RabbitMQ过期时间TTL
过期时间TTL表示对消息设置预期的时间,在这个时间内都可以被消费者接收获取,过了之后消息将会自动删除。RabbitMQ可以对消息和队列设置TTL。目前有俩种方法可以设置。
- 通过队列属性设置,队列中所有的消息都有相同的过期时间。
- 第二种方法是对消息进行单独设置,每条消息TTL可以不同。
如果上述两种方法同时使用,则消息过期时间以俩者之间TTL值较小的为准。消息在队列的生存时间一旦超过设置的TTL值,就成为dead message(死信),消费者将无法再收到消息。
编码实现(一)通过队列属性设置
配置类(定义交换机、队列、绑定信息)
@Configuration
public class TtlRabbitmqCfg {
public final static String EXCHANGE_NAME = "ttl-direct-exchange";
public final static String QUEUE_NAME = "ttl.direct.queue";
public final static String ROUTE_NAME = "ttl";
// 这里必须交给容器管理才会被创建出来
@Bean
public DirectExchange ttlDirectExchange() {
return new DirectExchange(EXCHANGE_NAME, true, false);
}
@Bean
public Queue ttlDirectQueue() {
Map<String, Object> queueArgs = new HashMap<>();
queueArgs.put("x-message-ttl", 5 * 1000);
return new Queue(QUEUE_NAME, true, false, false, queueArgs);
}
@Bean
public Binding ttlDirectBindding() {
return BindingBuilder.bind(ttlDirectQueue()).to(ttlDirectExchange()).with(ROUTE_NAME);
}
}
生产者发送测试
@SpringBootTest
class DemoApplicationTests {
@Autowired
RabbitTemplate rabbitTemplate;
@Test
void ttlTest_01() {
String msg = SimpleDateFormat.getDateTimeInstance().format(new Date()).concat(" - ").concat(UUID.randomUUID().toString());
rabbitTemplate.convertAndSend(TtlRabbitmqCfg.EXCHANGE_NAME, TtlRabbitmqCfg.ROUTE_NAME, msg);
System.out.println("消息发送成功!");
}
}
编码实现(二)通过消息处理器设置
配置类(定义交换机、队列、绑定信息)
@Configuration
public class TtlRabbitmqCfg {
// 这里必须交给容器管理才会被创建出来
@Bean
public DirectExchange ttlDirectExchange() {
return new DirectExchange(EXCHANGE_NAME, true, false);
}
@Bean
public Queue ttlDirectQueueMsg() {
return new Queue(QUEUE_NAME_MSG, true, false, false);
}
@Bean
public Binding ttlDirectBinddingMsg() {
return BindingBuilder.bind(ttlDirectQueueMsg()).to(ttlDirectExchange()).with(ROUTE_NAME_MSG);
}
}
生产者测试代码
@Test
void ttlTest_02_msg() {
String msg = SimpleDateFormat.getDateTimeInstance().format(new Date()).concat(" - ").concat(UUID.randomUUID().toString());
MessagePostProcessor messagePostProcessor = message -> {
message.getMessageProperties().setExpiration("5000");
message.getMessageProperties().setContentEncoding("UFT-8");
return message;
};
rabbitTemplate.convertAndSend(TtlRabbitmqCfg.EXCHANGE_NAME, TtlRabbitmqCfg.ROUTE_NAME, msg, messagePostProcessor);
System.out.println("消息发送成功!");
}
死信队列
DLX:Dead-Letter-Exchange,死信交换机。当消息在一个队列中变成死信之后,它可以被重新发送到下一个交换机中,这个交换机就是DLX。绑定DLX的队列就成为死信队列。
消息变成死信的原因:消息被拒绝、消息过期、队列达到最大长度。
DLX也是一个正常的交换机和一般的交换机没有区别,能在任何队列上被指定,实际上就是设置某一队列的属性,当这个队列中存在死信时,rabbitmq会自动的将这个消息重新发布到设置的DLX上,进而被路由到另一个队列(死信队列)。
要想使用死信队列,只需要在定义队列的时候设置参数x-dead-letter-exchange指定交换机即可。
死信队列是可靠消费的一种机制。如果在消费过程中出现异常,也可以把消息丢到死信队列处理。
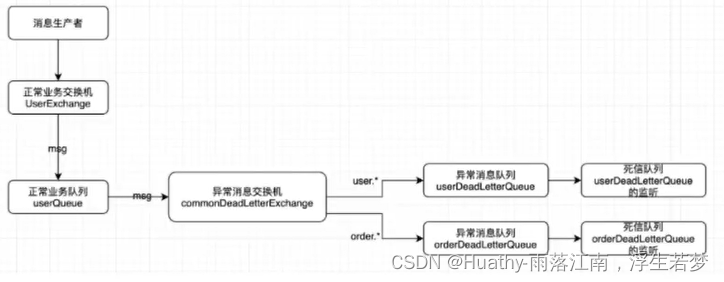
死信队列案例
编写配置(定义死信交换机、死信队列、绑定)
@Configuration
public class DeadRabbitmqCfg {
public final static String EXCHANGE_NAME = "dead-direct-exchange";
public final static String QUEUE_NAME = "dead.direct.queue";
public final static String ROUTE_NAME = "dead";
// 这里必须交给容器管理才会被创建出来
@Bean
public DirectExchange deadDirectExchange() {
return new DirectExchange(EXCHANGE_NAME, true, false);
}
@Bean
public Queue deadDirectQueue() {
return new Queue(QUEUE_NAME, true);
}
@Bean
public Binding deadDirectBindding() {
return BindingBuilder.bind(deadDirectQueue()).to(deadDirectExchange()).with(ROUTE_NAME);
}
}
修改队列配置,为其添加死信交换机和死信路由key
@Bean
public Queue ttlDirectQueue() {
Map<String, Object> queueArgs = new HashMap<>();
// 过期死信
queueArgs.put("x-message-ttl", 60 * 1000);
// 超长死信
queueArgs.put("x-max-length", 2);
// 这里修改队列参数,是不会及时变更的,需要手动删除队列。如果是线上的情况应该新建一个队列,将后续的消息发送到新的队列上
queueArgs.put("x-dead-letter-exchange", DeadRabbitmqCfg.EXCHANGE_NAME);
queueArgs.put("x-dead-letter-routing-key", DeadRabbitmqCfg.ROUTE_NAME); //由于是direct模式需要配置路由key,而fanout模式不需要
return new Queue(QUEUE_NAME, true, false, false, queueArgs);
}
内存磁盘监控
RabbitMQ内存告警
当内存使用超过配置的阈值或者磁盘空间甚于对于配置的阈值时,rabbitMQ会暂时阻塞客户端的连接,并且停止接收客户端发来的消息,从此避免服务器崩溃,客户端与服务端的心跳检测机制也会失效。
rabbitMQ内存控制
当出现内存告警的时候可以通过配置去修改调整内存大小
1. 命令方式修改(这种方式修改的重启就会失效)
rabbitmqctl set_vm_memory_high_watermark <fraction>
rabbitmqctl set_vm_memory_high_watermark absolute 5GB
fraction/value为内存阈值。默认是0.4/2G,表示当rabbitMQ超过内存阈值40%时候,就会告警,并且阻塞所有生产者连接。通过此命令修改阈值在Broker重启以后会失效。
# 进入rabbitmq容器
docker exec -it rabbit1 /bin
# 给mq设置告警大小
rabbitmqctl set_vm_memory_high_watermark absolute 50MB
2. 通过配置文件修改rabbitmq.conf
配置文件位置:etc/rabbitmq/rabbitmq.conf
而docker容器的配置文件存放在/etc/rabbitmq/conf.d/10-defaults.conf
# 默认
set_vm_memory_high_watermark.relative = 0.4
# 使用relative相对值进行设置fraction,建议取值在0.4-0.7之间。不建议超过0.7。
set_vm_memory_high_watermark.relative = 0.6
# 使用absolute的绝对值方式,单位KB、MB、GB。
set_vm_memory_high_watermark.absolute = 2GB
RabbitMQ的内存换页
在某个Broker节点及内存阻塞生产者之前,会尝试将队列中的消息换页到磁盘以释放内存空间,持久化和非持久化的消息都会写入磁盘中,其中持久化的消息本身就在磁盘中有一个副本,所以在转移的过程中持久化的消息会先从内存中清除掉。
比如有1000MB的内存,当内存使用率达到400MB,已经达到警戒阈值,但是由于配置了换页内存0.5,这个时候就会在达到极限400MB之前,将内存中的200MB转移到磁盘中。所以在转移的过程中。从而达到稳健运行。
可以通过设置vm_memory_high_watermark_paging_ratio来进行调整

vm_memory_high_watermark.relative = 0.4
vm_memory_high_watermark_paging_ratio = 0.7
# 设置小于1的值,建议0.5 - 0.7左右
为什么设置小于1,因为如果设置为1的阈值,内存已经达到极限,这时候换页的意义不是很大。
RabbitMQ磁盘预警
当磁盘剩余空间低于确定阈值时,rabbitMQ会同样的阻塞生产者,这样可以避免因为持久化的消息持续换页而耗尽磁盘空间,导致服务器崩溃。
默认情况下:磁盘预警为50MB的时候会进行预警。表示当前磁盘空间到50M的时候会阻塞生产者并停止内存消息换页到磁盘的过程。
这个阈值可以减小,但是不能完全的消除因磁盘耗尽而导致崩溃的可能性。比如在两次磁盘空间的检查空隙内,第一次检查是60MB,第二次检查可能是1MB,就会出现告警。
通过命令方式修改如下:
rabbitmqctl set_disk_free_limit <disk_limit>
rabbitmqctl set_disk_free_limit memory_limit <fraction>
# desk_limit : 固定单位 KB MB GB
# fraction: 是相对阈值,建议设置在1.0-2.0之间。(相对于内存)
通过配置文件配置如下:
disk_free_limit.relative = 3.0
disk_free_limit.absolute = 50mb
RabbitMQ高可用——集群搭建

rabbitmq自身提供集群部署功能,通过命令:
# 以下命令表示将节点1加入节点0.
rabbitmqctl -n rabbit@rmqha_node1 stop_app
# --ram 表示以内存存储方式运行,读写速度快,重启后内容会丢失。不加--ram选项,节点以磁盘存储方式运行,虽然读写速度慢,但内容可以持久化。
rabbitmqctl -n rabbit@rmqha_node1 join_cluster --ram rabbit@rmqha_node0
rabbitmqctl -n rabbit@rmqha_node1 start_app
在同一个RabbitMQ集群中节点之间没有主从之分,所有节点会同步相同的队列结构,队列内容(消息)则各自不同,不过消息会在任意节点之间传递。这样的集群知识提高了应对大量并发请求的能力,整体可用性还是很低,因为某个节点宕机后,寄存在该节点的消息不可用,而在其他节点上也没有消息备份,若是该节点无法恢复,则消息丢失。
为了解决上述问题,rabbitMQ提供镜像队列功能,通过命令:
# "^" 表示所有队列,即所有队列在各个节点上都会有备份。
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
在集群中只需要在一个节点上设置镜像队列,设置操作会同步到其他节点。
docker compose 编排
俩种方式:
- 通过搭建正常的3台rabbitMQ,编写脚本执行docker exec做相关的集群配置。
- 编写脚本,将脚本作为entrypoint的入口执行文件(该方式疑似无效)
编写服务编排配置文件rabbits.yml
version: '3.11'
services:
rabbitmq1:
container_name: rabbitmq1
hostname: rabbitmq1
image: rabbitmq:3.11-management
restart: always
environment:
- RABBITMQ_DEFAULT_USER=admin
- RABBITMQ_DEFAULT_PASS=admin123
# 注意这个RABBITMQ_ERLANG_COOKIE参数不可以少,集群主要是通过相同的cookie来共享的
- RABBITMQ_ERLANG_COOKIE=123456
ports:
- 15672:15672
- 5672:5672
rabbitmq2:
container_name: rabbitmq2
hostname: rabbitmq2
image: rabbitmq:3.11-management
restart: always
# 配置依赖
depends_on: rabbitmq1
environment:
- RABBITMQ_ERLANG_COOKIE=123456
rabbitmq3:
container_name: rabbitmq3
hostname: rabbitmq3
image: rabbitmq:3.11-management
restart: always
depends_on: rabbitmq1
environment:
- RABBITMQ_ERLANG_COOKIE=123456
通过docker-compose命令来执行配置文件
λ docker-compose -f rabbits.yml up -d
通过脚本来将mq加入集群
由于在Windows上,我们还是一条条的来执行命令:
# rabbitmq2和rabbitmq3都要执行一次
# 进入容器
λ docker exec -it rabbitmq3 /bin/bash
# 停止rabbitmq应用
root@rabbitmq3:/# rabbitmqctl stop_app
Stopping rabbit application on node rabbit@rabbitmq3 ...
# 将rabbitmq加入集群
root@rabbitmq3:/# rabbitmqctl join_cluster --ram rabbit@rabbitmq1
Clustering node rabbit@rabbitmq3 with rabbit@rabbitmq1
# 启动rabbitmq应用
root@rabbitmq3:/# rabbitmqctl start_app
Starting node rabbit@rabbitmq3 ...
root@rabbitmq3:/# exit
exit
上面的脚本是Windows的,在这提供Linux的:
echo 'restart rabbitmq2 join cluster'
docker exec rabbitmq2 /bin/bash -c 'rabbitmqctl stop_app'
docker exec rabbitmq2 /bin/bash -c 'rabbitmqctl join_cluster --ram rabbit@rabbitmq1'
docker exec rabbitmq3 /bin/bash -c 'rabbitmqctl start_app'
echo 'restart rabbitmq3 join cluster'
docker exec rabbitmq3 /bin/bash -c 'rabbitmqctl stop_app'
docker exec rabbitmq3 /bin/bash -c 'rabbitmqctl join_cluster --ram rabbit@rabbitmq1'
docker exec rabbitmq3 /bin/bash -c 'rabbitmqctl start_app'
echo 'check cluster'
docker exec rabbitmq1 /bin/bash -c 'rabbitmqctl cluster_status'
docker exec rabbitmq2 /bin/bash -c 'rabbitmqctl cluster_status'
docker exec rabbitmq3 /bin/bash -c 'rabbitmqctl cluster_status'
搭建完成,我们查看web控制页面
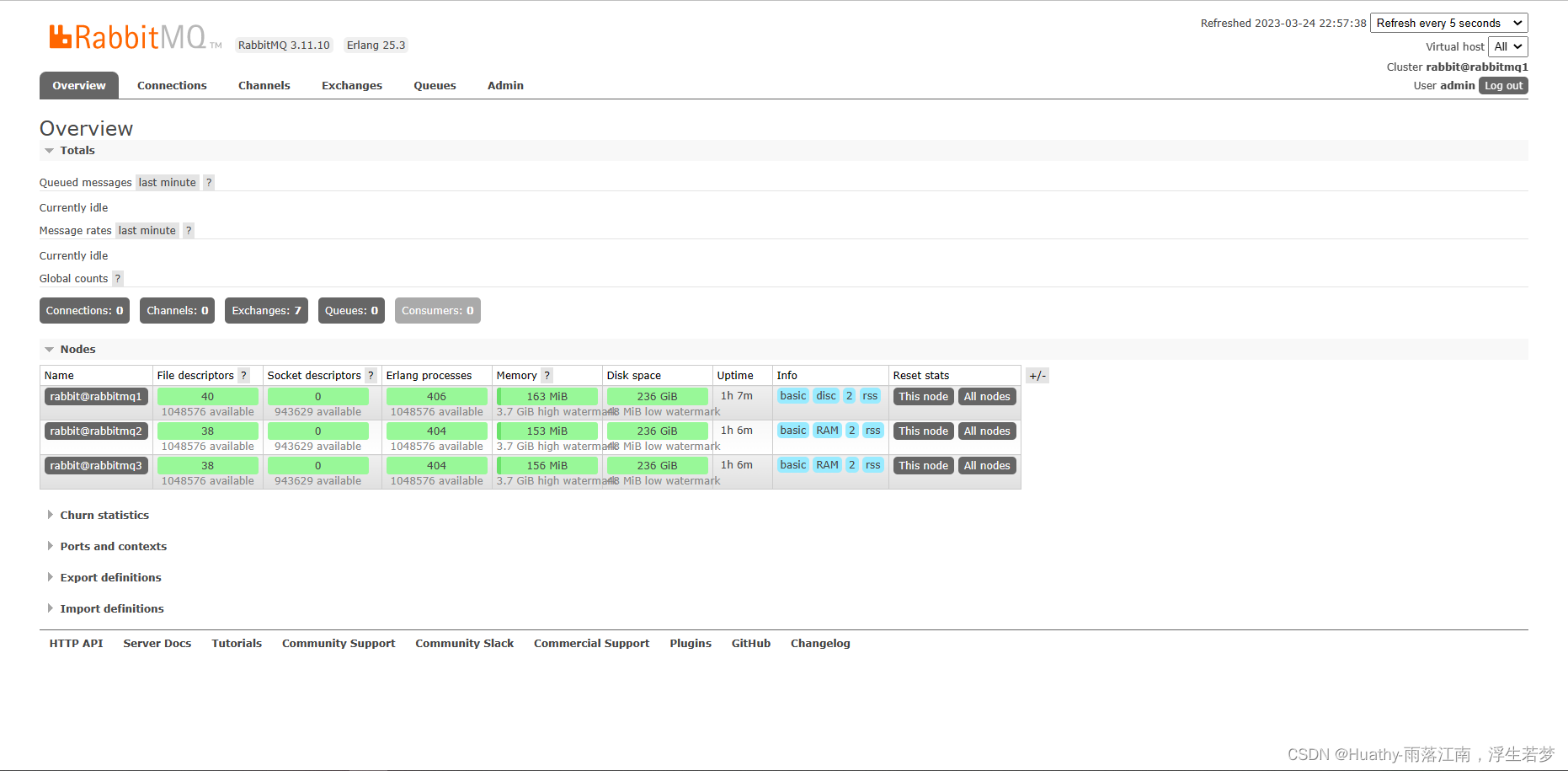
镜像集群
如果rabbitMQ集群中只有一个Broker节点,那么该节点的失效将导致整体服务的临时性不可用,并且也可能导致消息的丢失。可以将所有的消息都设置为持久化,并且将队列的durable属性设置为true,但这样仍然无法避免由于缓存导致的问题:因为消息在发送之后和被写入磁盘并执行刷盘动作之间存在短暂却会产生问题的时间间隔。通过publisherconfirm机制能够确保客户端知道哪些消息已经存入磁盘,尽管如此,一般不希望遇到单点故障导致服务不可用。
引入镜像队列(Mirror Queue)机制,可以将队列镜像到集群中的其他broker节点上,如果集群中的一个节点失效,队列将自动切换到镜像中的另一个节点上保证服务的高可用。
镜像的配置是通过policy策略的方式,以命令的方式或者UI页面设置
# 参数说明
Name: policy的名称
Pattern: queue的匹配模式(正则匹配)
priority: 可选参数,policy的优先级
Definition: 镜像定义,包括三个部分,ha-mode、ha-params、ha-sync-mode
ha_mode: 指镜像队列的模式,有效值:all/exactly/nodes
all: 表示在集群中所有的节点上
exactly: 表示在指定个数的节点上进行镜像,节点数由ha-params指定
命令方式如下:
# 任意一条节点
rabbitmqctl set_policy ha-queue-two '^queue_' '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
# 如下为所有队列同步到所有节点
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
λ docker exec -it rabbitmq1 bash
root@rabbitmq1:/# rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
Setting policy "ha-all" for pattern "^" to "{"ha-mode":"all"}" with priority "0" for vhost "/" ...
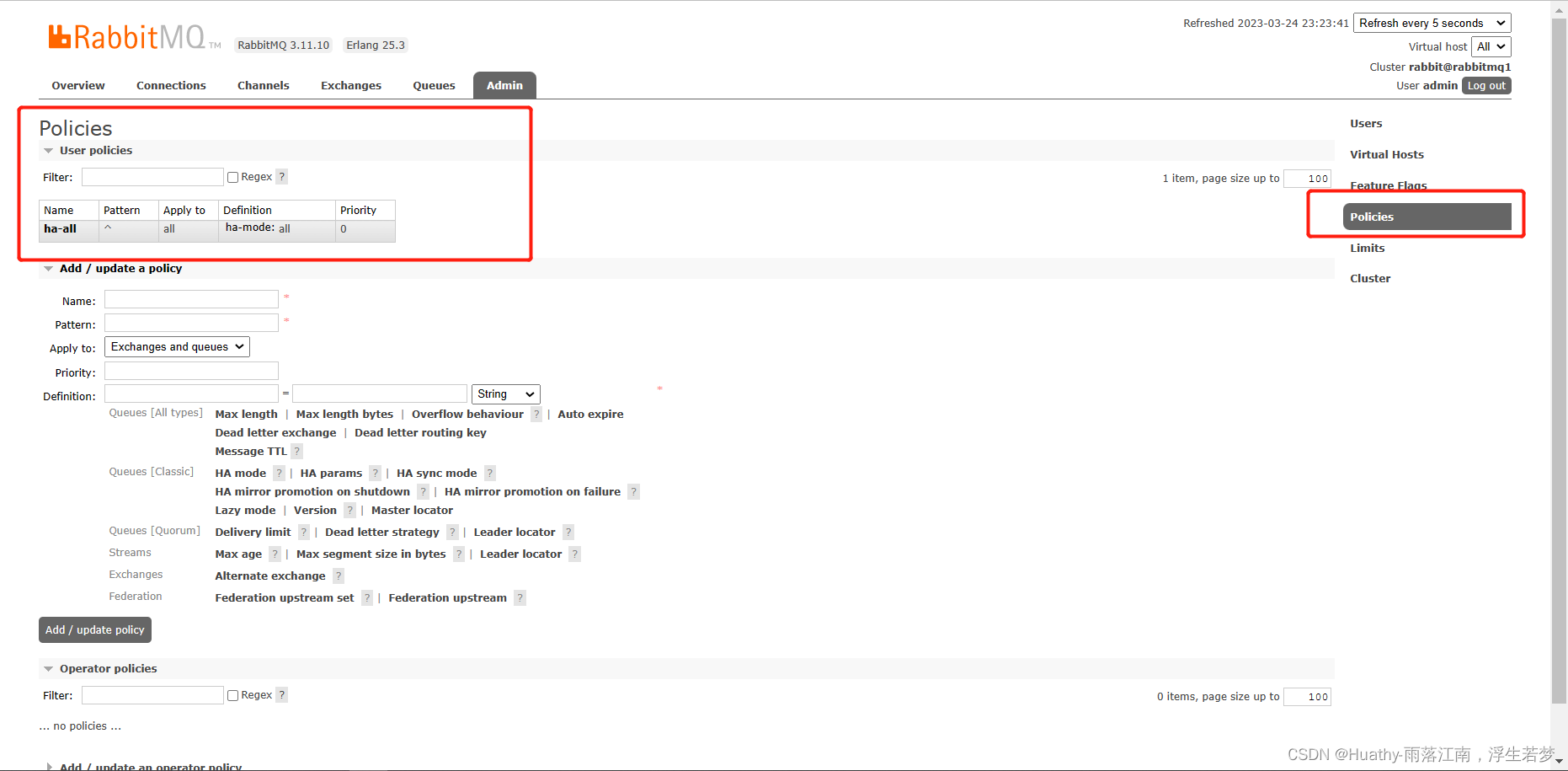
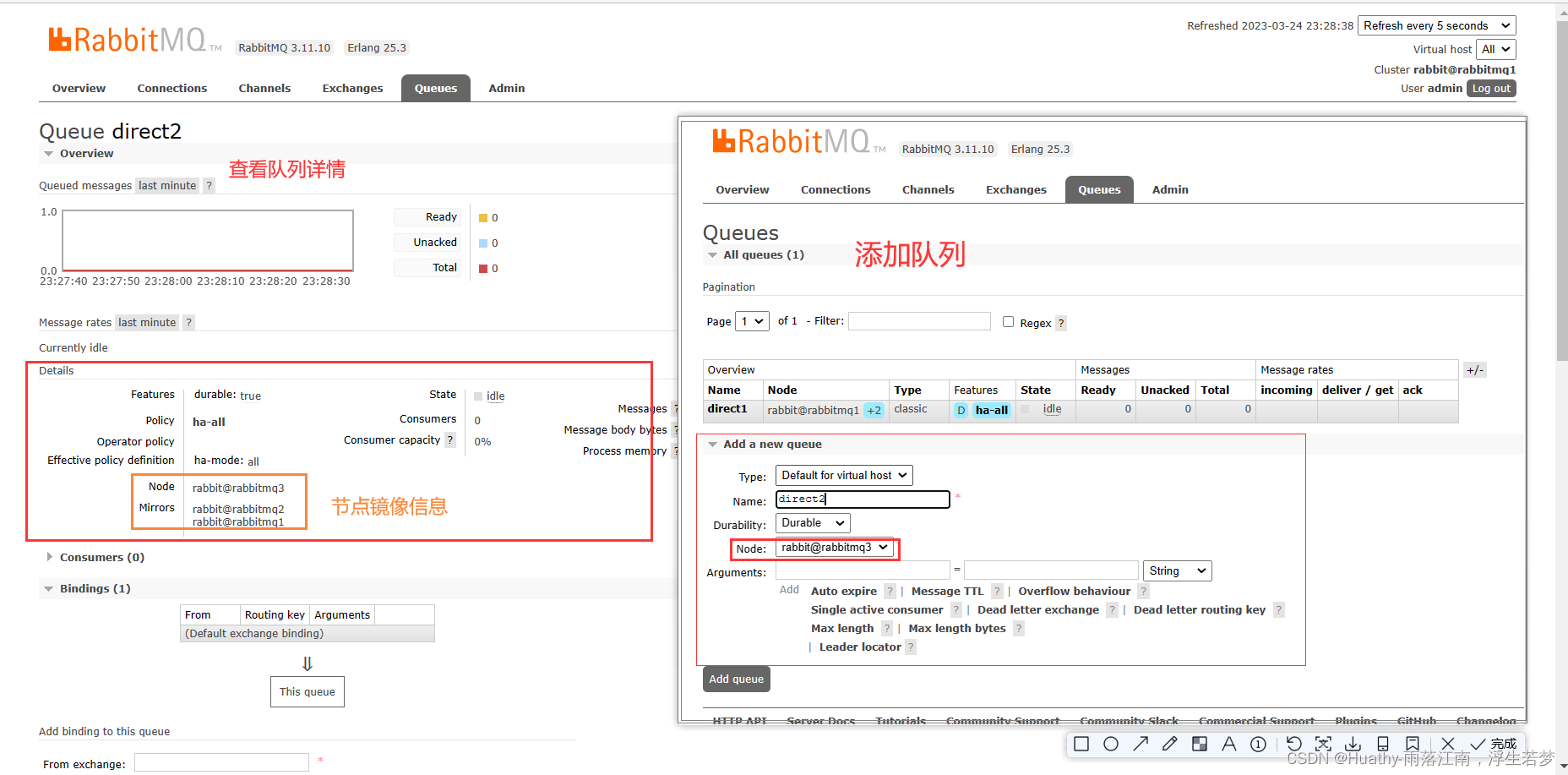
如果其中一台node宕机,则其中一台mirrors会接替node机。当原来的机器恢复后,并不会恢复。我们可以使用下面的命令来进行测试:
这里注意,如果主节点挂掉,可能会无法启动。
docker exec -it rabbitmq3 bash
rabbitmqctl stop_app