如果大家觉得文章有错误内容,欢迎留言或者私信讨论~
书接上回,我们了解 Tomcat 的网络部分的架构设计,今天一起来看一下 Tomcat 的容器设计。之前我们提到 Tomcat 的两个核心组件:连接器和容器,其中连接器负责外部的交流,容器是内部的处理。具体来说,就是连接器负责 socket 的链接和应用层协议的转换,得到 servlet请求,而容器就是负责处理 servlet 请求,可以通过下图回忆一下:
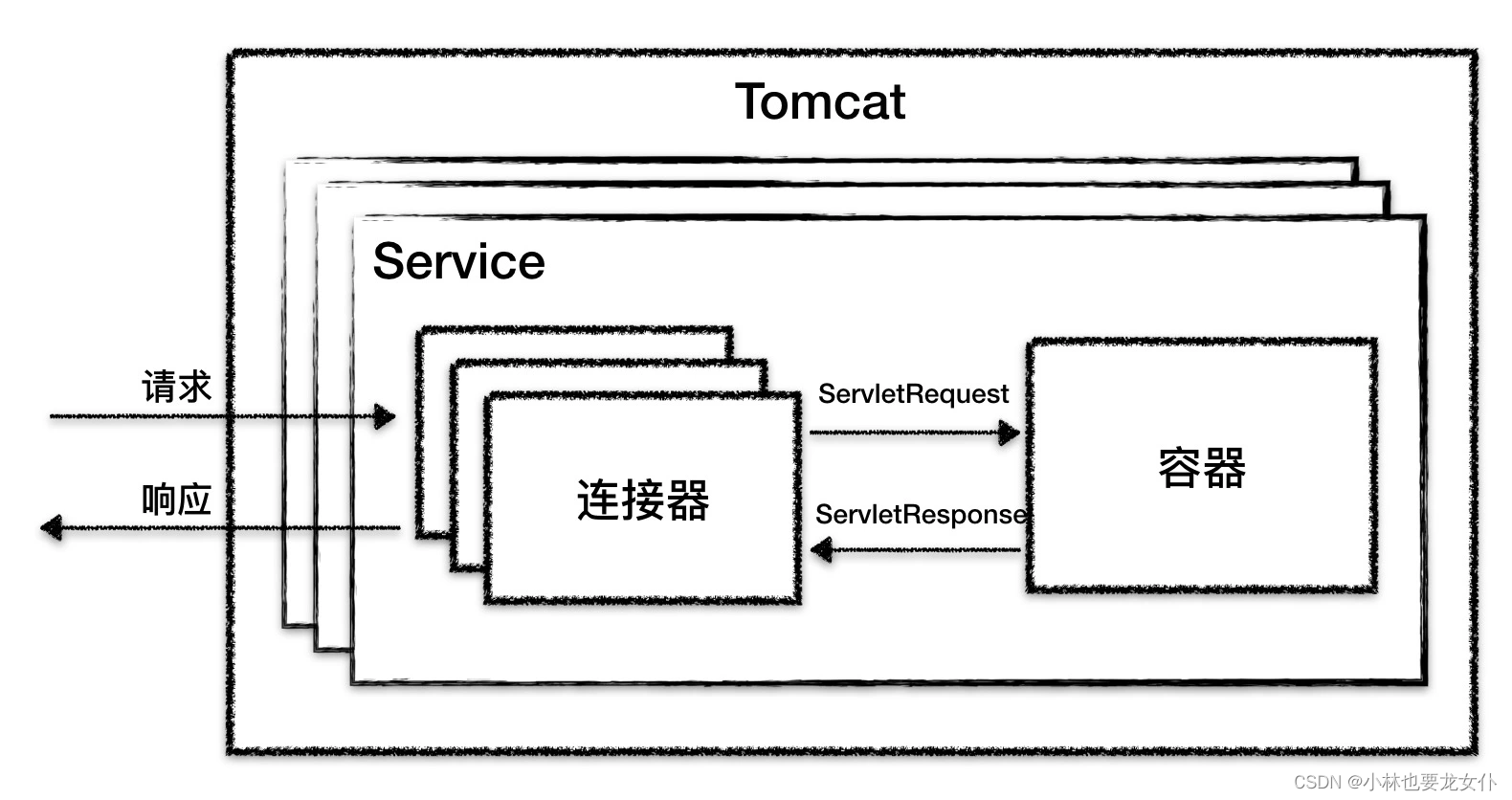
容器的层次结构
Tomcat 设计了 4 种容器,分别是Engine、Host、Context 和 Wrapper。这 4 种容器不是平级关系,而是父子关系,看下图:
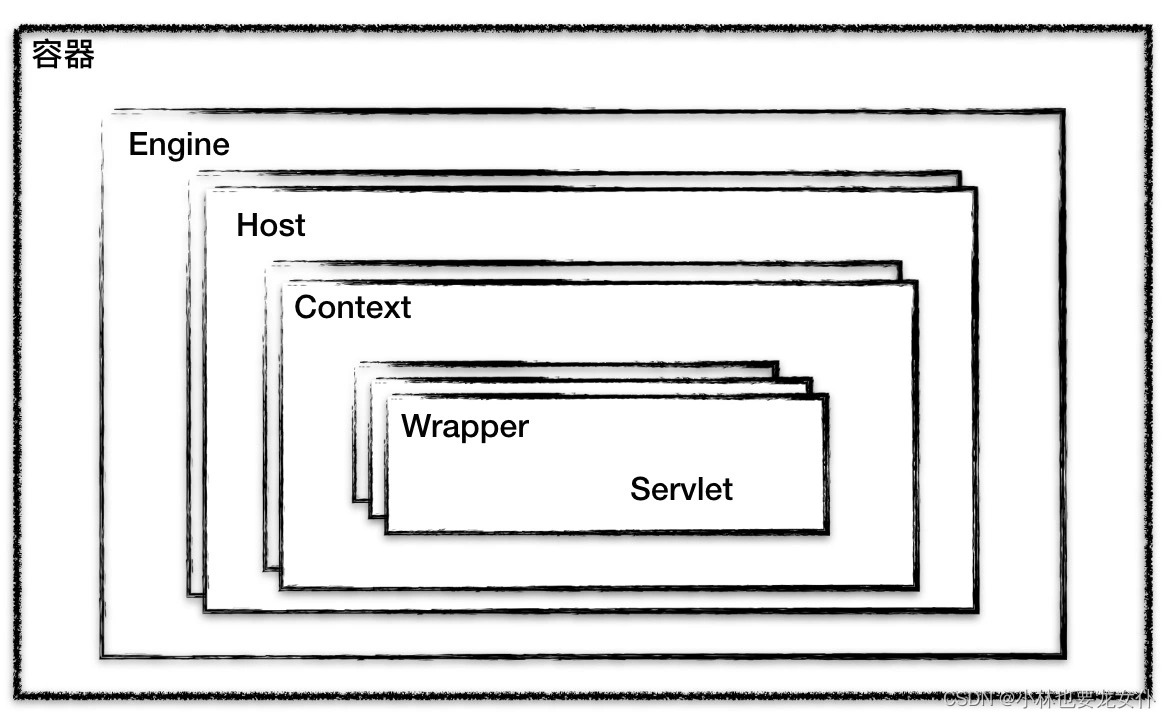
这种分层结构让 Servlet 容器具备很好的灵活性。 在这里,context 表示一个 Web 应用;Wrapper 表示一个 Servlet ,一个 Web 应用可以有多个 Serlvet; Host 表示一个虚拟主机,或者说站点,可以给 Tomcat 配置多个虚拟主机地址,而一个虚拟主机地址下可以又多个 web 应用程序;Engine 表示引擎,用来管理虚拟站点,一个 Service 最多只能有一个 Engine。
你可以通过 Tomcat 的 server.xml 配置文件来加深对 Tomcat 的理解:

那么 Tomcat 如何管理这些容器呢?你会发现这些容器具有父子关系,形成一个树形结构,没错 Tomcat 容器使用了组合模式(树枝和叶子都实现了父类接口,并在内部组合使用了接口)。具体实现方法是,所有容器组件都实现了 Container 接口,因此组合模式可以使得用户对单容器对象和组合容器对象的使用具有一致性。这里单容器对象指的是最底层的 Wrapper,组合容器对象指的是上面的 Context、Host 或者 Engine。
// Lifecycle 会之后讲
public interface Container extends Lifecycle {
public void setName(String name);
public Container getParent();
public void setParent(Container container);
public void addChild(Container child);
public void removeChild(Container child);
public Container findChild(String name);
}
请求定位 Servlet 的过程
了解容器的架构,你可能会好奇 Tomcat 是怎么确定请求是由哪个 Wrapper 容器里的 servlet 来处理的呢? 答案是, Tomcat 是用 Mapper 组件来完成这个任务的。
Mapper 这个组件你可以理解为一个多层次的 Map,它的作用就是将用户请求的 URL 定位到一个 servlet,它的工作原理是:它保存了 web 的配置信息,其实就是**容器组件和访问路径的映射关系,**比如 Host 容器里配置的域名、Context 容器里配置的 web 应用路径以及 wrapper 容器里的 servlet 映射的路径。
当一个请求来临时,Mapper 容器通过解析请求 URL 中的域名和路径,再到自己保存的 Map 里去找,就能定位到一个 Servlet。注意,一个请求 URL 最后只会定位到一个 Wrapper 容器,也就是一个 Servlet。
这样说可能比较抽象,来看一个案例:
假如有一个网购系统,有面向网站管理人员的后台管理系统,还有面向终端客户的在线购物系统。这两个系统跑在同一个 Tomcat 上,为了隔离它们的访问域名,配置了两个虚拟域名:manage.shopping.com和user.shopping.com,网站管理人员通过manage.shopping.com域名访问 Tomcat 去管理用户和商品,而用户管理和商品管理是两个单独的 Web 应用。终端客户通过user.shopping.com域名去搜索商品和下订单,搜索功能和订单管理也是两个独立的 Web 应用。
针对这样的部署,Tomcat 会创建一个 Service 组件和一个 Engine 容器组件,在 Engine 容器下创建两个 Host 子容器,在每个 Host 容器下创建两个 Context 子容器。由于一个 Web 应用通常有多个 Servlet,Tomcat 还会在每个 Context 容器里创建多个 Wrapper 子容器。每个容器都有对应的访问路径,可以看下图来理解:
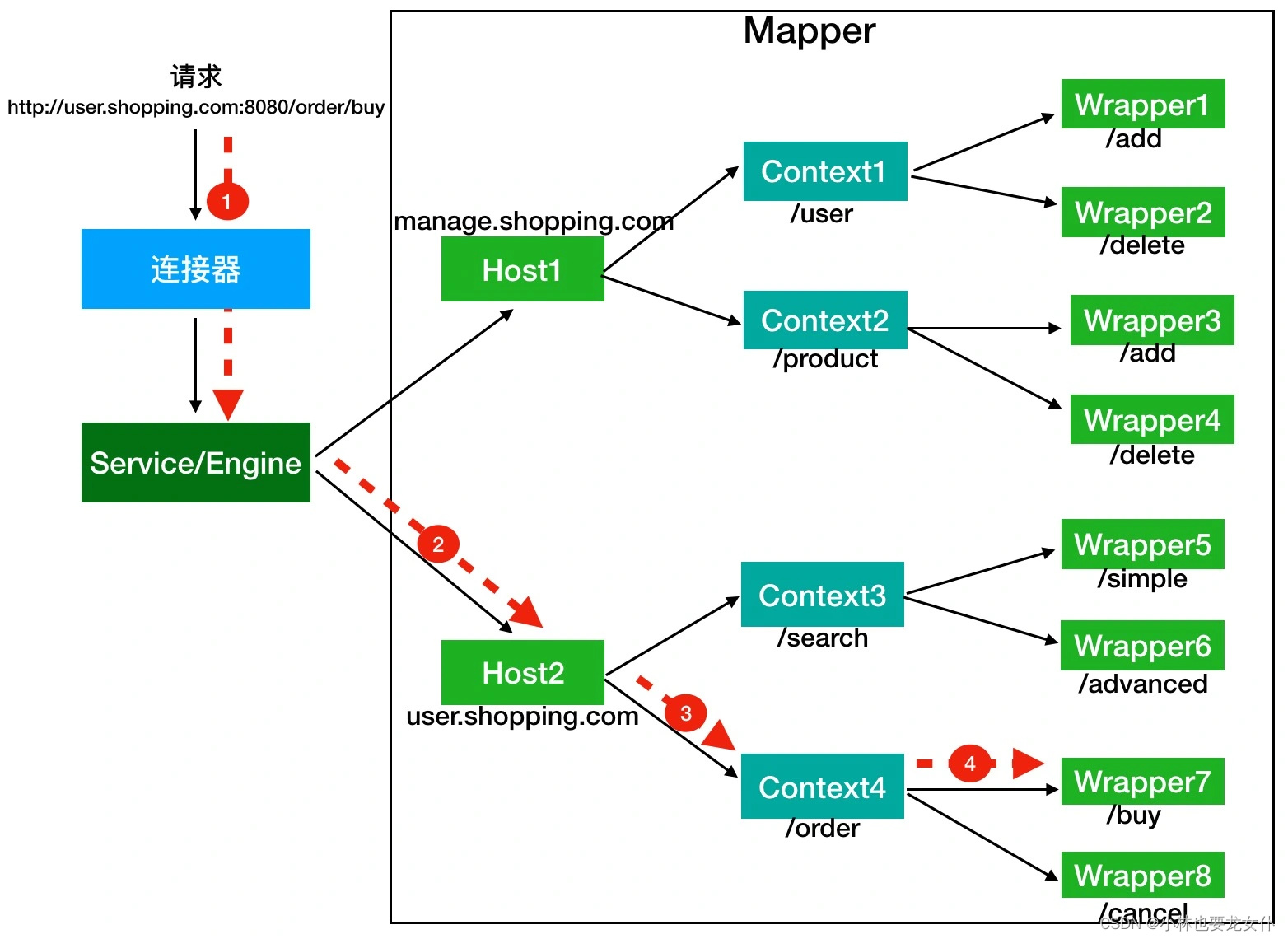
现在加入有用户访问一个 URL,比如图中的 http://user.shopping.com:8080/order/buy,Tomcat 如何将这个 URL 定位到一个 Servlet 呢?

- 首先,根据协议和端口号选定 Service 和 Engine
我们知道 Tomcat 能够监听不同的端口,比如 Tomcat 默认监听的端口是 8080,是 HTTP 连接器。上面的这个例子中访问的是 8080 端口,因此这个请求会被 HTTP 连接器,而一个连接器是属于一个 service 组件的,而 service 组件不仅仅只有多个连接器,还有容器组件,因此 Service 确定了也就意味着 Engine 也确定了。
- 然后,根据域名选定 Host
Service 和 Engine 确定后,Mapper 组件通过 URL 中的域名去查找相应的 Host 容器,比如例子中的 URL 访问的域名是user.shopping.com,因此 Mapper 会找到 Host2 这个容器。
- 之后,根据 URl 找到 Context 组件
Host 确定之后,我们需要确认访问的是那个 Web 应用程序,比如例子中访问的是/order,因此找到了 Context4 这个 Context 容器。
- 最后,根据 URL 路径找到 Wrapper(Servlet)
Context 确定之后,Mapper 再根据web.xml中配置的 Servlet 映射路径来找到具体的 Wrapper 和 Servlet。
看到这里,大家应该大致都清除 Tomcat 是如何通过一层一层的父子容器找到某个 servlet 来处理请求。需要注意的是,并不是说只有 Servlet 才会去处理请求,实际上这个查找路径上的父子容器都会对请求做一些处理。
Pipeline-Valve
Pipeline-Valve 管道是责任链设计模式编写的,责任链模式是指在一个请求处理的过程中有很多处理者依次对请求进行处理,每个处理者负责做自己相应的处理,处理完之后将再调用下一个处理者继续处理。再 Tomcat 中,最先拿到请求的是 Engine 容器,在这之后会逐级下沉,最后这个请求回传给 Wrapper 容器,Wrapper 会调用最终的 Servlet 来处理。
Valve 表示一个处理点,比如权限认证和记录日志。如果你还不太理解的话,可以来看看 Valve 和 Pipeline 接口中的关键方法。
public interface Valve {
public Valve getNext();
public void setNext(Valve valve);
public void invoke(Request request, Response response)
}
由于 Valve 是一个处理点,因此 invoke 方法就是来处理请求的。注意到 Valve 中有 getNext 和 setNext 方法,因此我们大概可以猜到有一个链表将 Valve 链起来了。请你继续看 Pipeline 接口:
public interface Pipeline extends Contained {
public void addValve(Valve valve);
public Valve getBasic();
public void setBasic(Valve valve);
public Valve getFirst();
}
没错如果说 Valve 是节点,那么 Pipeline 就是链表的维系者。Pipeline 中没有 invoke 方法,因为整个调用链的触发是 Valve 来完成的,Valve 完成自己的处理后,调用getNext.invoke来触发下一个 Valve 调用。
每一个容器都有一个 Pipeline 对象,只要触发这个 Pipeline 的第一个 Valve,这个容器里 Pipeline 中的 Valve 就都会被调用到。但是,不同容器的 Pipeline 是怎么链式触发的呢,比如 Engine 中 Pipeline 需要调用下层容器 Host 中的 Pipeline。
这是因为 Pipeline 中还有个 getBasic 方法。这个 BasicValve 处于 Valve 链表的末端,它是 Pipeline 中必不可少的一个 Valve,负责调用下层容器的 Pipeline 里的第一个 Valve。还是通过一张图来解释:
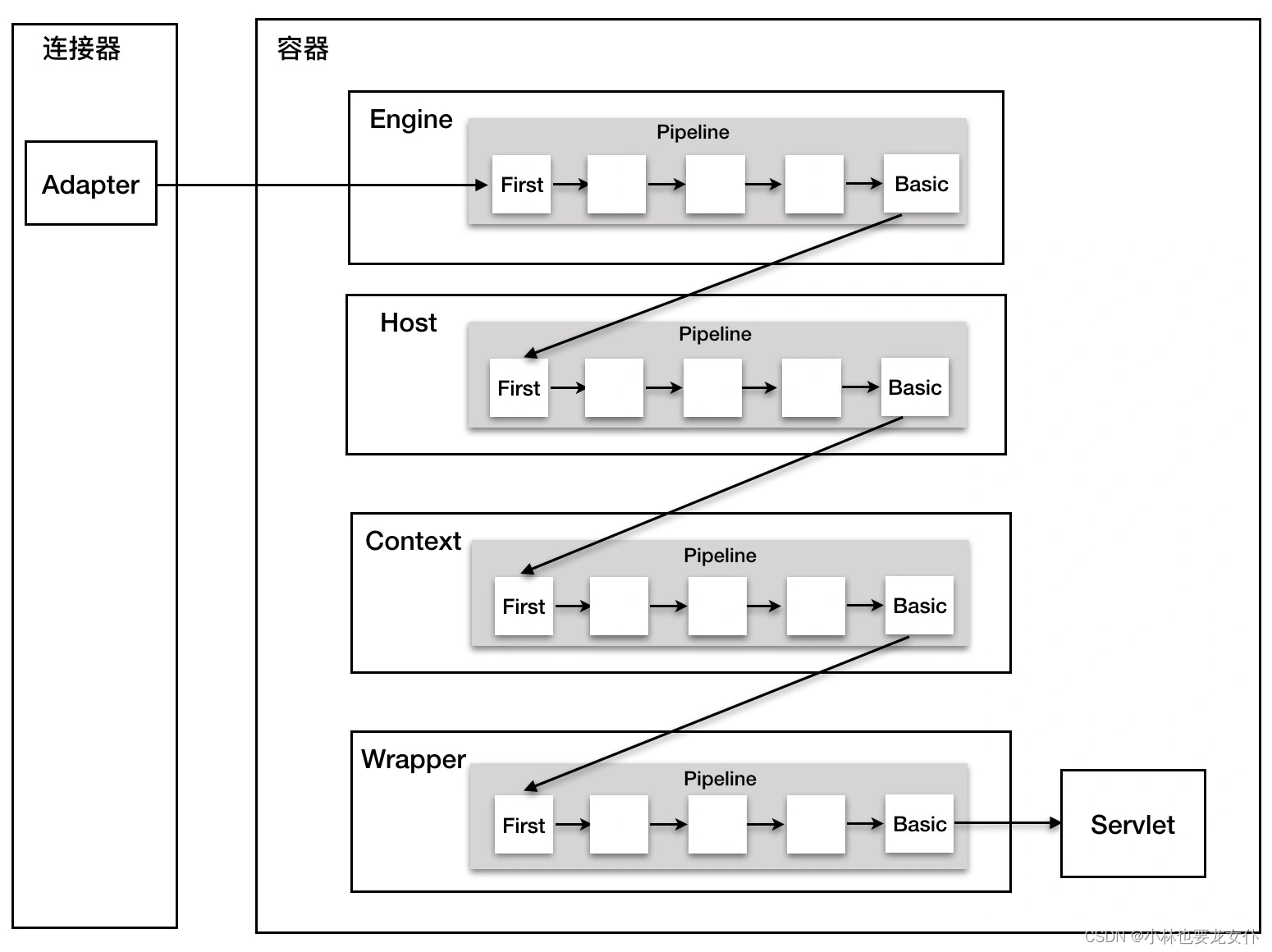
整个调用过程由连接器中的 Adapter 触发的,它会调用 Engine 的第一个 Valve:
// Calling the container
connector.getService().getContainer().getPipeline().getFirst().invoke(request, response);
Wrapper 容器的最后一个 Valve 会创建一个 Filter 链,并调用 doFilter 方法,最终会调到 Servlet 的 service 方法。
你可能会问,我们不是 filter 吗,它与 valve 有什么区别呢?
- Valve 是 Tomcat 的私有机制,与 Tomcat 的基础架构 /API 是紧耦合的。Servlet API 是公有的标准,所有的 Web 容器包括 Jetty 都支持 Filter 机制。
- 另一个重要的区别是 Valve 工作在 Web 容器级别,拦截所有应用的请求;而 Servlet Filter 工作在应用级别,只能拦截某个 Web 应用的所有请求。如果想做整个 Web 容器的拦截器,必须通过 Valve 来实现。
另外的知识
一般我们生产中通常都是一个 Tomcat 一个应用,很少会一个 Tomcat 多个应用。一个 Tomcat 多个应用一般是为了节省内存等资源,不过这种配置部署有些复杂,应用之间互相影响,加上现在硬件成本较低,这种多应用部署的例子就少见了。