该函数的就是纯粹的读取内容出来,在源码中有这样的注释
/*
* ngx_conf_read_token() may return
*
* NGX_ERROR there is error
* NGX_OK the token terminated by ";" was found
* NGX_CONF_BLOCK_START the token terminated by "{" was found
* NGX_CONF_BLOCK_DONE the "}" was found
* NGX_CONF_FILE_DONE the configuration file is done
*/
每次在读取到上诉中的特殊符号都会返回,一开始会很迷惑,返回这玩意有啥用,那配置项那些内容怎么读到内存中来?
其实内容存储在cf->args中,也就是ngx_conf_read_token的入参结构体cf;
下面给出2张图,上面的是nginx.conf的内容,下面是第一张图的字符打印(gdb调试输出的内容),这样更方便阅读源码时比对
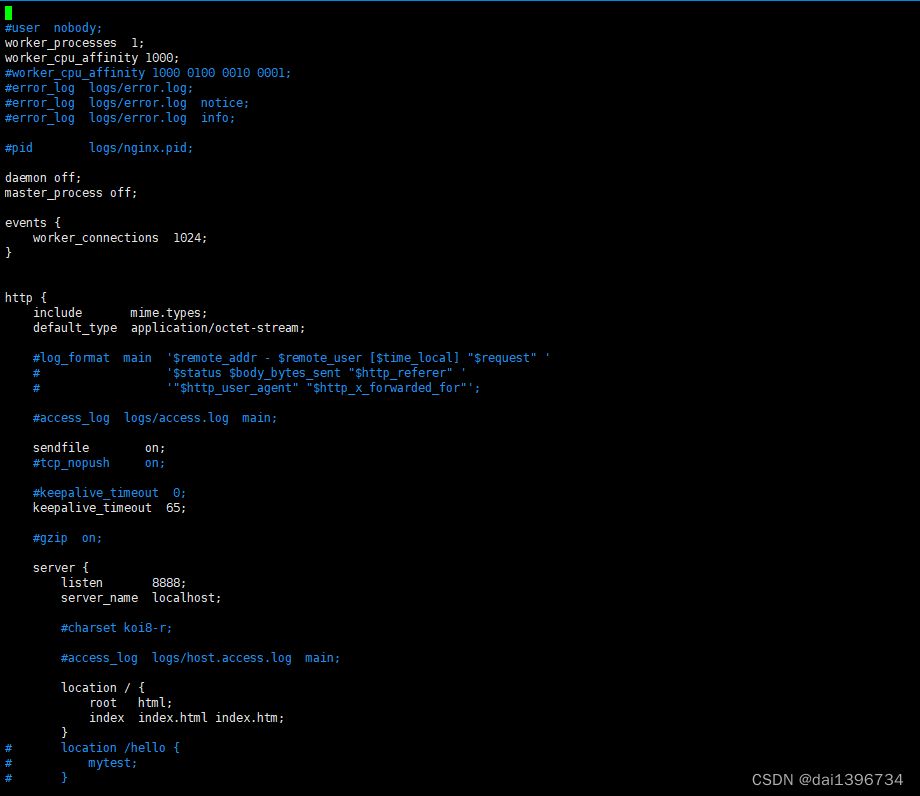
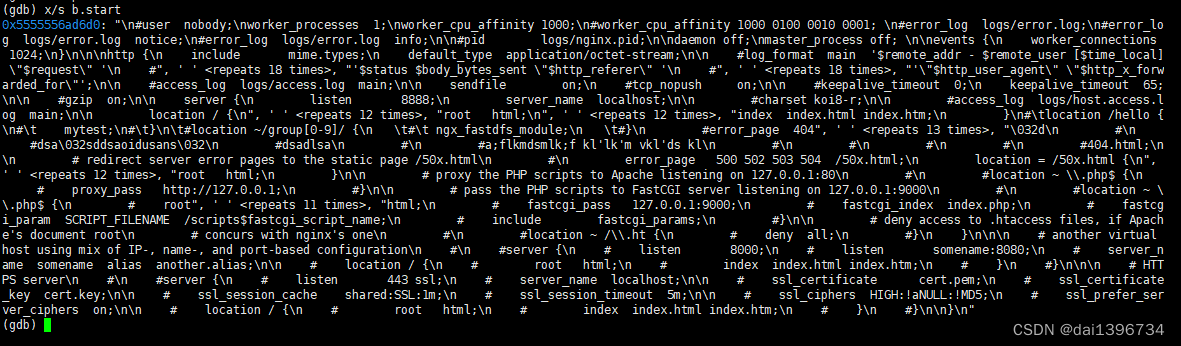
要理解该函数也不难,该函数主体是个for循环,大概分为这几步
- 遍历字符前,都会检查buffer内容是否已经遍历完,遍历完就需要从文件读新的内容进来
- 开始遍历字符,更新标志位及指针位置
- 拷贝数据到cf->args
需要特意几个指针 ngx_buf_t *b的b->pos指针、b->start和函数局部变量的start指针
- b->start在每次从文件内读取新的内容时会更新b->start
- start在是在配置项的名字或内容读完时更新
- b->pos每次遍历都会pos++
当found 为1时才会进行数据拷贝,当found 为1 且遇到";“和”{"才会返回,严谨点的话这里不应该叫数据拷贝,因为他是一个一个字符赋值的
if (ch == ';')
{
return NGX_OK;
}
if (ch == '{')
{
return NGX_CONF_BLOCK_START;
}
当遇到了";“代表一个配置项的名字和值都读取到了,可以返回去处理了,这是返回NGX_OK
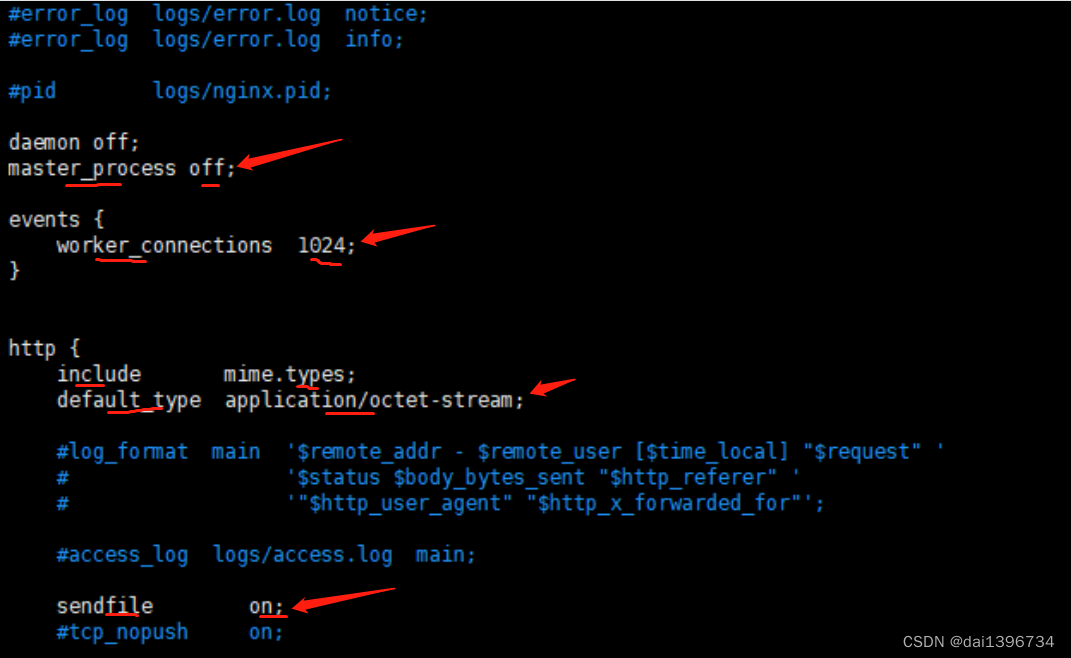
遇到了”{“,那么”{“之前的模块名字也读取到了,也可以返回去处理了,返回NGX_CONF_BLOCK_START
那么NGX_CONF_BLOCK_DONE 和 NGX_CONF_FILE_DONE的返回呢?之前说了只有found为1时才会从文件读取内容赋值到cf->args中,那么当这2个宏定义返回时,cf->args是没有内容的,那他处理什么?顾名思义,2个宏定义一个是块结束,一个是文件结束,文件结束好理解,因为整个文件内容已经处理完了,不需要额外的内容了,而块结束符确实也没有额外的更多内容处理了,因为在这个符号”}“之前一定是有符号”;“,而这个”;“会返回NGX_OK去处理内容,”}"只是纯粹的结束这个块
这是之前参考过的博客
ngx_conf_read_token
这是自己阅读源码时根据自己的理解写的一些注释,
static ngx_int_t
ngx_conf_read_token(ngx_conf_t *cf)
{
u_char *start, ch, *src, *dst;
off_t file_size;
size_t len;
ssize_t n, size;
ngx_uint_t found, need_space, last_space, sharp_comment, variable;
ngx_uint_t quoted, s_quoted, d_quoted, start_line;
ngx_str_t *word;
ngx_buf_t *b, *dump;
found = 0; //是否找到有效的内容
need_space = 0; //代表某个字段未查找完成
last_space = 1; //查找填充完成
sharp_comment = 0;//注释部分(遇到字符'#')
variable = 0;//是否是一个变量
quoted = 0; //引号 --- '//'
s_quoted = 0;//单引号
d_quoted = 0;//双引号
cf->args->nelts = 0;
b = cf->conf_file->buffer;//大小 NGX_CONF_BUFFER 4096
dump = cf->conf_file->dump;
start = b->pos;
start_line = cf->conf_file->line;
file_size = ngx_file_size(&cf->conf_file->file.info);
for ( ;; ) {
//pos 为当前遍历的位置,
//last为有内容的末尾位置
//当遍历超过时,应该从文件继续读取内容到buff
//同时更新b->pos b->last
if (b->pos >= b->last) {
if (cf->conf_file->file.offset >= file_size) {
if (cf->args->nelts > 0 || !last_space) {
if (cf->conf_file->file.fd == NGX_INVALID_FILE) {
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
"unexpected end of parameter, "
"expecting \";\"");
return NGX_ERROR;
}
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
"unexpected end of file, "
"expecting \";\" or \"}\"");
return NGX_ERROR;
}
return NGX_CONF_FILE_DONE;
}
len = b->pos - start;
if (len == NGX_CONF_BUFFER) {
cf->conf_file->line = start_line;
if (d_quoted) {
ch = '"';
} else if (s_quoted) {
ch = '\'';
} else {
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
"too long parameter \"%*s...\" started",
10, start);
return NGX_ERROR;
}
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
"too long parameter, probably "
"missing terminating \"%c\" character", ch);
return NGX_ERROR;
}
if (len) {
ngx_memmove(b->start, start, len);
}
//文件剩余大小
size = (ssize_t) (file_size - cf->conf_file->file.offset);
//buff中未使用的空间 与文件剩余大小,取小值作为size大小
if (size > b->end - (b->start + len)) {
size = b->end - (b->start + len);
}
//从文件offset个偏移字节开始读取size字节内容放入b中
n = ngx_read_file(&cf->conf_file->file, b->start + len, size,
cf->conf_file->file.offset);
if (n == NGX_ERROR) {
return NGX_ERROR;
}
if (n != size) {
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
ngx_read_file_n " returned "
"only %z bytes instead of %z",
n, size);
return NGX_ERROR;
}
//更新索引位置
b->pos = b->start + len;
b->last = b->pos + n;
start = b->start;
if (dump) {
dump->last = ngx_cpymem(dump->last, b->pos, size);
}
}
//开始读取字符
ch = *b->pos++;
//遇到换行,才将sharp_comment置为0
if (ch == LF) {
cf->conf_file->line++;
if (sharp_comment) {
sharp_comment = 0;
}
}
//带#的行,则继续遍历字符,直到换行
if (sharp_comment) {
continue;
}
if (quoted) {
quoted = 0;
continue;
}
if (need_space) {
if (ch == ' ' || ch == '\t' || ch == CR || ch == LF) {
last_space = 1;
need_space = 0;
continue;
}
if (ch == ';') {
return NGX_OK;
}
if (ch == '{') {
return NGX_CONF_BLOCK_START;
}
if (ch == ')') {
last_space = 1;
need_space = 0;
} else {
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
"unexpected \"%c\"", ch);
return NGX_ERROR;
}
}
if (last_space) {
//start记录每个字段的起始位置,方便拷贝数据到cf->args中
//到查找到有效字符时,类似worker_processes,
//当ch == 'w'时,由于指针此时已经+1了会指向'a'
//此时start 指向 'w',last_space为0,
start = b->pos - 1;
start_line = cf->conf_file->line;
if (ch == ' ' || ch == '\t' || ch == CR || ch == LF) {
continue;
}
switch (ch) {
case ';':
case '{':
//cf->args必须已经存储了元素
if (cf->args->nelts == 0) {
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
"unexpected \"%c\"", ch);
return NGX_ERROR;
}
if (ch == '{') {
return NGX_CONF_BLOCK_START;
}
return NGX_OK;
case '}':
//块结束符号前,一定会有';'符号,当有';'符号时,元素一定已经处理过了
if (cf->args->nelts != 0) {
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
"unexpected \"}\"");
return NGX_ERROR;
}
return NGX_CONF_BLOCK_DONE;
case '#':
sharp_comment = 1;
continue;
case '\\':
quoted = 1;
last_space = 0;
continue;
case '"':
start++;
d_quoted = 1;
last_space = 0;
continue;
case '\'':
start++;
s_quoted = 1;
last_space = 0;
continue;
case '$':
variable = 1;
last_space = 0;
continue;
default:
last_space = 0;
}
} else {
if (ch == '{' && variable) {
continue;
}
variable = 0;
if (ch == '\\') {
quoted = 1;
continue;
}
if (ch == '$') {
variable = 1;
continue;
}
if (d_quoted) {
if (ch == '"') {
d_quoted = 0;
need_space = 1;
found = 1;
}
} else if (s_quoted) {
if (ch == '\'') {
s_quoted = 0;
need_space = 1;
found = 1;
}
} else if (ch == ' ' || ch == '\t' || ch == CR || ch == LF
|| ch == ';' || ch == '{')
{
last_space = 1;
found = 1;
}
/**
*
* 依照上面代码的特殊字符判断一个字段的结束
* 没找到之前都会偏移b->pos指针
* 然后将根据start 及 b->pos 将数据拷贝进cf->args
*/
if (found) {
word = ngx_array_push(cf->args);
if (word == NULL) {
return NGX_ERROR;
}
word->data = ngx_pnalloc(cf->pool, b->pos - 1 - start + 1);
if (word->data == NULL) {
return NGX_ERROR;
}
for (dst = word->data, src = start, len = 0;
src < b->pos - 1;
len++)
{
//判断转义字符,有则偏移2个位置
if (*src == '\\') {
switch (src[1]) {
case '"':
case '\'':
case '\\':
src++;
break;
case 't':
*dst++ = '\t';
src += 2;
continue;
case 'r':
*dst++ = '\r';
src += 2;
continue;
case 'n':
*dst++ = '\n';
src += 2;
continue;
}
}
*dst++ = *src++;
}
*dst = '\0';
word->len = len;
if (ch == ';') {
return NGX_OK;
}
if (ch == '{') {
return NGX_CONF_BLOCK_START;
}
found = 0;
}
}
}
}