原理
Lucene简介
Lucene最初由鼎鼎大名Doug Cutting开发,2000年开源,现在也是开源全文检索方案的不二选择,它的特点概述起来就是:全Java实现、开源、高性能、功能完整、易拓展,功能完整体现在对分词的支持、各种查询方式(前缀、模糊、正则等)、打分高亮、列式存储(DocValues)等等。
而且Lucene虽已发展10余年,但仍保持着一个活跃的开发度,以适应着日益增长的数据分析需求,最新的6.0版本里引入block k-d trees,全面提升了数字类型和地理位置信息的检索性能,另基于Lucene的Solr和ElasticSearch分布式检索分析系统也发展地如火如荼,ElasticSearch也在我们项目中有所应用。
全文检索技术由来已久,绝大多数都基于倒排索引来做,曾经也有过一些其他方案如文件指纹。倒排索引,顾名思义,它相反于一篇文章包含了哪些词,它从词出发,记载了这个词在哪些文档中出现过,由两部分组成——词典和倒排表。
词典结构在检索中起着重要的作用,词典结构也要多种方式实现,其中最简单的结构为排序数组,查询时使用的是二分法进行查询;最快的查询方式是哈希结构;从磁盘中查找的结构有B树,B+树。为了能够在TB级数据中实现查询的有效方式需要从时间和空间上进行衡量。下图列出了各个结构的优缺点:
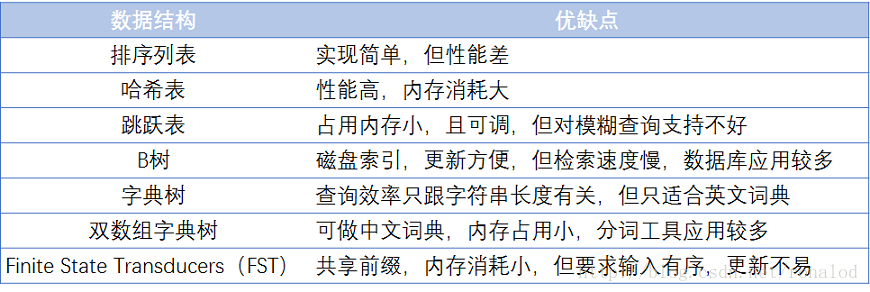
通过上图的对比,比较可用的结构有:跳跃表、B+数和FST
跳跃表
跳跃表在lucene3.0之前使用。

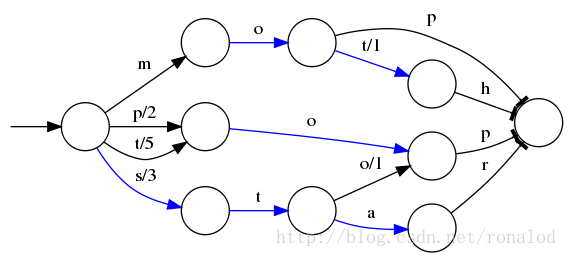
B+树
该结构在mysql的InnoDB中得到应用
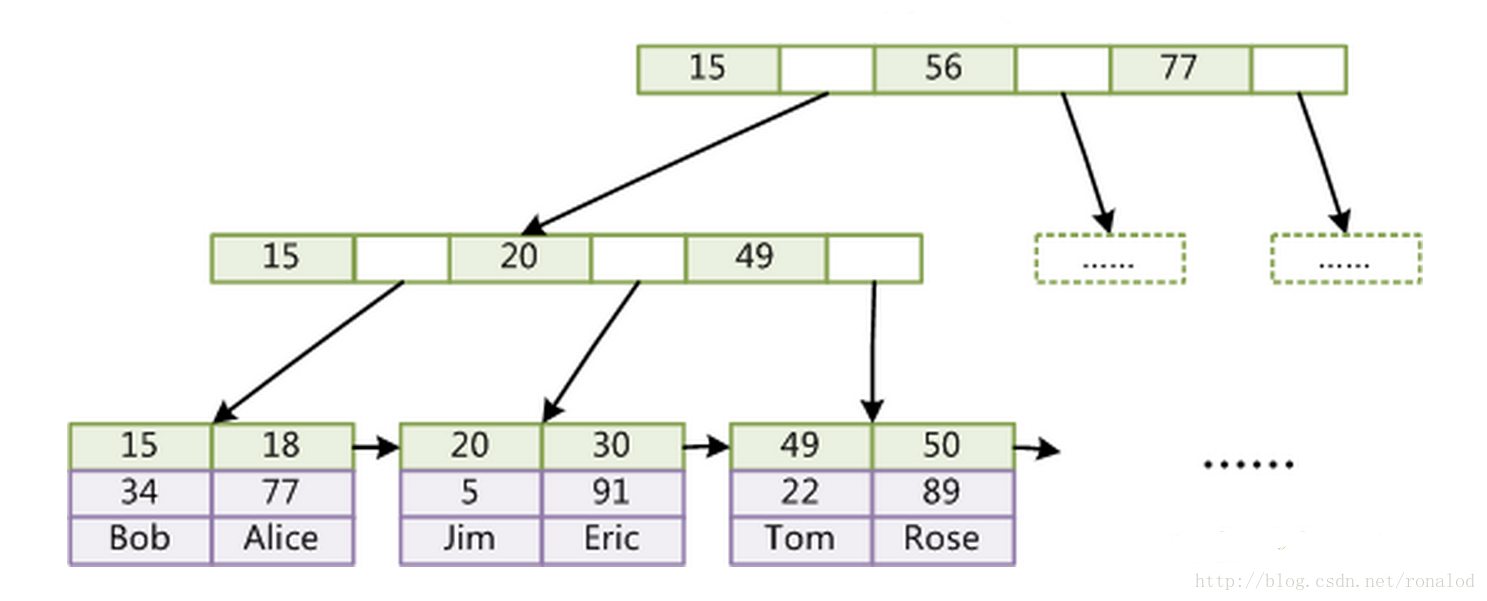
FST
Lucene现在使用的索引结构
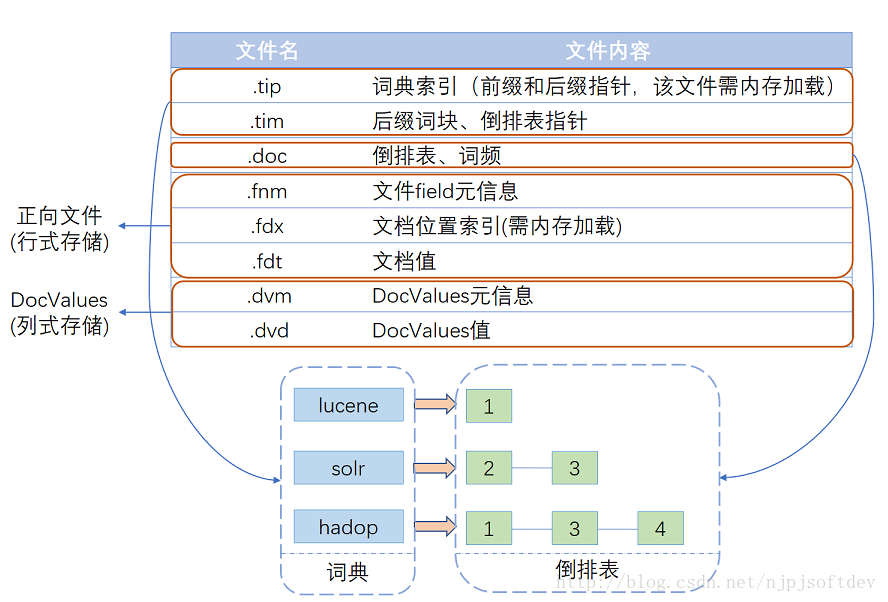
Lucene索引实现
Lucene经多年演进优化,现在的一个索引文件结构如图所示,基本可以分为三个部分:词典、倒排表、正向文件、列式存储DocValues。
索引结构
Lucene现在采用的数据结构为FST,它的特点就是:
1、词查找复杂度为O(len(str))
2、共享前缀、节省空间
3、内存存放前缀索引、磁盘存放后缀词块
这跟我们前面说到的词典结构三要素是一致的:1. 查询速度。2. 内存占用。3. 内存+磁盘结合。我们往索引库里插入四个单词abd、abe、acf、acg,看看它的索引文件内容。
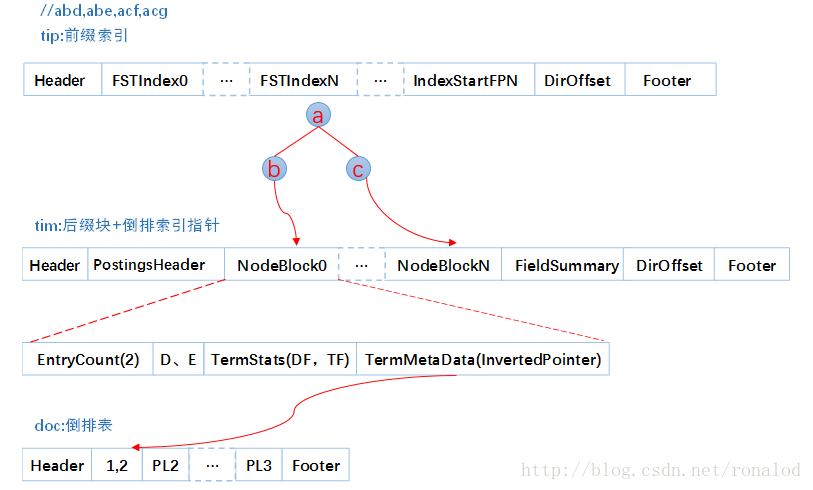
tip部分,每列一个FST索引,所以会有多个FST,每个FST存放前缀和后缀块指针,这里前缀就为a、ab、ac。tim里面存放后缀块和词的其他信息如倒排表指针、TFDF等,doc文件里就为每个单词的倒排表。
所以它的检索过程分为三个步骤:
1. 内存加载tip文件,通过FST匹配前缀找到后缀词块位置。
2. 根据词块位置,读取磁盘中tim文件中后缀块并找到后缀和相应的倒排表位置信息。
3. 根据倒排表位置去doc文件中加载倒排表。
这里就会有两个问题,第一就是前缀如何计算,第二就是后缀如何写磁盘并通过FST定位,下面将描述下Lucene构建FST过程:
已知FST要求输入有序,所以Lucene会将解析出来的文档单词预先排序,然后构建FST,我们假设输入为abd,abd,acf,acg,那么整个构建过程如下
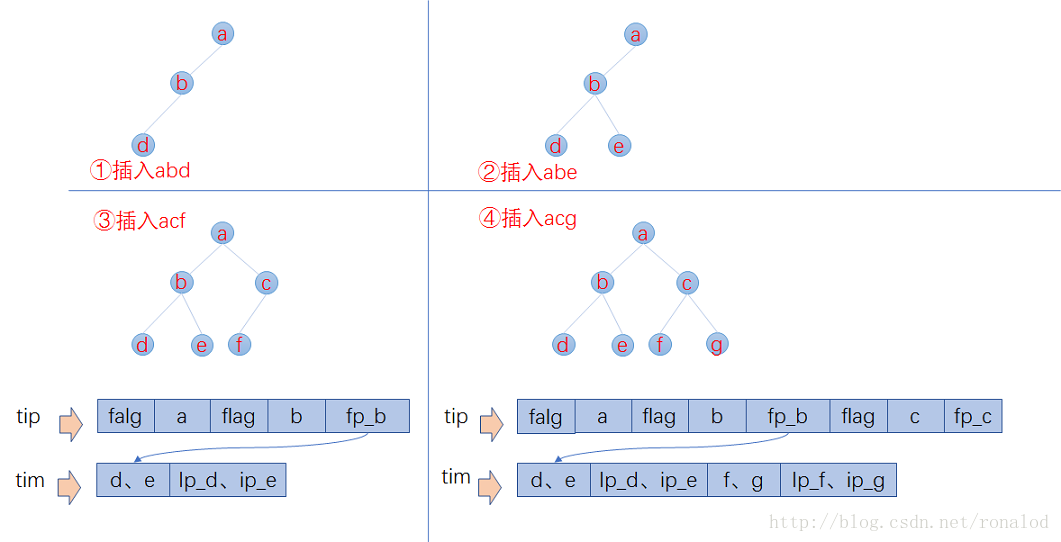
- 插入abd时,没有输出。
- 插入abe时,计算出前缀ab,但此时不知道后续还不会有其他以ab为前缀的词,所以此时无输出。
- 插入acf时,因为是有序的,知道不会再有ab前缀的词了,这时就可以写tip和tim了,tim中写入后缀词块d、e和它们的倒排表位置ip_d,ip_e,tip中写入a,b和以ab为前缀的后缀词块位置(真实情况下会写入更多信息如词频等)。
- 插入acg时,计算出和acf共享前缀ac,这时输入已经结束,所有数据写入磁盘。tim中写入后缀词块f、g和相对应的倒排表位置,tip中写入c和以ac为前缀的后缀词块位置。
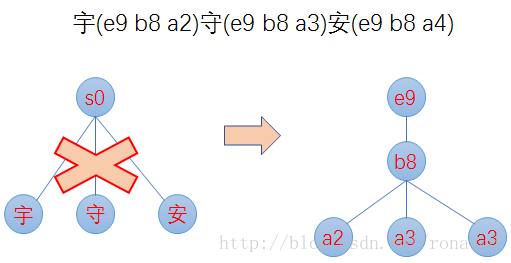
最小后缀数。Lucene对写入tip的前缀有个最小后缀数要求,默认25,这时为了进一步减少内存使用。如果按照25的后缀数,那么就不存在ab、ac前缀,将只有一个跟节点,abd、abe、acf、acg将都作为后缀存在tim文件中。我们的10g的一个索引库,索引内存消耗只占20M左右。 2. 前缀计算基于byte,而不是char,这样可以减少后缀数,防止后缀数太多,影响性能。如对宇(e9 b8 a2)、守(e9 b8 a3)、安(e9 b8 a4)这三个汉字,FST构建出来,不是只有根节点,三个汉字为后缀,而是从unicode码出发。
汉字构建FST过程:
倒排表结构
倒排表就是文档号集合,但怎么存,怎么取也有很多讲究,Lucene现使用的倒排表结构叫Frame of reference,它主要有两个特点:
1. 数据压缩,可以看下图怎么将6个数字从原先的24bytes压缩到7bytes。

2. 跳跃表加速合并,因为布尔查询时,and 和or 操作都需要合并倒排表,这时就需要快速定位相同文档号,所以利用跳跃表来进行相同文档号查找。
正向文件
正向文件指的就是原始文档,Lucene对原始文档也提供了存储功能,它存储特点就是分块+压缩,fdt文件就是存放原始文档的文件,它占了索引库90%的磁盘空间,fdx文件为索引文件,通过文档号(自增数字)快速得到文档位置,它们的文件结构如下:
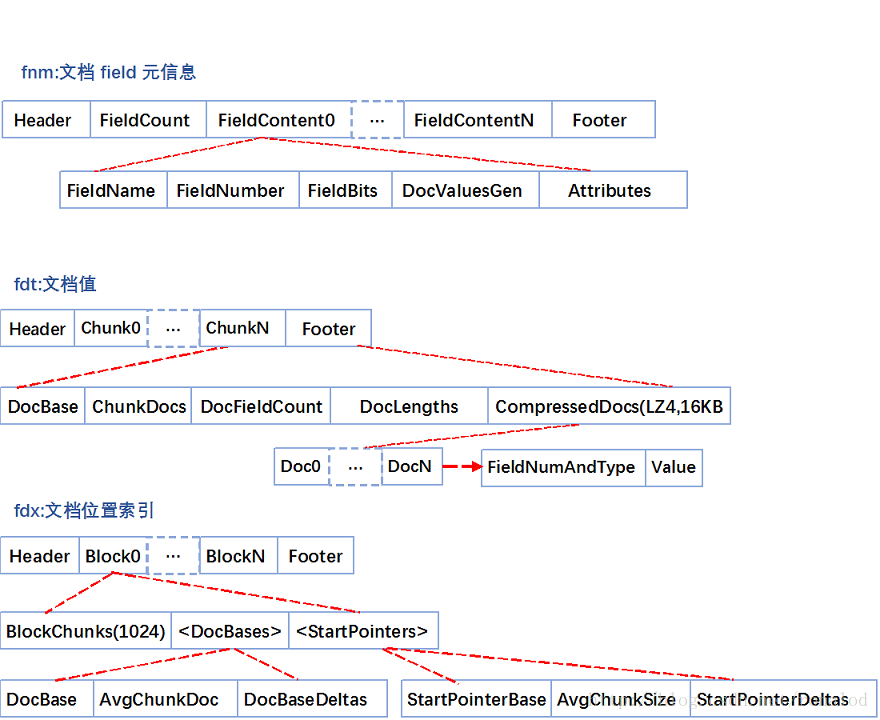
fnm中为元信息存放了各列类型、列名、存储方式等信息。
fdt为文档值,里面一个chunk就是一个块,Lucene索引文档时,先缓存文档,缓存大于16KB时,就会把文档压缩存储。一个chunk包含了该chunk起始文档、多少个文档、压缩后的文档内容。
fdx为文档号索引,倒排表存放的时文档号,通过fdx才能快速定位到文档位置即chunk位置,它的索引结构比较简单,就是跳跃表结构,首先它会把1024个chunk归为一个block,每个block记载了起始文档值,block就相当于一级跳表。
所以查找文档,就分为三步:
第一步二分查找block,定位属于哪个block。
第二步就是根据从block里根据每个chunk的起始文档号,找到属于哪个chunk和chunk位置。
第三步就是去加载fdt的chunk,找到文档。这里还有一个细节就是存放chunk起始文档值和chunk位置不是简单的数组,而是采用了平均值压缩法。所以第N个chunk的起始文档值由 DocBase + AvgChunkDocs * n + DocBaseDeltas[n]恢复而来,而第N个chunk再fdt中的位置由 StartPointerBase + AvgChunkSize * n + StartPointerDeltas[n]恢复而来。
从上面分析可以看出,lucene对原始文件的存放是行是存储,并且为了提高空间利用率,是多文档一起压缩,因此取文档时需要读入和解压额外文档,因此取文档过程非常依赖随机IO,以及lucene虽然提供了取特定列,但从存储结构可以看出,并不会减少取文档时间。
列式存储DocValues
我们知道倒排索引能够解决从词到文档的快速映射,但当我们需要对检索结果进行分类、排序、数学计算等聚合操作时需要文档号到值的快速映射,而原先不管是倒排索引还是行式存储的文档都无法满足要求。
原先4.0版本之前,Lucene实现这种需求是通过FieldCache,它的原理是通过按列逆转倒排表将(field value ->doc)映射变成(doc -> field value)映射,但这种实现方法有着两大显著问题:
1. 构建时间长。
2. 内存占用大,易OutOfMemory,且影响垃圾回收。
因此4.0版本后Lucene推出了DocValues来解决这一问题,它和FieldCache一样,都为列式存储,但它有如下优点:
1. 预先构建,写入文件。
2. 基于映射文件来做,脱离JVM堆内存,系统调度缺页。
DocValues这种实现方法只比内存FieldCache慢大概10~25%,但稳定性却得到了极大提升。
Lucene目前有五种类型的DocValues:NUMERIC、BINARY、SORTED、SORTED_SET、SORTED_NUMERIC,针对每种类型Lucene都有特定的压缩方法。
如对NUMERIC类型即数字类型,数字类型压缩方法很多,如:增量、表压缩、最大公约数,根据数据特征选取不同压缩方法。
SORTED类型即字符串类型,压缩方法就是表压缩:预先对字符串字典排序分配数字ID,存储时只需存储字符串映射表,和数字数组即可,而这数字数组又可以采用NUMERIC压缩方法再压缩,图示如下:
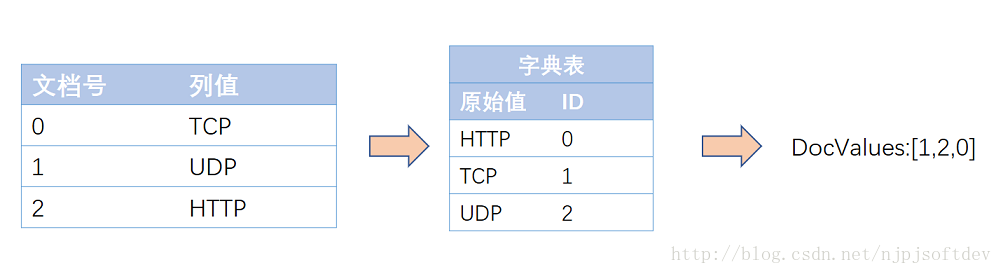
这样就将原先的字符串数组变成数字数组,一是减少了空间,文件映射更有效率,二是原先变成访问方式变成固长访问。
对DocValues的应用,ElasticSearch功能实现地更系统、更完整,即ElasticSearch的Aggregations——聚合功能,它的聚合功能分为三类:
1. Metric -> 统计
典型功能:sum、min、max、avg、cardinality、percent等
2. Bucket ->分组
典型功能:日期直方图,分组,地理位置分区
3. Pipline -> 基于聚合再聚合
典型功能:基于各分组的平均值求最大值。
实例
package solrtest;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.LinkedList;
import java.util.List;
import java.util.UUID;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.StringField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class LuceneTest {
public static void main(String[] args) throws IOException{
List<Phone> list = new LinkedList<Phone>();
for(int i=0;i<3;i++){
Phone phone = new Phone();
phone.setId(UUID.randomUUID().toString());
phone.setName("三星");
phone.setPhoneType("note"+(6+i));
phone.setPrice(""+(3000+i*1000));
list.add(phone);
}
// createIndex(list);
searchIndex("三星");
}
public static void createIndex(List<Phone> list) throws IOException{
String path = new File("src/solrtest").getAbsolutePath();
//索引文件的存储位置,该类在Lucene中用于描述索引存放的位置信息
Directory directory = FSDirectory.open(Paths.get(path));
//创建分析器
Analyzer analyzer = new StandardAnalyzer();
//创建配置器
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
/**
APPEND:总是追加,可能会导致错误,索引还会重复,导致返回多次结果
CREATE:清空重建(推荐)
CREATE_OR_APPEND【默认】:创建或追加
*/
indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
for(int i=0;i<list.size();i++){
Document document = new Document();
document.add(new StringField("id", list.get(i).getId(), Store.YES));
document.add(new StringField("name", list.get(i).getName(), Store.YES));
document.add(new StringField("phoneType", list.get(i).getPhoneType(), Store.YES));
document.add(new StringField("price", list.get(i).getPrice(), Store.YES));
indexWriter.addDocument(document);
}
indexWriter.commit();
indexWriter.close();
}
//
public static void searchIndex(String value) throws IOException{
String path = new File("src/solrtest").getAbsolutePath();
//索引文件的存储位置
Directory directory = FSDirectory.open(Paths.get(path));
//它只读取索引文档. 然后交给检索工具IndexSearcher 去完成查找. 根据传进Query检索条件进行检索查找后,
//会得到一个ScoreDoc类型的结果集, 然后读取它的Document信息, 就能获取检索结果的具体信息, 比如关键字包含在哪些内容中,
//已经这些内容文档的存放路径等等. 这样就算是完成整个检索过程了.
IndexReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSearch = new IndexSearcher(indexReader);
//对于中文查询,需要分词
Term term=new Term("name", "三星");
Query query= new TermQuery(term);
//返回得分最高的
TopDocs topdocs=indexSearch.search(query, 3);
//排名靠前的n个符合条件的查询
ScoreDoc[] scoreDocs=topdocs.scoreDocs;
for(int i=0; i < scoreDocs.length; i++) {
int doc = scoreDocs[i].doc;
Document document = indexSearch.doc(doc);
System.out.println("docid:" + scoreDocs[i].doc);
System.out.println("scors:" + scoreDocs[i].score);
System.out.println("shardIndex:" + scoreDocs[i].shardIndex);
System.out.println("id:"+document.get("id")+",name:"+document.get("name")+",price:"+document.get("price"));
}
indexReader.close();
}
}