1.MoreKey案例
-
往redis里面插入大量测试数据key
- 生成100W条redis批量设置kv的语句保存在redisTest.txt
for((i=1;i<=100*10000;i++)); do echo "set k$i v$i" >> /tmp/redisTest.txt ;done; # 生成100W条redis批量设置kv的语句(key=kn,value=vn)写入到/tmp目录下的redisTest.txt文件中-
通过redis管道的–pipe命令插入100W大批量数据
cat /tmp/redisTest.txt | redis-cli -h 127.0.0.1 -p 6379 -a 123456 --pipe
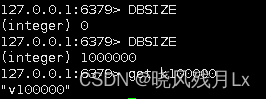
通过redis-cli登录查看是否成功
-
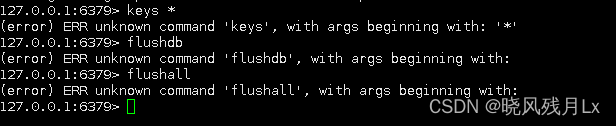
keys * / flushall / flushdb 危险命令
-
keys * / flushall / flushdb 严禁 在线上使用
-
keys * / flushall / flushdb 会造成阻塞,会导致Redis其他的读写都被延后甚至是超时报错,可能会引起缓存雪崩甚至数据库宕机
-
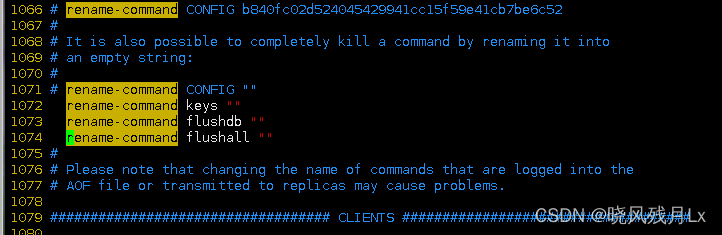
通过配置禁用危险命令
-
-
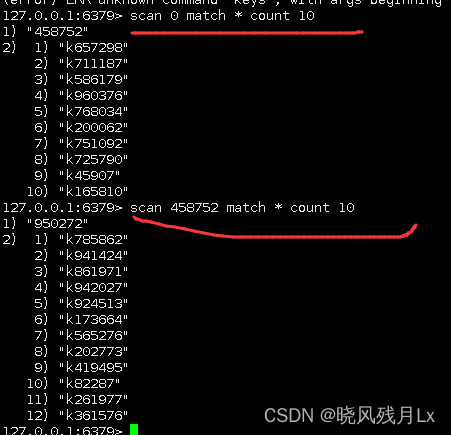
*scan 命令代替 keys ,避免卡顿
- 语法

-
特点

- SCAN 命令是一个基于游标的迭代器,每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。
- SCAN 返回一个包含两个元素的数组, 第一个元素是用于进行下一次迭代的新游标, 第二个元素则是一个数组, 这个数组中包含了所有被迭代的元素。如果新游标返回零表示迭代已结束。
- SCAN的遍历顺序非常特别,它不是从第一维数组的第零位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
-
使用
2.BigKey案例
2.1 多大算 BigKey以及它的危害
参考 《阿里云Redis开发规范》
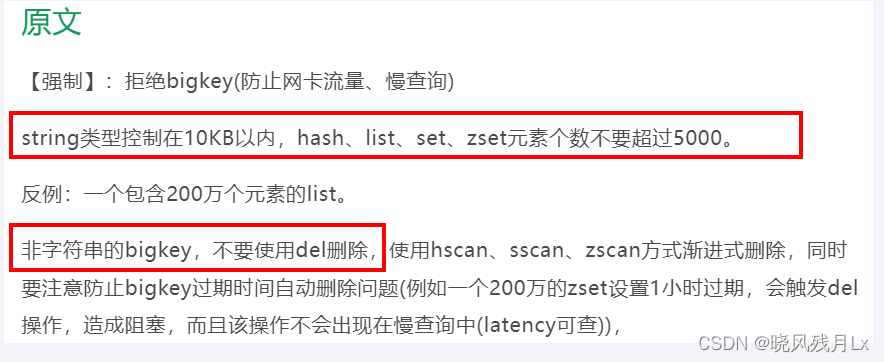
- string 是value,最大512MB但是 >= 10KB 就是bigkey
- list、hash、set和zset,个数超过5000就是bigkey
危害
- 内存不均,集群迁移困难
- 超时删除,大key导致阻塞
- 网络流量阻塞
2.2 如何产生、发现、删除
产生
-
社交类
粉丝列表逐步递增
-
汇总统计
某个报表,经年累月的积累
发现
-
redis-cli --bigkeys
-
redis-cli -h 127.0.0.1 -p 6379 -a 111111 --bigkeys //每隔 100 条 scan 指令就会休眠 0.1s,ops 就不会剧烈抬升,但是扫描的时间会变长 redis-cli -h 127.0.0.1 -p 7001 –-bigkeys -i 0.1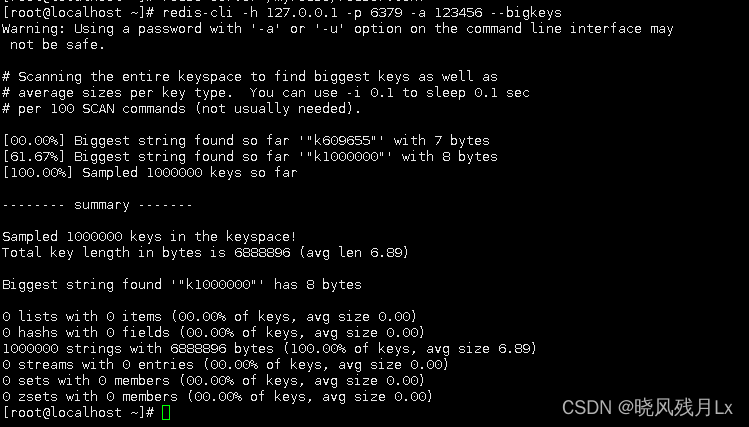
-
好处
- 给出每种数据结构Top 1 bigkey,同时给出每种数据类型的键值个数+平均大小
-
不足
- 想查询大于10kb的所有key,–bigkeys参数就无能为力了,需要用到memory usage来计算每个键值的字节数
-
-
memory usage
-
计算每个键值的字节数

-

-
删除bigkey
-
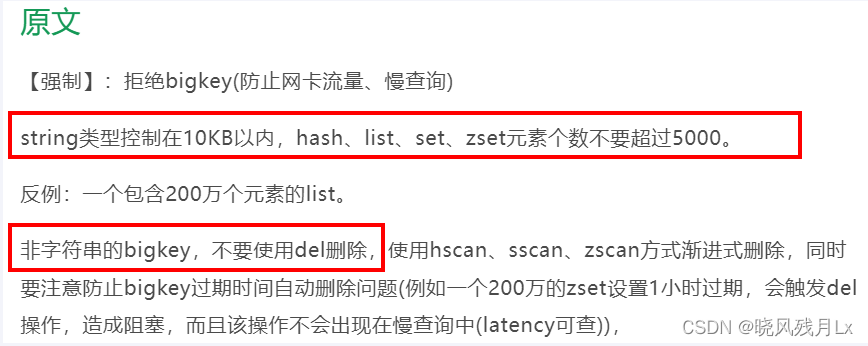
参考 《阿里云Redis开发规范》
-
普通命令
-
String
- 一般用del,过于庞大 unlink
-
hash
-
使用hscan每次获取少量field-value,再使用hdel删除每个field
-
语法
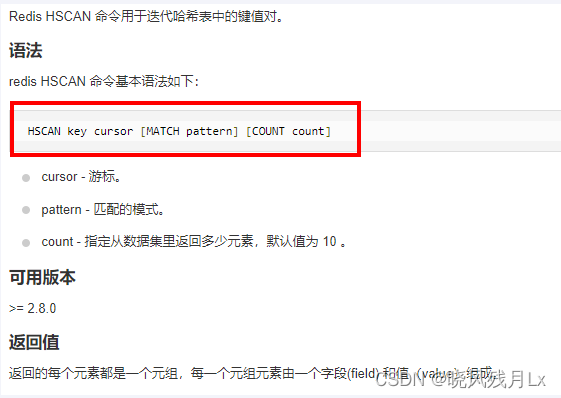
-
阿里手册
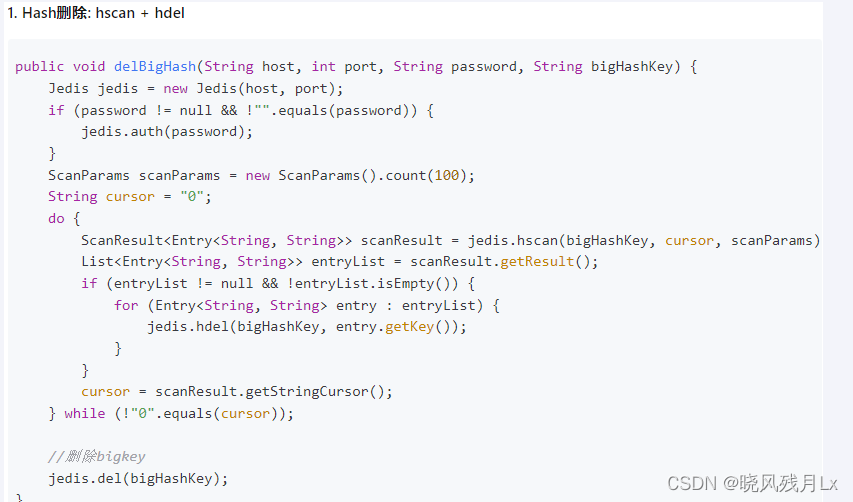
-
-
list
-
使用 ltrim 渐进式逐步删除,直到全部删除
-
命令
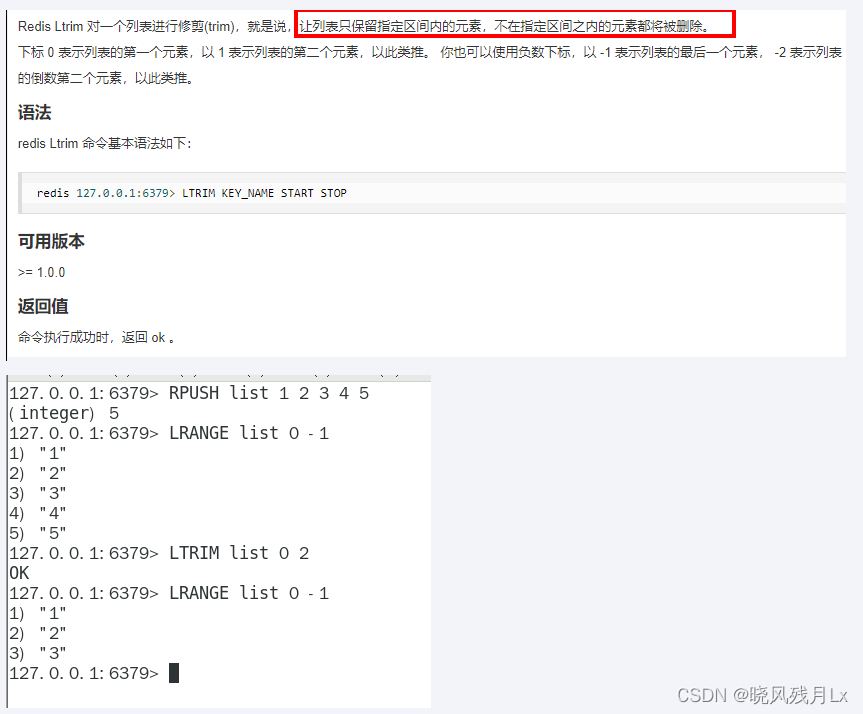
-
阿里手册
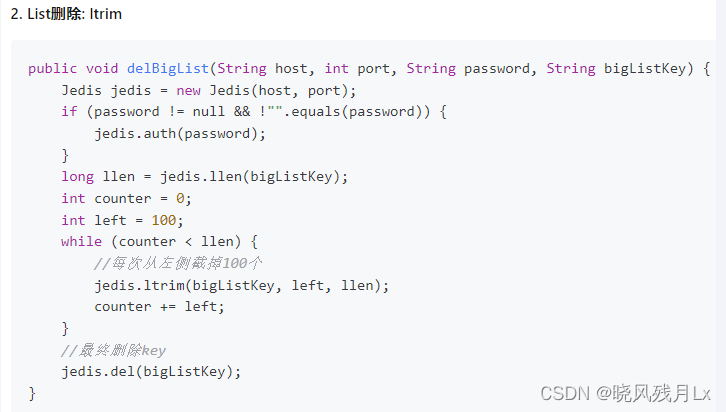
-
-
set
-
使用sscan 每次获取部分元素,再使用 srem 命令删除每个元素
-
命令
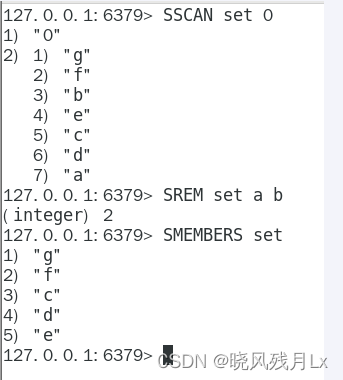
-
阿里手册
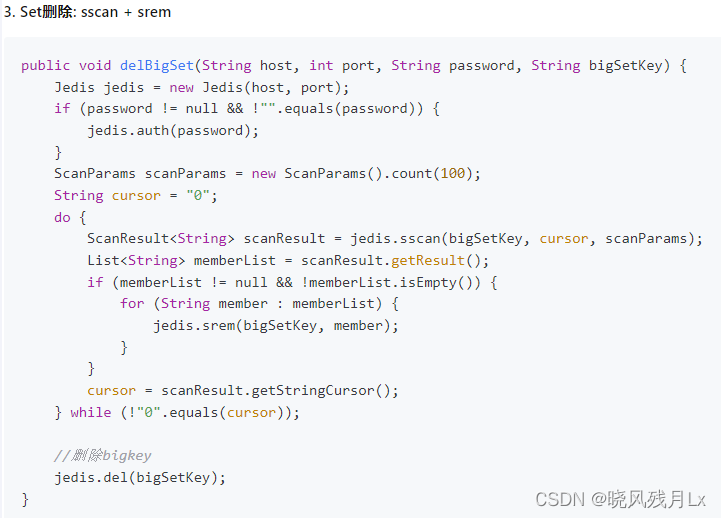
-
-
zset
-
使用zscan每次获取部分元素,再使用ZREMRANGEBYRANK 命令删除每个元素
-
命令
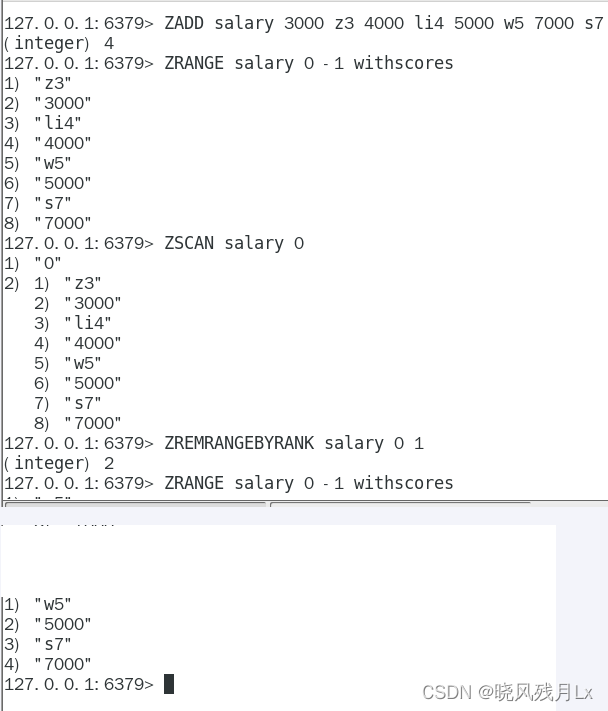
- 阿里手册
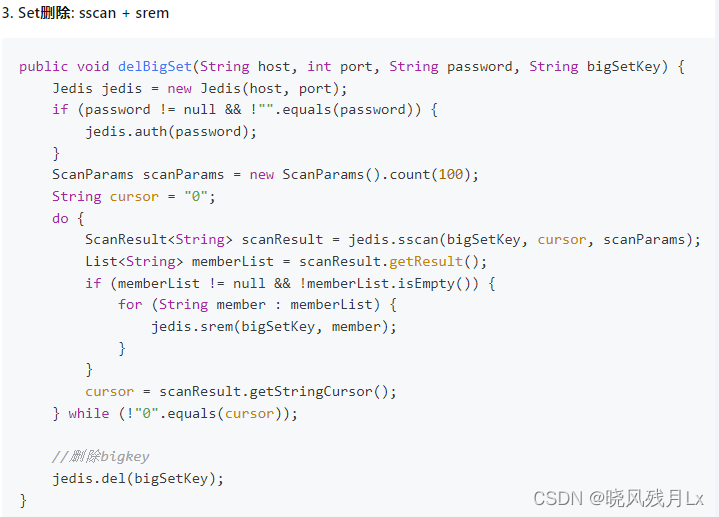
-
-
3. bigKey生产调优
- 阻塞和非阻塞删除命令

-
优化配置