摘要:
针对的问题:
1、当图像质量较差时,需要对指纹进行大量的预优化处理。这可能会引入错误的脊线图案,降低脊线图案的系统性能
2、指纹匹配算法的生物识别计算时间长,大型数据库上的指纹匹配可能效率低下
因此,提出HHACOFM:基于分层异质蚁群优化的指纹匹配算法
HHACOFM:在层次结构的不同级别具有蚂蚁代理,以找到输入和存储的脊模式之间的匹配
在四个数据集上进行了评估,具有并行性和可扩展性
个人身份识别对于保护数据免受网络攻击至关重要。随着身份盗窃的增加,指纹识别系统在加强安全和可靠的身份识别方面越来越重要。虽然大多数指纹识别系统使用细节特征进行指纹匹配,但当图像质量较差时,需要对指纹进行大量预处理。这可能会引入假脊模式,降低系统的性能。此外,指纹匹配算法的计算时间较长,在大型数据库上的指纹匹配效率较低。这就需要快速可靠的指纹识别系统。提出了一种从指纹中提取脊纹进行匹配的计算智能指纹识别系统。基于分层异构蚁群优化的指纹匹配算法(HHACOFM)在指纹匹配算法中使用不同层次的蚁体来查找输入的脊纹与存储的脊纹之间的匹配。在SFinGe工具生成的合成数据库、内部数据库、SOCOFing数据库和FVC2004数据库上对算法进行了评价。实验结果表明,与现有方法相比,该方法具有较高的识别率。与现有方法相比,hacofm算法的EER较低。结果通过统计检验得到验证。HHACOFM支持并行性,从而减少了响应时间。该方案具有可扩展性,适用于需要快速指纹验证的实时应用。
关键字: 指纹识别;分层异构蚁群优化;岭模式;生物识别技术
1、引言(注意使用的参考文献)
第一段:
首先,说明生物特征识别针对攻击的有效性(列举一些生物特征,指出指纹的独特性)
其次,通过文献引入指纹的可靠性和普遍性
最后,稍微说明可能的低质量存在的由故
近年来,由于网络犯罪的增加,可靠的个人身份识别已成为一个具有挑战性的问题。网上银行和电子商务应用程序的大量使用已引导使用生物识别系统来保护它们免受网络攻击。生物识别系统使用人的生理或行为特征作为可靠识别的特征(Maltoni 等人,2009 年)。指纹、声音、虹膜、面部等是生物识别系统用于可靠识别的一些生理特征。虽然没有可以断定为最佳特征的特征,但指纹因其独特性而受到青睐(Peralta 等人,2015 年)。指纹识别系统因其可靠性而受到欢迎,并且普遍首选以保护数据免受黑客意图欺诈(Maltoni 等人,2009 年;Peralta 等人,2015 年)。指纹由遗传和环境因素形成的脊和谷图案组成 (Patil & Ingle, 2021)。每个人的每个手指的纹路都是独一无二的,一生中无法改变。这种特性有助于将其用作身份标记。外伤和烧伤可能会暂时损坏指纹
第二段:
介绍指纹识别相关内容。分为识别的认证。有相关性、基于细节点和基于脊三种方法
指纹识别系统处理两个问题,即验证和识别。指纹验证涉及匹配两个指纹以确定它们是否对应于同一根手指。在指纹识别中,输入指纹与数据库中的所有指纹进行匹配(Peralta 等人,2017)。当两个指纹代表同一根手指时,它们被称为“真品”,当它们代表不同的手指时,它们被称为“冒名顶替”。指纹识别系统从训练集中学习模式,并能够将指纹分类为真品或假冒品。指纹比对是指纹验证和识别的重要环节。指纹匹配方法大致分为基于相关性、基于细节和基于脊的方法(Maltoni 等人,2009)。在基于相关性的匹配中,输入指纹和存储模板之间的相似性是通过匹配脊和沟的全局模式来查看脊是否对齐来发现的。但是,这种方法在指纹图像变换时不能使用。此外,基于相关性的方法会受到非线性失真、皮肤状况和手指压力的影响 (Maltoni et al., 2009)。
第三段:
介绍基于细节的识别方法。分为全局和局部,全局的效果不好,局部效果好,但是当局部细节识别遇到低图像质量时,不太适用。
N.K. Sreeja Intelligent Systems with Applications 17 (2023) 200180 基于细节的方法通过初始对齐细节然后计算匹配的细节数量来比较来自两个指纹的两个细节集。细节可以全局或局部匹配。全局细节匹配算法通过将所有细节视为一个集合来处理对齐过程。尽管全局细节匹配算法实现了高度的独特性,但它们的计算成本很高(Peralta 等人,2015)。局部细节匹配算法根据细节的局部结构比较两个指纹。局部细节匹配算法简单、容忍失真并且计算成本低。当图像质量差时,细节匹配方法不可靠。它们需要大量的预处理和图像增强技术来去除虚假的细节。
第四段:
介绍基于脊的方法。在大规模环境中对时间要求不高,但在实时环境中,在实时环境中需要减少响应时间
基于岭的方法从指纹图像中提取有用的特征并将它们分类为真实的或冒名顶替的。当图像质量太低而无法提取可靠的细节时,基于脊的方法是首选。当用于捕获指纹的传感器区域较小时,它们表现出比基于细节的算法更好的性能(Castillo-Rosado 和 Hern´andez-Palancar,2015 年;Maltoni 等人,2009 年)。基于脊的方法通常与基于细节的方法相结合以获得更好的性能。这进一步增加了计算复杂度。一些基于脊的方法提取脊的边缘以形成边缘轮廓并将它们用作指纹匹配的特征。大规模环境中的大多数指纹匹配算法都关注准确性而不是匹配所需的时间。在实时环境中,高响应时间等同于系统故障(Peralta 等人,2014 年)。这需要设计一种鲁棒且可扩展的指纹匹配算法,并减少响应时间。
第五段:
提出了本文的算法,将输入脊线与存储的脊线进行按位异或运算来比较二者的相似度。在大型的非分布式数据库中,可以并行执行,进而提高时间性能。
问题1:
引言部分对指纹识别的三种方法进行了介绍,然后在第五段就写了本文的算法,在这个中间衔接上可以再怎么修改呢?
提出一种基于层次异构蚁群优化的指纹匹配算法。所提出的方法提取脊的边缘并将它们转换为脊图案。脊纹是指纹的特征。由于脊线对于指纹是唯一的,因此提取的脊线图案也是唯一的。输入脊线模式和存储的脊线模式之间的相似性是通过对它们执行按位异或运算来计算的。如果相似度小于选定的阈值,蚂蚁代理将输入指纹识别为冒名顶替者。在大型非分布式数据库中,层次异构的蚂蚁系统保证了计算的并行执行,从而提高了时间性能。在四个数据库上进行了实验:(1)基于 SFinGe(合成指纹生成器)工具(Cappelli 等人,2002 年;Cappelli 等人,2004 年)的指纹数据库,模拟具有不同指纹质量的不同真实场景,( 2) 一个内部数据库,(3) FVC2004 数据库和 (4) SOCOFing 数据库。实验表明,该提案在这些数据库上显示出良好的性能。该提案在 FVC2004 数据库上与最先进的指纹匹配器(如 Bozorth3、VeriFinger、Minutiae 圆柱码、FingerCode 等)的性能揭示了该提案的稳健性。
贡献度的写作:
问题2:
一般第一个贡献是写提出方法的简述,3和4、5可以放到一起吗?还是说可以去突出4、5的重点?
1、 提出了一种基于层次异构蚁群优化的指纹匹配 (HHACOFM) 算法用于指纹识别。HHACOFM 算法从输入和存储的指纹中提取脊纹,并通过执行按位异或运算计算它们之间的相似度。
2、 HHACOFM 智能地分配计算,实现并行性,从而减少响应时间并使其适用于实时应用程序。(感觉这个算主要创新点)
3、 HHACOFM算法在四个数据库即SFinGe、SOCOFing、内部数据库和FVC2004数据库上进行了实验。实验结果表明,与其他指纹匹配方法相比,HHACOFM 算法具有良好的性能。
4 、与最先进的指纹匹配方法相比,HHACOFM 算法的 EER 非常低。
5、 HHACOFM 算法具有可扩展性,非常适合需要快速指纹验证的应用。
2、相关工作
第一段:(相关性方法)
因为文章是想针对低质量图像进行改进,所有刚开始说明指纹匹配的时候遇到的挑战(造成低质量的原因)。介绍基于相关性的方法及这些方法后续遇到的挑战,一环扣一环。
指纹匹配是一个具有挑战性的问题,因为它受到变形、压力、皮肤状况、位移和旋转等因素的影响。指纹匹配算法分为基于相关性、基于细节和基于脊的方法(Maltoni 等人,2009)。基于相关性的方法叠加输入和存储的指纹,并计算各种对齐的相应像素之间的相关性。然而,当输入指纹被移位或旋转时,基于相关性的方法会失败。此外,这些方法没有考虑非线性失真、压力和皮肤状况(Maltoni 等人,2009 年)。为了克服这个问题,提出了基于相关之前对称点对齐的方法 (Nilsson & Bigun, 2003) 和复杂的相关滤波器 (Venkataramani & Kumar, 2004)。基于相关性的方法会产生高计算成本。为了降低计算复杂度,提出了使用空间不变变换的算法 (Sujan & Mulqueen, 2002)。然而,这些方法需要对指纹进行预处理。Phase Only Correlation (POC) matcher (Ito et al., 2004) 是一种基于相关性的指纹匹配算法,具有很高的辨别能力,并且不随位移和亮度变化。然而,POC 匹配器非常慢,极大地限制了它在现实生活场景中的适用性 (Pober, 2010)。
第二段:(基于细节匹配方法)
介绍基于细节的指纹匹配方法,具体介绍全局和局部方法,在然而部分点出主题突出的可扩展性
基于细节的方法是最常见的指纹匹配方法 (Nachar et al., 2020)。基于细节的方法依赖于两个指纹的细节的对齐。全局细节匹配算法通过考虑整个细节集来处理对齐过程。由于全局细节匹配算法使用指纹的全部信息,因此它们具有很高的独特性(Peralta 等人,2017 年)。然而,全局细节匹配方法计算量大且对失真敏感(Peralta 等人,2017)。为了解决这个问题,可以在本地执行细节匹配。局部细节匹配技术从输入和存储的指纹中提取细节的局部结构并进行比较。它们对平移和旋转等全局变换具有容忍度,并且对失真不太敏感(Peralta 等人,2017)。殷等。为资源受限的物联网设备扩展了 Minutia 圆柱码,并为物联网环境提出了 eMCC (Yin et al., 2022)。Deshpandae 等人。 (Deshpandae et al., 2022) 提出了基于潜在细节相似性 (LMS) 和聚类细节的缩放和旋转不变指纹匹配 (CLMP) 算法进行指纹匹配。该提议在 FVC 数据库上取得了良好的准确性。Bakheet 等人。提出了一种基于改进的 SIFT 特征的指纹匹配算法 (Bakheet et al., 2022)。 但是,没有探索该方法的可扩展性。(自己论文中想要借鉴)
第三段:(三种指纹匹配器)
介绍了三种指纹匹配器,提出针对低质量图像时,会面临性能低的结果。点出主题低质量需要解决的必要性
细节圆柱码 (MCC)(Cappelli 等人,2010 年)、Bozorth3(Watson 等人,2010 年)和 VeriFinger(Neurotechnology 2010 年)是一些著名的基于细节的指纹匹配器。MCC 是一种有效的指纹匹配器,具有局部细节结构的高质量表示。MCC 特征考虑了细节与其邻居之间的相对关系,因此对平移、旋转和不变性具有鲁棒性。Bozorth3 是由美国国家标准技术研究院 (NIST) 开发的标准算法。该算法使用“mindtct”算法从输入指纹和存储的模板中检测细节,并计算它们之间的相似度分数。Bozorth3 对于平移和旋转是不变的。VeriFinger 是另一个基于商业细节的指纹匹配器,它是 N.K.Sreeja Intelligent Systems with Applications 17 (2023) 200180 容忍平移、旋转和变形(Pober,2010)。当只有很少的可用细节时,基于细节的方法表现不佳。此外,传统的细节匹配算法可能会导致错误的匹配结果,因为来自不同手指的不同区域的细节可能无法很好地匹配(Cao 等人,2012)。 此外,当指纹质量低时,不能使用基于细节的方法。在这种情况下,由于不需要的尖峰、孔等,可能会获得虚假的细节。因此,在提取可用的细节之前,需要大量的预处理和图像增强技术。(自己论文中学习借鉴)
第四段:(基于脊的指纹匹配方法)
第一句话与上面提出的低质量挑战进行二者衔接。(逻辑相扣,模仿)
列举基于脊的匹配方法文献,继续点可扩展性的主题。
当细节质量较差时,基于脊的指纹匹配算法是一个不错的选择。FingerCode (Jain et al., 1999) 是一种基于脊的指纹匹配器,它利用了指纹的局部和全局特征。它从输入和存储的指纹中提取特征向量,并通过找到它们之间的欧氏距离来计算特征向量之间的相似度。一些基于脊的方法提取脊的边缘轮廓以进行指纹匹配(Islam 等人,2010 年;Mohan 等人,2019 年;Ratiporn 等人,2015 年)。 但是,没有探索这些方法的可扩展性。许等。 (Xu et al., 2019) 提出了一种使用孔隙和边缘的高分辨率指纹识别系统。但是,当指纹质量差时,系统会失败。Chen (Chen, 2012) 提出了一种基于蚁群优化 (ACO) 的指纹识别系统,其中 ACO 用于图像分割,指纹基于最小梯度进行匹配。该方法在 20 个样本上实现了 90% 的准确率。纳查尔等。 (Nachar et al., 2020) 使用脊线的细节和边角来检测指纹中的特征点。
第五段:
讲述最近几年的深度学习方法进行的指纹匹配算法。
列举了一些方法,但同时去点训练时间很长、网络稳定性查(可以借鉴说自己论文的鲁棒性,对应去说这些文章的鲁棒性差)
近年来,研究人员一直专注于使用深度学习方法的指纹匹配算法。王等。 (Wang et al., 2014) 提出了一种基于深度神经网络的指纹识别系统。该方法使用方向场作为输入特征,并使用堆叠稀疏自动编码器对指纹进行分类。Patil 和 Suralkar (Patil Waghjale & Suralkar, 2013) 检测到脊线的边缘,从中提取特征并使用人工神经网络进行指纹匹配。该方法对小型数据集取得了可观的准确性。金等人。 (Kim et al., 2016) 提出了一个深度信念网络 (DBN) 来确定指纹的活泼性。诺盖拉等人。 (Nogueira et al., 2016) 使用卷积神经网络 (CNN) 进行活体检测。张等人。 (Jang et al., 2017) 提出了一种使用对比度增强和 CNN 检测伪造指纹的方法。 尽管其中一些方法取得了很好的准确性,但这些方法的训练时间很长(Hammad & Wang,2018)。乌利扬等人。 (Uliyan et al., 2020) 提出了一种使用深度受限玻尔兹曼机 (DRBM) 的指纹识别系统。Almajmaie 等。 (Almajmaie et al., 2019) 提出了一种基于联想记忆的指纹识别系统 (MMCA-AM)。 虽然 DRBM 和 MMCA-AM 取得了很好的精度,但图像的处理时间非常长。Stephane 和 Claude (Stephane & Claude., 2016) 使用反向传播网络 (BPN) 进行指纹匹配。丁卡等。 (Dinca et al., 2022) 提出了一种基于 CNN 的指纹识别系统来处理低质量指纹。 但是,网络的稳定性较差。 Saponara 等人。 (Saponara et al., 2021) 重建指纹图像并使用 CNN 自动编码器对其进行分类。 尽管基于深度学习的指纹匹配算法达到了合理的精度,但该方法的训练和识别时间很长。
第六段:
点题啦!!(模仿)
先说明相关工作中列举的文献缺乏可扩展性和需要高响应时间(可扩展性可以模仿)
文献中的大多数指纹匹配方法不适合大型数据库的指纹识别,因为它们缺乏可扩展性并且可能导致非常高的响应时间。因此,有必要设计一种计算智能的指纹匹配算法,在不影响准确性的情况下减少处理时间。本文提出了一种基于分层异构蚁群优化的指纹匹配算法,该算法可以智能地分配计算,实现并行性,从而减少响应时间。
3、基于分层异构蚁群算法的指纹匹配
这部分去介绍主题
问题3:
这部分写作是应该像文章中这样高度概括吗?需要再具体一点描述吗?
本节介绍了一种用于指纹匹配的分层异构蚁群优化算法。该算法有多个蚂蚁代理在层次结构的不同级别上运行,以计算输入指纹和存储的指纹模板之间的相似性。相似度大于固定阈值的存储指纹被认为是匹配指纹。
3.1. 分层异构蚁群优化
介绍了蚁群优化算法和蚁群算法,在蚁群算法中引入异质性概念
蚁群优化 (Dorigo & Stutzle, 2005) 是一种模仿蚂蚁行为的元启发式算法。在蚁群优化中,一组蚂蚁表示一组计算上并发的代理,在代表问题部分解的问题状态中移动。他们通过应用基于路径和吸引力的随机局部决策策略来移动(Maniezzo 等人,2004 年)。每只蚂蚁在移动过程中逐渐构建解决方案。当蚂蚁找到解决方案时,它会评估解决方案并修改用于找到解决方案的组件的值。将来,其他蚂蚁会使用此信息来找到解决方案。
AOC算法:蚁群算法(在前文没有描述,突然出现了)
此外,ACO 算法使用其他两个因素,即信息素蒸发和可选的守护程序操作。信息素蒸发有利于探索新路径,守护进程动作用于实现单个蚂蚁代理无法执行的动作 (Maniezzo et al., 2004)。已发现 ACO 可以成功解决许多组合问题。J-W 引入了蚂蚁智能体中 异质性的概念。李和 J-J。李 (Lee & Lee, 2010)。每组蚂蚁都有不同的目的,它们的信息素规则也各不相同。这些异类群体共同努力寻找最佳解决方案。在 分层异构蚁群优化 (Rusin & Zaitseva, 2012) 中,一组蚂蚁代理在层次结构的不同级别工作。每个级别的蚂蚁代理都受约束约束,它们在自己的搜索空间中进行搜索。蚂蚁管理器位于层次结构的顶部,并监视层次结构其他级别的蚂蚁代理。
注意:分层异构蚁群优化的概念并不是作者首先提出的,应该是首个应用到指纹识别中去的,在后面对比实验中如何进行对比设计的呢(注意学习模仿)
3.2、指纹脊纹的提取
使用Canny边缘检测算子进行特征提取(去噪)
使用 Canny 边缘检测算子 (Canny, 1986) 提取脊的边缘并转换为脊图案。图 1(a)和(b)分别显示了样本指纹和 canny 算子生成的相应输出。M × N 指纹的脊纹是一个 M 行 N 列的布尔矩阵。模式中的值“1”表示存在脊,值“0”表示不存在脊。图 2(a)和(b)分别显示了从 SOCOFing 数据库中选择的大小为 40×40 的样本指纹和相应的脊纹。
Canny边缘检测因子:(注意全文在这部分的描述手法,可以学习模仿)
1、去噪。噪声会影响边缘检测的准确性,因此首先要将噪声过滤掉。
2、计算梯度大小和方向。
3、非极大值抑制。就是适当的让边缘'变瘦'。
4、确定边缘。使用双阈值法确定最终的边缘信息。

图1所示:(a)指纹样本 (b)图1(a)中指纹脊的边缘。

图2所示:(a)来自SOCOFing数据库的指纹样本(b)图2(a)中的指纹脊状图。
3.3、基于分层异构蚁群优化的指纹匹配
详细描述,给出系统架构(这部分描述的很详细,正是自己在论文中的短板,学习模仿,坚信自己做的东西可以!!!)
假设有 m 个存储的指纹,分别用 SF1、SF2、...、SFm 表示,I 是输入指纹。存储的和输入的指纹大小为 p*n。如第 3.2 节所述,获得存储指纹的脊线图案。设存储指纹SF1、SF2、…、SFm的脊纹分别为E(SF1)、E(SF2)、…、E(SFm)。脊图案的大小为 p*n。 HHACOFM 算法为输入指纹 I 找到匹配的存储指纹。HHACOFM 算法选择一组异构的蚂蚁代理。这些蚂蚁代理被放置在层次结构中的三个级别。第 3 级在层次结构中位于顶部,包含一个蚂蚁管理器。蚂蚁管理者监督每一级蚂蚁代理的整体功能并获得解决方案。第 2 级和第 1 级蚂蚁代理的数量由蚂蚁管理器确定,如等式 1 所示。 图 3 显示了所提出的指纹识别系统的模型。
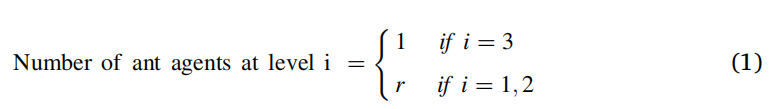
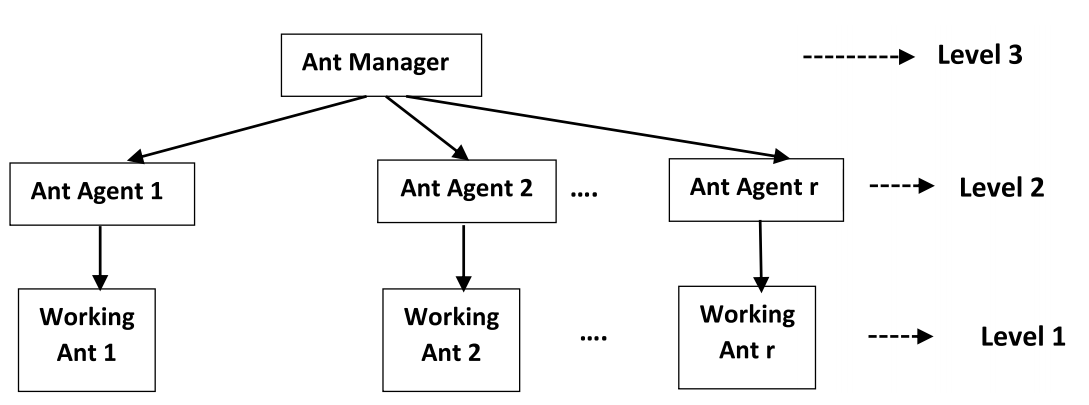
图3所示:指纹识别系统模型。
存储指纹的脊线图案作为输入提供给蚂蚁管理器。蚂蚁管理器将脊线模式存储在其表格列表中。如果存储的脊线模式数量大于 100,蚂蚁管理器会在 [40, 70] 范围内随机选择一个数字“r”。否则,r 的值为 2。'r' 表示第 2 级和第 1 级的蚂蚁代理数量,如等式(2)所示。
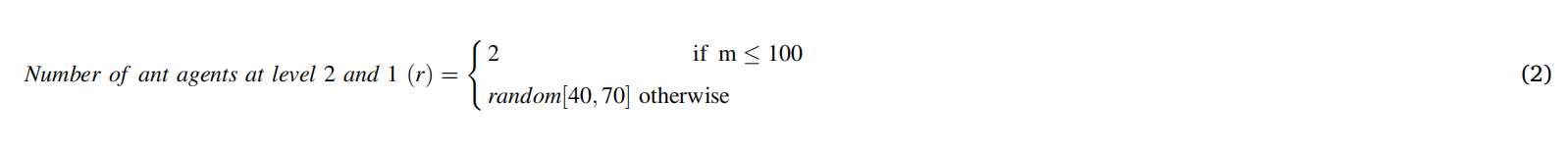
tabulist:
禁忌(Tabu Search)算法是一种元启发式(meta-heuristic)随机搜索算法,它从一个初始可行解出发,选择一系列的特定搜索方向(移动)作为试探,选择实现让特定的目标函数值变化最多的移动。
蚁群管理器的tabulist包含全局值和全局集。全局值初始化为0,全局集为空,如式(3)所示。
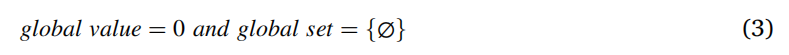
蚂蚁管理器将存储指纹的脊线模式划分为 r 个互斥子集 S1、S2、…Sr,并将每个子集 Si 分配给第 2 级的蚂蚁代理 Ai,如图 4 所示。
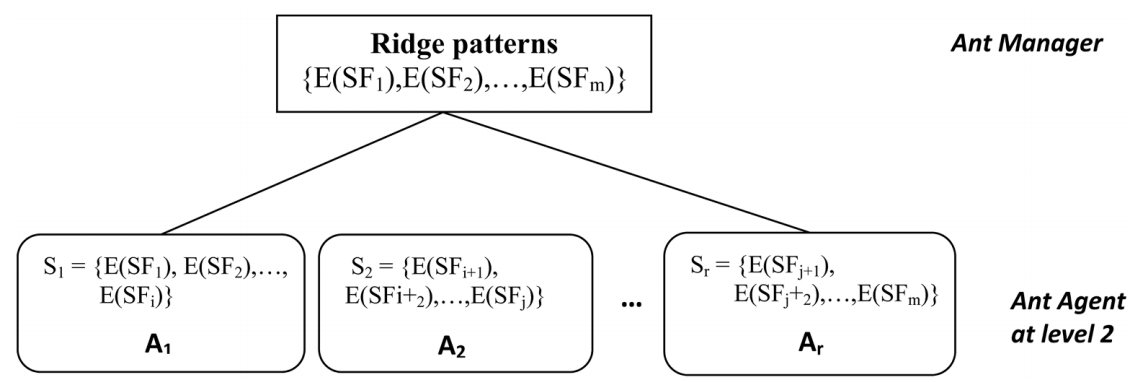
图4所示:由蚂蚁管理者分配脊型。
第 2 层的每个蚂蚁智能体 Ai 都有一个表示记忆的表格列表。表格包含两个变量“count_fingerprint”和“max_similarity”。 max_similarity 的初始值为 0。count_fingerprint 的初始值比等式 Si 中的子集 Si 中的脊图案数量大 1。如公式(4)

蚂蚁管理员提供输入指纹 I。蚂蚁管理器提取 I 的脊线模式并将其分配给第 2 层的所有蚂蚁代理。令 IN 表示提取的脊线模式。第 2 级的每个蚂蚁智能体 Ai 通过将 count_fingerprint 减 1 来存储信息素,并从子集 Si 中选择一个脊图案。令 M 表示所选模式。蚂蚁代理 Ai 将选择的模式 M 和输入模式 IN 分配给级别 1 的工作蚂蚁代理。
第 1 级的每个工作蚂蚁代理都有一个表格列表,其中包含一个变量“similarity_score”,用于存储输入和所选脊线模式之间的相似性。 similarity_score 的初始值为 0。工作的蚂蚁代理存放信息素并对 IN 和 M 中的值执行按位异或运算。XOR 运算返回零的次数按等式计算,用公式(5 和 6)并将结果存储在 similarity_score 中。
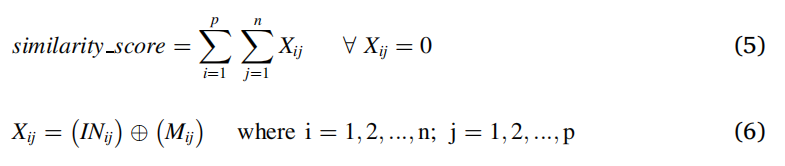
图5显示了在脊模式之间执行位异或操作的工蚁代理。

图5所示:工作蚂蚁代理执行按位异或操作。
工作的蚂蚁代理将其表列表中的 similarity_score 值发送给相应的第 2 级蚂蚁代理。第 2 级的蚂蚁代理将 similarity_score 的值与其 tabulist 中的 max_similarity 的值进行比较。如果 similarity_score 小于 max_similarity,则第 2 层的蚂蚁智能体移动到下一条路径。如果 similarity_score 大于 max_similarity,则第 2 层的蚂蚁智能体会找到等式中的相似度百分比,如公式 (7)。

如果相似度的百分比大于或等于0.96的阈值,第2级的蚂蚁代理用公式(8)中的similarity_score更新其tabulist中的' max_similarity '值。与similarity_score相对应的脊状图也会在其tabulist中更新。否则,max_similarity不会更新。选择阈值0.96来适应指纹的变形和失真。
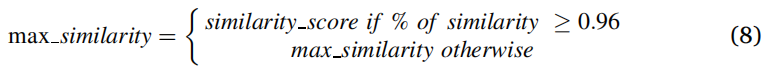
第 2 级的蚂蚁代理通过信息素蒸发移动到下一条路径。它再次通过将 count_fingerprint 减 1 来沉积信息素。它现在从子集 Si 中选择另一个脊线模式并将其分配给级别 1 的工作蚂蚁代理。第 1 级的工作蚂蚁代理发现输入脊线模式与从 Si 中选择的脊线模式之间的相似性。级别2的ant代理重复此过程,直到count_fingerprint的值为0。当count_fingerprint值为0时,第2级ant agent将max_similarity值发送给第3级的蚂蚁经理。
蚂蚁管理器将 max_similarity 值与其表列表中的全局值进行比较。如果 max_similarity 大于全局值,则使用 max_similarity 值更新全局值,并使用等式中相应的脊线模式更新全局集。 (9).否则,不更新全局值和全局集。在第2级的其他蚂蚁代理以同样的方式工作,最后,全局集包含与Eq.(10)中输入的ridge模式in最相似的ridge模式。在全局集中脊纹图案对应的指纹为匹配指纹。如果全局值为0,则表示给定输入指纹(I)没有匹配的存储指纹。HHACOFM算法伪代码如图6所示。

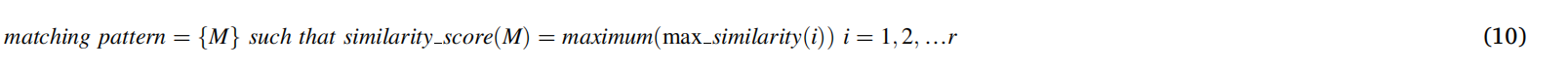

图6所示:HHACOFM算法伪代码。
4、案例研究
已经讨论了一个案例研究,用于将输入指纹与一组四个存储的指纹进行匹配。为了演示,假设所有指纹的大小都是 4 × 4。将存储的指纹表示为{SF1,SF2,SF3,SF4},对应的脊纹分别为E(SF1)、E(SF2)、E(SF3)和E(SF4)。第 3 层的蚂蚁管理员会看到存储指纹的脊线图案。由于呈现给蚂蚁管理器的模式数量少于 100,因此 r 的值为 2。因此,在第 2 层有 2 个蚂蚁代理,即 A1 和 A2。这些蚂蚁代理并行工作,为输入指纹找到匹配的存储指纹。每个蚂蚁代理 Ai 都有一个对应的工作蚂蚁代理,记为 Wi。由于 r = 2,蚂蚁管理器将存储指纹的脊线模式划分为两个互斥的子集,并将脊线模式 E(SF1) 和 E(SF2) 分配给 A1。类似地,E(SF3) 和 E(SF4) 被分配给 A2。令输入指纹为 I。为找到 I 的匹配存储指纹,HHACOFM 算法的工作原理如下。第 3 层的蚂蚁管理员被提供输入指纹 I。ant manager的tabulist中的global value和global set都是空的。蚂蚁管理器提取输入指纹 I 的脊线图案(IN),并将图案的副本发送给 A1 和 A2。
表 1 总结了蚂蚁代理 A1 和 A2 的工作。A1 的 tabulist 中 count_fingerprint 的初始值为 3,因为 A1 被分配了两个脊线模式 E(SF1) 和 E(SF2)。A1的tabulist中max_similarity的值为0。A1 通过将 count_fingerprint 减 1 来沉积信息素。它选择脊线模式 E(SF2) 进行比较。它将输入指纹的模式 IN 和存储指纹的模式 E(SF2) 发送给级别 1 的工作蚂蚁代理 W1。工作蚂蚁代理 W1 在 IN 和 E(SF2) 的值之间执行按位异或运算以查找相似性。表 2 显示了存储的带有 IN 的脊线模式的 similarity_score。从表 2 中可以注意到,由于 E(SF2) 和 IN 的所有位都相等,因此 E(SF2) 和 IN 的位异或结果 similarity_score 为 16。从表 1 可以看出,由于 E(SF2) 的 similarity_score 大于 max_similarity,A1通过将 max_similarity 除以脊图案的大小来找到相似性的百分比。可能会注意到 E(SF2) = 1 的相似性百分比。由于相似度百分比大于0.96,将A1表中的max_similarity更新为16,并将脊线图案E(SF2)存入A1表中。 A1的信息素蒸发了。 A1 移动到下一条路径,N.K. Sreeja Intelligent Systems with Applications 17 (2023) 200180 通过将 count_fingerprint 减 1 来沉积信息素。它现在选择下一个脊线模式 E(SF1) 并将其分配给级别 1 的工作蚂蚁代理 W1。W1 找到 IN 和 E(SF1) 之间的 similarity_score 并将 similarity_score 发送给 A1。从表 2 可以看出,E(SF1) 的 similarity_score 是 15。由于A1的tabulist中similarity_score小于max_similarity,所以max_similarity不更新。A1 重复这个过程,继续沉积信息素,直到 count_fingerprint 为 0。当 count_fingerprint 为 0 时,A1 将 max_similarity 值和对应的脊线模式 E(SF2) 发送给第 3 级的蚂蚁管理器。蚂蚁管理器将 max_similarity 与其表列表中的全局值进行比较。由于 max_similarity 大于全局值,全局值更新为 16,全局集更新为脊线模式 E(SF2)。
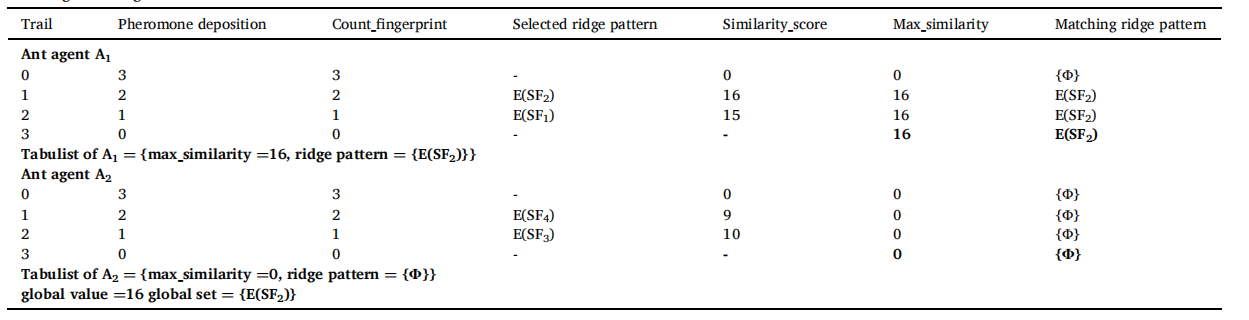
表1:蚂蚁agent在第2级的工作情况。
A2 的工作方式与 A1 相同。 A2的tabulist中max_similarity的值为0。它将脊线模式 E(SF3) 和 E(SF4) 分配给它的工作蚂蚁代理 W2。从表 2 中可以看出,E(SF4) 的 similarity_score 为 9。工作蚂蚁代理 W2 将 E(SF4) 的 similarity_score 发送给 A2。由于 E(SF4) 的 similarity_score 大于 max_similarity,A2 计算模式 E(SF4) 的相似度百分比。由于相似度百分比为0.56,小于阈值0.96,所以A2的tabulist中的max_similarity值没有更新,仍然为0。同样,将 E(SF3) 的相似度分数发送到 A2,由于 E(SF3) 的相似度百分比小于 0.96,因此不会更新 A2 的表格列表中的 max_similarity。A2 将 max_similarity 值发送给第 3 级的蚂蚁管理器。蚂蚁管理器将 max_similarity 值与全局值进行比较。由于 max_similarity 值小于全局值,因此不会更新全局值。最后,全局集包含脊线模式 E(SF2),全局值等于 16。因此,脊纹E(SF2)对应的存储指纹SF2是I的匹配指纹。
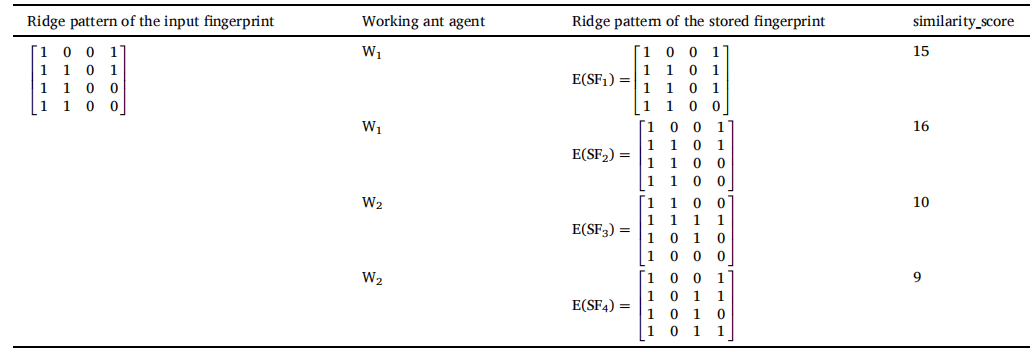
表2:脊型相似度评分。
5、 实验研究
本节简要介绍了为评估提案的性能而进行的实验的详细信息。首先,介绍了用于研究的数据库的描述,然后是用于评估 HHACOFM 算法的性能度量。HHACOFM 算法在 MATLAB 2016 中实现,系统配置为 Intel (R) Core (TM) i3-4130 [email protected] GHz 和 4 GB RAM。
5.1、数据库
四个数据库用于实验:SFinGe、SOCOFing、内部数据库和 FVC2004 数据库。NIST Special Database 4 (NIST-4)(Watson & Wilson,1992)被认为是文献中的基准数据库。由于该数据库没有适当的文档,因此无法再使用。因此,在其他数据库上进行了实验。
(a) SFinGe:SFinGe 是由 SFinGe 工具生成的合成数据库(Cappelli 等人,2002 年;Cappelli 等人,2004 年)。该数据库包括低质量指纹。用于生成指纹的参数如表 3 所示。使用该工具在不同压力和干燥度水平下生成了 50 个指纹,每个手指有两个印记。指纹受到不同距离的平移和不同程度的旋转。裁剪每个指纹以表示部分指纹。每个指纹经过四种不同的转换,最终数据库中有 50 * 6 = 300 个指纹。
图 7 (a) 显示了由 SFinGe 工具生成的高质量合成指纹。图 7(b)、(c)和(d)分别显示了相应的平移、旋转和部分指纹。图 8 (a) 显示了 SFinGe 工具生成的低质量合成指纹。图 8(b)、(c)和(d)分别显示了相应的平移、旋转和部分指纹。
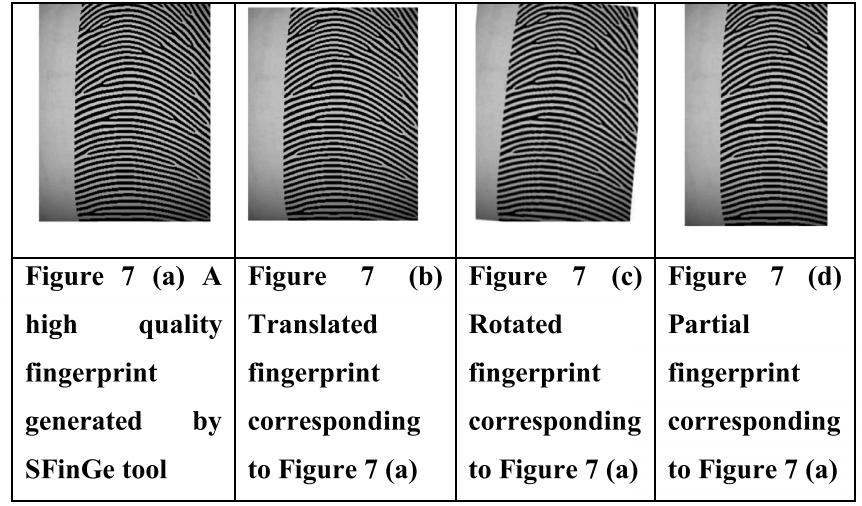
图7所示:(a) SFinGe工具生成的高质量指纹。(b)图7 (a)对应的平移指纹。(c)图7 (a)对应的旋转指纹。(d)图7 (a)对应的部分指纹。

图8所示:(a) SFinGe工具生成的低质量指纹。(b)图8 (a)对应的平移指纹(c)图8 (a)对应的旋转指纹(d)图8 (a)对应的部分指纹。
(a) Sokoto Coventry Fingerprint Dataset (SOCOFing):SOCOFing(Shehu 等人,2018 年)是一个专为学术研究目的而设计的数据库。它拥有来自 600 个非洲受试者的 6,000 个真实指纹图像。每个真实的指纹都使用抹去、中心旋转和 z 切进行综合更改,这是混淆和扭曲的常见方法。因此,数据库中有6000枚真实指纹和17931枚合成变造指纹图像(69枚合成变造指纹不可用)。每幅图像的大小为 96 × 103 像素。图 9 (a) 显示了来自 SOCOFing 数据库的样本指纹。图 9(b)、(c)和(d)分别显示了擦除、中心旋转和 z 切割后获得的指纹。
(b) 内部数据库:使用 ZK6000 指纹扫描仪收集 263 人的左手和右手拇指印象,每个人有 5 个印象。每张图片的分辨率为 500 dpi。内部数据库中的指纹总数为 263 * 5 * 2 = 2630。图 10(a)显示了来自内部数据库的样本指纹。图 10 (b)、(c) 和 (d) 分别显示了相应的平移、旋转和部分指纹。

图9所示:(a)来自SOCOFing数据库的指纹。(b)在第9(a)条指纹擦除后获得的指纹。(c) 9(a)中指纹中心旋转后获得的指纹。(d)在9(a)指纹上进行z字形切割后获得的指纹。

图10所示:(a)内部数据库的指纹。(b)图10 (a)对应的平移指纹(c)图10 (a)对应的旋转指纹(d)图10 (a)对应的部分指纹。
(c) FVC 2004 数据库:FVC2004 ( http://bias.csr.unibo.it/fvc 2004) 数据库有四组(DB1、DB2、DB3 和 DB4)灰度图像,每组有 80 个指纹。每个手指产生八个印象。数据库中的指纹总数为 80 * 8 =640。FVC2004 数据库中指纹的描述如表 4 所示。DB1 到 DB3 包含真实指纹,而 DB4 包含合成指纹。
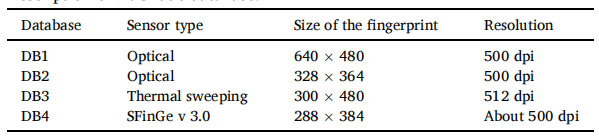
表4: FVC2004数据库描述。
5.2、性能的衡量
指纹识别系统的性能主要是根据其区分真假指纹的能力来衡量的。识别率(Accuracy)是衡量指纹识别系统整体性能的常用指标。定义为系统正确识别的指纹数与数据库中指纹总数的比值。错误不匹配率 (FNMR) 是指纹匹配系统无法匹配真实尝试的概率。另一个性能指标是错误匹配率 (FMR)。错误匹配率定义为指纹匹配系统接受冒名顶替者尝试并将其视为真正匹配的概率。FMR 和 FNMR 的比例相交的点称为等错误率 (EER)。EER 是一种独立于阈值的性能度量。低 EER 表示系统在此时的错误率降低时性能更好。
指纹识别系统的其他性能评估指标是错误拒绝率 (FRR) 和错误接受率 (FAR)。FRR 和 FAR 分别类似于 FNMR 和 FMR,只是它们是根据交易数量计算的。事务由一系列尝试组成。在进行的实验中,尝试次数限制为 1。因此,错误拒绝率 (FRR) 与 FNMR 相同,错误接受率 (FAR) 与FMR。实现非常低的 FAR 和 FRR 的指纹识别系统被认为是理想的。
6、实验结果
本节讨论在 SFinGe、SOCOFing、FVC2004 和内部数据库上进行的实验结果。将 HHACOFM 算法的性能与最先进的指纹匹配算法进行了比较,并进行了统计测试以验证结果。
6.1、HHACOFM在基准数据库上的性能
为了计算 FNMR,将生成的每个指纹与同一手指的其余样本进行匹配。这被称为真正的测试。因此,SFinGe、SOCOFing、internal和FVC2004数据库的正版测试总数分别为15*50=750、6*6000=36000、10*526=5260、28*80=2240。
为了找到 FMR,将每个手指的第一个样本与其余手指的所有样本进行匹配。这被称为冒名顶替者测试。因此,SFinGe 和 FVC2004 的冒名顶替者测试总数数据库分别为294*50=14700和632*80=50560。对于内部和 SOCOFing 数据库,从个体获得的每个样本都与从其余个体获得的其他样本相匹配。因此,内部和SOCOFing数据库的冒名顶替者测试数量分别为526 * 2620 = 1378120和6000 * 17901 = 107406000。
表 5 显示了 HHACOFM 算法在基准数据库上的性能。从表 5 可以看出,HHACOFM 算法能够识别 FVC2004、内部和 SFinGe 数据库的所有指纹。对于 SOCOFing 数据库,将 6000 个真实图像与 17931 个合成改变的样本进行了比较。HHACOFM算法从SOCOFing数据库的6000个指纹中识别出5976个指纹。从表 5 可以看出,SFinGe、FVC2004 和内部数据库的 HHACOFM 算法的 FMR 和 FNMR 为 0,表明其在区分冒名顶替者和真实用户方面的效率。HHACOFM 算法将 15 个冒名顶替者样本误识别为真实样本,HHACOFM 算法对 SOCOFing 数据库的 FMR 为 1.397e-07.同样,该算法将 24 个真实样本视为冒名顶替者。因此,SOCOFing数据库的HHACOFM算法的FNMR为6.667e-04

表5: HHACOFM算法的精度。
HHACOFM算法对SFinGe、FVC2004和内部数据库的识别率为100%。HHACOFM 算法对于像 SOCOFing 这样的大型数据库具有 99.6 ± 0.339(标准偏差)的高精度,证明了 HHACOFM 算法的可扩展性。HHACOFM 算法在所有数据库中的平均识别率为 99.9%。使用 SFinGe 工具生成的指纹经过几何变换。生成的每个指纹都被裁剪为代表部分指纹。从表 5 可以看出,HHACOFM 算法对 SFinGe 数据库的 FMR 和 FNMR 为 0,识别率为 100%,表明 HHACOFM 算法具有识别部分指纹的能力。HHACOFM 算法对 SOCOFing 数据库的识别率达到 99.6 ± 0.339 %,该数据库包含合成改变的指纹以表示失真和混淆。这证明了HHACOFM算法识别失真指纹的稳定性。
图 11 显示了来自 SOCOFing 数据库的少量指纹,这些指纹未被 HHACOFM 算法识别,并获得了相应的脊线。从图 11 可以看出,指纹的质量很差。由于只提取了很少的脊,HHACOFM 算法无法识别它们。
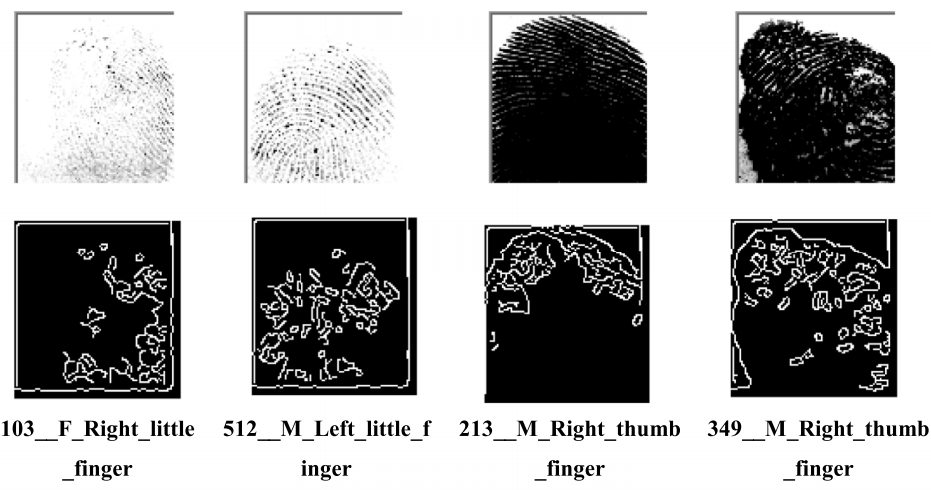
图11所示:SOCOFing数据库中无法识别的指纹。
表 6 和表 7 显示了不同阈值的数据库的 FMR 和 FNMR。SOCOFing 和 FVC2004 数据库的 FMR 和 FNMR 已经根据不同的阈值绘制,以判断指纹匹配系统的性能。图 12 显示了在阈值为0.93,0.94,0.95,0.96,0.97和0.98时,HHACOFM算法在SOCOFing数据库上的性能。从图12中可以看出,FMR和FNMR的图相交于1.089e−06,表明HHACOFM算法在SOCOFing数据库中的EER为0.000109%。

表6:不同阈值下的FMR。

表7:不同阈值的FNMR。

图12所示:不同阈值的SOCOFing数据库的FNMR和FMR。
图 13 显示了 HHACOFM 算法在 FVC2004 数据库上针对各种阈值的性能。从图 13 可以看出,两条曲线在 0 处相交,表明 HHACOFM 算法对 FVC2004 数据库的 EER 为 0。对于 SFinGe 和内部数据库,对于阈值 0.93、0.94、0.95、0.96、0.97 和 0.98,FNMR 和 FMR 为 0。因此,没有为这些数据库绘制 FMR 和 FNMR 的性能。表 8 显示了 FVC2004、SFinGe、SOCOFing 和内部数据库的 HHACOFM 算法的 EER。

图13所示:FNMR和FMR用于FVC2004数据库的不同阈值。
从表 8 可以看出,HHACOFM 算法对数据库 FVC2004、SFinGe 和内部数据库的 EER 为 0,表明 HHACOFM 算法的性能卓越。对于SOCOFing数据库,HHACOFM算法的EER为0.000109%。HHACOFM 算法的平均 EER 为 0.00002725%,表明 HHACOFM 算法在区分冒名顶替者和真实尝试方面的显着性能。

表8: HHACOFM算法的EER。
6.2、HHACOFM 与最先进方法的比较
将 HHACOFM 的识别率与流行的指纹识别方法(如 MMCA-AM、堆叠稀疏编码器和其他深度学习方法)进行了比较。此外,将 FVC2004 数据库的 HHACOFM 的 EER 与 POC 匹配器、MCC、VeriFinger、Bozorth3 和 Fingercode 等最先进的指纹匹配器进行了比较。
6.2.1、识别率
HHACOFM 算法的识别率已经与一些表现出良好准确性的指纹识别系统进行了比较,如 MMCA-AM(Almajmaie 等人,2019 年)、堆叠稀疏编码器(SSE)(Wang 等人,2014 年)、深度信念网络(DBN)(Kim et al., 2016)、卷积神经网络(CNN)(Nogueira et al., 2016)、对比度增强+CNN(Jang et al., 2017)、人工神经网络(ANN)( Patil Waghjale & Suralkar, 2013) 和反向传播网络 (Stephane & Claude., 2016) 使用 (Almajmaie et al., 2019; Hammad & Wang, 2018) 中报告的结果。HHACOFM 算法将 FVC2004 数据库中的所有 640 个样本识别为 MMCA-AM。
然而,MMCA-AM 无法识别内部数据库中 2500 个模式中的 13 个模式,MMCA-AM 对内部数据库的识别率为 99.48%。MMCA-AM同样不能识别NIST数据库中2000种模式中的16种,识别率为99.2%。但是,HHACOFM 算法对大多数数据库的识别率为 100%。值得一提的是,HHACOFM算法在SOCOFing数据库的6000个模式中只能识别出24个模式,HHACOFM算法对SOCOFing数据库的识别率为99.6%。表9显示了HHACOFM、MMCA-AM、SSE、DRBM+DBM、DBN、CNN、对比度增强+CNN、ANN和BPN得到的平均结果。从表 9 可以看出,HHACOFM 算法的平均识别率高于其他方法。图 14 显示了流行的指纹匹配算法的平均识别率。从图 14 可以明显看出,HHACOFM 算法实现了最好的平均识别率,而 ANN (Patil Waghjale & Suralkar, 2013) 实现了最低的识别率。

表9: HHACOFM算法平均结果比较。

图14所示:平均识别率的比较。
HHACOFM 算法在 FVC2004 数据库上的准确性已经与 Dinca 等人等最近的一些方法进行了比较。 (Dinca 等人,2022 年)、saponara 等人。 (Saponara 等人,2021 年)、未受保护的指纹细节、哈希指纹、修改后的哈希指纹细节(Ajish 和 AnilKumar,2020)、RNA-FINNT(Kaur,2015;Kaur 和 Ganesan,2012)、ANN(Patil Waghjale 和 Suralkar, 2013 年)、LMS(Deshpandae 等人,2022 年)、CLMP(Deshpandae 等人,2022 年)和 MMCA-AM(Almajmaie 等人,2019 年)使用(Ajish 和 AnilKumar,2020 年;Almajmaie 等人)中报告的结果。 ,2019 年;Dinca 等人,2022 年;Deshpandae 等人,2022 年;Saponara 等人,2021 年)。表 10 显示了方法在 FVC2004 数据库上的准确性。从表 10 可以明显看出,HHACOFM、CLMP 和 MMCA-AM 在其他方法中实现了 FVC2004 数据库的最高准确度。

表11:基于FVC2004数据库的EER。
6.2.2、FVC2004数据库中最先进指纹匹配器的EER
FVC2004 数据库的 HHACOFM 算法的 EER 已与 MCC、Bozorth3、VeriFinger、FingerCode 和 POC 匹配器等最先进的指纹匹配器进行了比较。表 11 使用(Nachar 等人,2020 年;Pober,2010 年;Yin 等人,2022 年)报告的结果显示了 HHACOFM 和 FVC2004 数据库上流行的指纹匹配器的 EER。由于 DB1-DB3 包含真实指纹,DB4 包含合成指纹,因此 DB1-DB3 的结果已在表 11 中进行了比较。从表 11 中可以看出,HHACOFM 对于所有三个数据库都实现了 0 的 EER,并且优于其他最先进的基于细节、脊和相关性的匹配器。

表11:基于FVC2004数据库的EER。
6.2.3、统计分析
配对 Z 检验是一种统计检验,用于确定两个配对组在感兴趣的变量上是否彼此显着不同。为了确定算法的结果之间是否存在显着差异,进行了配对 Z 检验。表 12 显示了 HHACOFM 算法与其他指纹匹配算法之间多次成对比较的平均识别率的配对 Z 检验结果。从表 12 可以看出,除了 Contrast enhancement + CNN [49] 之外的所有算法的 z 值都小于 -2.58(a=0.01)因此,MMCA-AM、SSE、DBN、CNN、ANN 和 BPN 具有统计显着性.从表 12 中还可以看出,MMCA-AM 达到了最高等级,它是与 HHACOFM 进行成对比较的最佳算法。该测试报告 HHACOFM 与 MMCA-AM 的 p 值为 1.4 e-05 低于 0.01。因此,HHACOFM 算法优于 MMCA-AM 和其他指纹匹配算法,成对比较的置信度大于 99%。
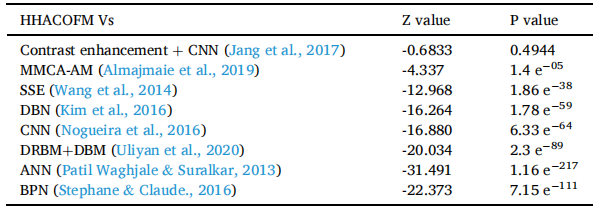
表12:指纹匹配算法平均识别率的配对z检验。
6.2.4、时间性能
实时环境中的指纹识别系统需要高精度和更少的匹配时间。大多数实时环境中的指纹匹配系统都获得了很好的准确性,但是匹配时间很长。HHACOFM 算法分布计算和指纹并行匹配。这减少了系统的匹配时间而不影响准确性。
将 HHACOFM 算法将输入指纹与存储的模板进行匹配所花费的时间与其他流行的指纹匹配算法的处理时间进行了比较。表 13 显示了 HHACOFM 算法匹配输入脊线 N.K. 所花费的时间。Sreeja Intelligent Systems with Applications 17 (2023) 200180 模式与存储的脊线模式。由于存储指纹的脊线模式在第 2 级的“r”个蚂蚁代理之间划分,因此许多模式是并行匹配的。由于 HHACOFM 算法在 [40, 70] 范围内选择 r,表 13 中的最小和最大时间分别表示当 r 等于 70 和 40 时蚂蚁代理所花费的时间。从表 13 中可以明显看出,HHACOFM 算法针对 17931 个存储模板找到输入指纹匹配所花费的最长时间仅为 4.4 秒,证明了 HHACOFM 算法的可扩展性。DRBM-DBM (Uliyan et al., 2020) 对输入指纹的处理时间约为 45 秒(系统配置:Intel (R) Xeon (R) CPU E5-2690 v2(3.00 GHz 处理器)和 20 GB RAM和 NVIDIA GPU)。虽然 MMCA-AM (Almajmaie et al., 2019) 获得了很好的精度,但 MMCA-AM 的处理时间为 32 秒 (Almajmaie et al., 2019)。DBN(系统配置:3.40 GHz 8 核 CPU 和 32 GB 内存)和 CNN 在 GPU 上的训练时间分别为 1 天和 5 小时(Kim 等人,2016 年;Nogueira 等人,2016 年)。虽然HHACOFM算法是在配置较低的系统上实现的,但即使在大型数据库中也能在不到五秒的时间内完成指纹匹配,适用于需要快速指纹验证的应用。图 15 显示了 HHACOFM 算法对 SFinGe、SOCOFing、内部和 FVC2004 数据库的匹配时间比较。从图 15 可以看出,HHACOFM 算法对所有数据库所花费的最大时间小于顺序匹配指纹所需的时间,使其适用于实时环境。
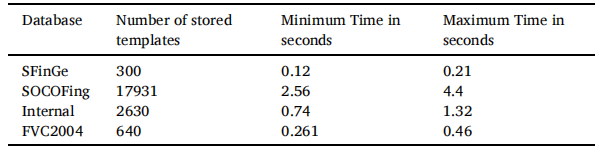
表13 :HHACOFM算法的匹配时间。
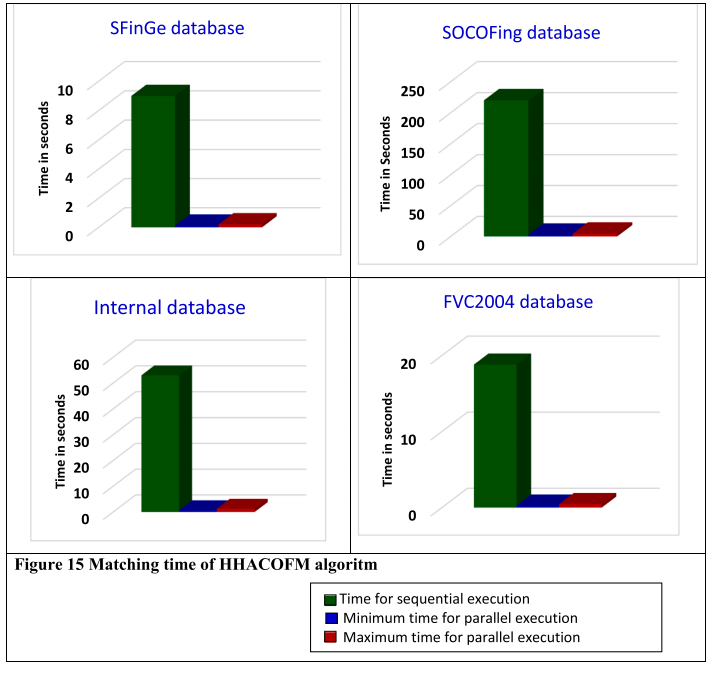
图15所示:HHACOFM算法的匹配时间。
7、结论
本文提出了一种基于层次异构蚁群优化的指纹识别系统。提取脊线的边缘并将其转换为用于指纹匹配的脊线图案。所提出的 HHACOFM 算法使用层次结构中不同级别的多个蚂蚁代理来查找输入和存储的脊线模式之间的匹配。在大型非分布式数据库中,层次异构的蚂蚁系统保证了计算的并行执行,从而提高了时间性能。与现有的指纹匹配算法相比,HHACOFM 算法表现出良好的性能。大多数数据库的 HHACOFM 算法的错误匹配率和错误不匹配率均为 0,表明其能够区分冒名顶替者和真实用户。该提案比 FVC2004 数据库的最先进的指纹匹配器实现了更低的 EER。该提案的平均 EER 为 0.00002725%。 HHACOFM 算法在识别失真和部分指纹方面是有效的。所提出的指纹识别系统实现了 99.9% 的平均识别率,将输入指纹与 17931 个存储模板匹配所需的最长时间为 4.4 秒。进行了统计测试以验证算法的性能。HHACOFM 算法具有可扩展性,非常适合需要快速指纹验证的应用。