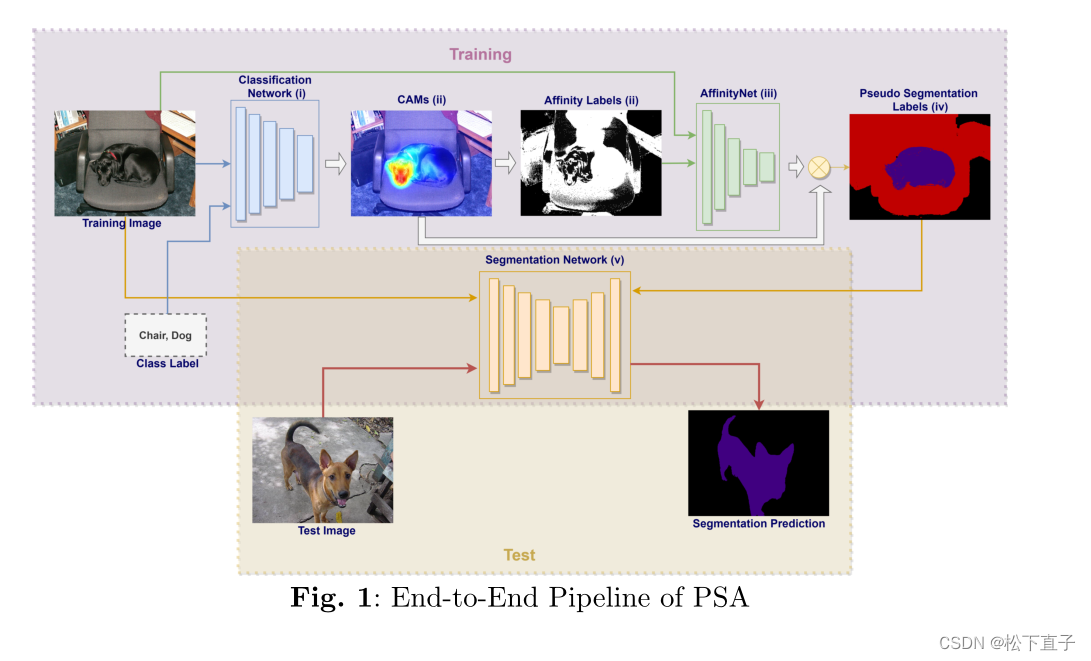
- 训练分类模型以获得CAMs
- 利用阈值和denseCRF从CAMs中生成像素级亲和标签
- 训练AffinityNet学习针对像素级亲和标签的类不确定像素相似度
- 结合CAMs和AffinityNet的预测生成分割标签
- 使用分割标签训练分割模型
分类模型首先获取带有分类标签的训练图像并生成cam。然后使用阈值和denseCRF对这些cam进行处理,以达到亲和标签。AffinityNet使用图像及其仿射标签进行训练。然后基于AffinityNet生成的仿射矩阵,在cam上应用随机游走算法生成分割标签。最后,将这些分割标签作为伪GT来训练分割网络。测试阶段使用Segmentation Network对测试图像进行分割。
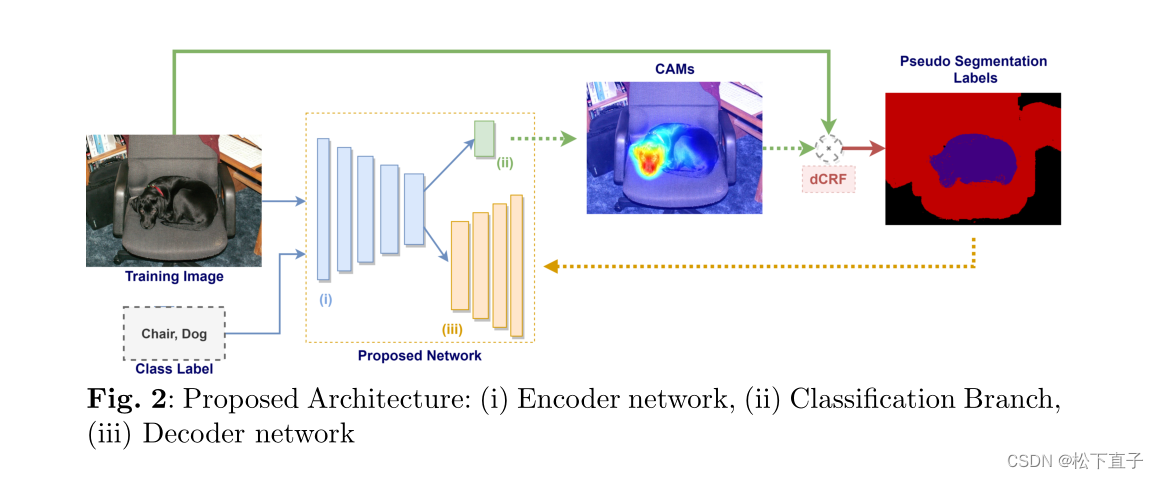
为了便于解释和形式化,它可以分为三个步骤,但在实践中,训练是在一个步骤中完成的,没有停止或开始。已知图像的训练集及其类标签,第一步是训练编码器网络,从中提取每个训练图像的CAM。这一步可以被认为是整个模型的初始化。第二步,利用denseCRF算法生成伪分割标签。最后,以伪分割标签为ground truth对整个模型进行再训练。伪分割标签生成和编解码器训练步骤采用了两种不同的方法。在第一个迭代中,迭代持续到收敛,在第二个迭代中,固定迭代尺寸
在训练过程中,我们利用denseCRF对CAMs进行细化,并将输出作为分割任务的伪ground-truth进行练习。在cam上使用denseCRF和访问分割标签有两个潜在的好处。首先,为了改进CAMs,将denseCRF的功率嵌入到编码器网络中。其次,图像的信息片段对模型来说变得更容易提取。在模型中生成并使用分割标签后,问题就变成了多任务学习。通过这些变化,编码器网络同时优化,分别通过分类和分割损失学习到与目标相关的判别区域和其他区域。假设,学习其他特征应该对cam产生积极影响,为了挑战这一假设,我们在提出的框架上进行了广泛的实验。
然而,在实践中,所提出的框架有两个潜在的问题,这两个问题会显著影响实验并使训练不稳定。
第一个是将伪分割掩码的每个像素标记为背景。第二个问题是分类或分割的损失抑制了另一个;因此,两者或其中一个开始发散。第一个问题被怀疑主要出现在分类网络没有足够的信心区分类别时。此外,由于对cam应用了阈值,因此区分类是不够的。该模型应具有较高的置信度得分像素大于阈值。此外,分类模型在预测上不是100%准确。因此,伪ground-truth存在不一致的可能,影响整个训练过程。当所有背景像素都作为分割任务的目标时,模型的解码器部分变得混乱。结果会影响编码器部分,并可能使分类损失发散。为了解决这个问题,当存在只涉及背景像素的分割掩码时,忽略该掩码,不计算特定图像的任何损失。
设yi为实例i应用CAM的阈值,定义为:
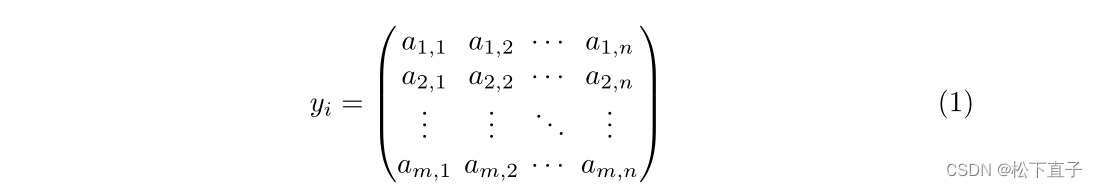
对一个实例的分割损失进行基本修改后,公式如下:
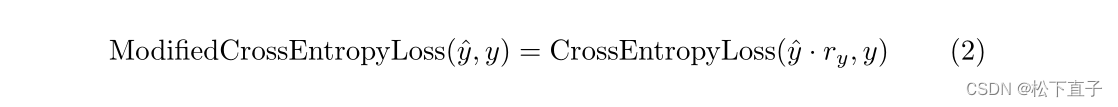
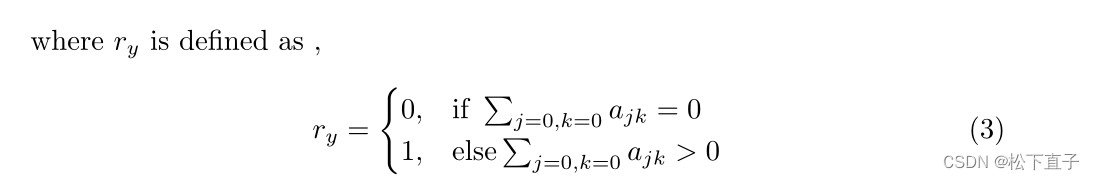
在第二个问题上,我们不是在每个epoch生成伪GT,而是以不同的频率创建它们,以便给网络提供一些空间来学习类和分段标签。
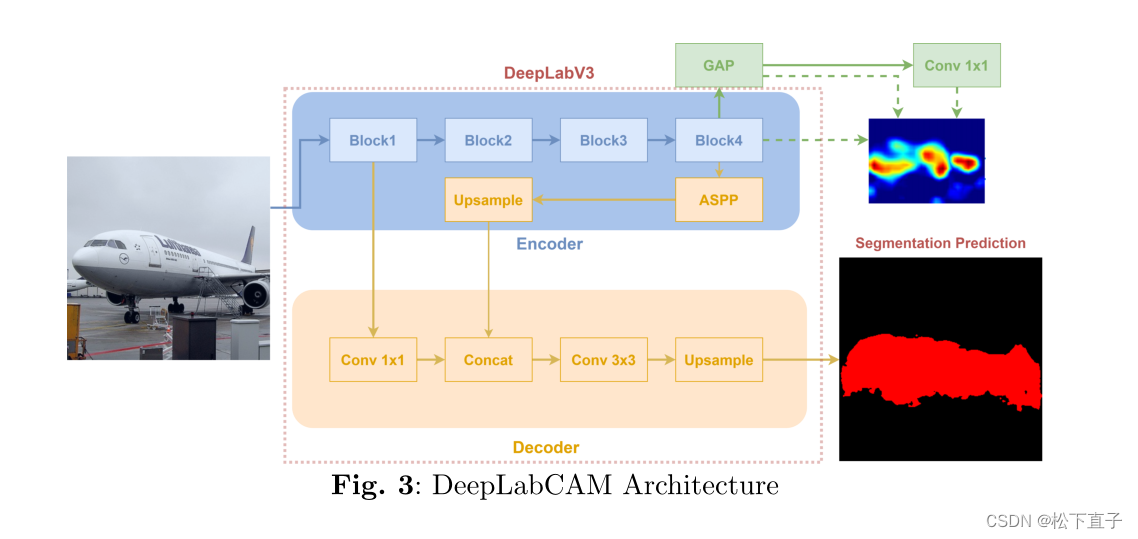
为了挑战所提出的框架和过程,我们将重点放在两个常见且众所周知的分割模型上,一个来自DeepLab家族DeepLabv3,另一个是UNet模型。DeepLabv3和UNet的原有架构按照推荐的方法进行修改。
我们研究中提到的改进后的架构叫做DeepLabCAM和UNetCAM