1. 代码
clear; clc;
str = 'You have to believe in yourself. That is the secret of success.';
%根据字符串str得到符号集symbols,并计算各集合元素的出现概率数组p
len = length(str);
unique_str = unique(str);
unique_len = length(unique_str);
symbols = cell(1, unique_len);
p = zeros(1, unique_len);
for i = 1:unique_len
symbols{1,i} = unique_str(i);
p(i) = numel(find(str==unique_str(i))) / len;
end
%根据符号集symbols和概率数组p计算Huffman编码词典
[dict, avglen] = huffmandict(symbols, p);
%计算平均码长
code_len = zeros(unique_len, 1);
for i = 1:unique_len
code_len(i) = numel(cell2mat(dict(i,2)));
end
max_len = max(code_len);
%打印字典表
for i = 1:unique_len
fprintf('`%s` : ', unique_str(i));
fprintf('%d ', dict{i,2});
fprintf('\n');
end
fprintf('平均码长 : %f\n', sum(p*code_len) );
fprintf('信源熵 : %f\n', sum(p.*(-log2(p))) );
fprintf('编码效率 : %f\n', 1/sum(p.*(-log2(p))) );
%计算字符串最终编码长度
enc_len = 0;
for i = 1:len
enc_len = enc_len + numel(dict{unique_str==str(i),2});
end
fprintf('编码前字符串总长度 : %d\n', numel(str));
fprintf('编码后字符串二进制总长度 : %d\n', enc_len);
fprintf('编码后字符串字节总长度(%d/8) : %d\n', enc_len, ceil(enc_len/8));
%打印最终编码
fprintf('编码结果 : ');
for i = 1:len
%fprintf('%s : ', str(i));
fprintf('%d', dict{unique_str==str(i),2});
fprintf(' ');
end
fprintf('\n');2. 输出结果
` ` : 0 0 0
`.` : 1 0 0 1 0
`T` : 1 0 0 1 1 1
`Y` : 1 0 0 1 1 0
`a` : 0 1 1 0 1
`b` : 0 1 0 0 0 0 1
`c` : 1 1 0 1
`e` : 0 0 1
`f` : 0 1 1 0 0
`h` : 1 1 0 0
`i` : 1 1 1 1
`l` : 0 1 1 1 1
`n` : 0 1 0 0 0 0 0
`o` : 1 0 0 0
`r` : 0 1 1 1 0
`s` : 1 0 1
`t` : 0 1 0 1
`u` : 1 1 1 0
`v` : 0 1 0 0 1
`y` : 0 1 0 0 0 1
平均码长 : 3.968254
信源熵 : 3.927877
编码效率 : 0.254590
编码前字符串总长度 : 63
编码后字符串二进制总长度 : 250
编码后字符串字节总长度(250/8) : 32
编码结果 : 100110 1000 1110 000 1100 01101 01001 001 000 0101 1000 000 0100001 001 01111 1111 001 01001 001 000 1111 0100000 000 010001 1000 1110 01110 101 001 01111 01100 10010 000 100111 1100 01101 0101 000 1111 101 000 0101 1100 001 000 101 001 1101 01110 001 0101 000 1000 01100 000 101 1110 1101 1101 001 101 101 10010 3. 讨论
Huffman编码存在不唯一的问题。举个例子,对于字符串google进行Huffman编码可以是如下:
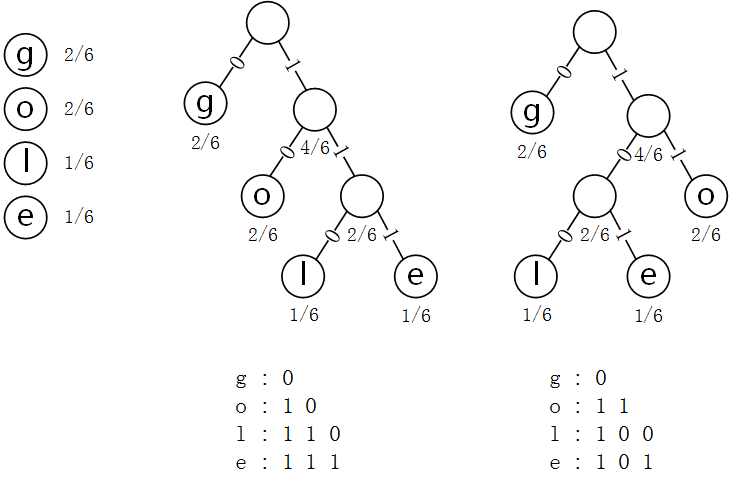
随意翻到有篇论文中探讨了这个问题,提出增加三条约束来使得Huffman编码唯一化:
1)尽量减少Huffman树的层次数
2)层次多的放在右分支
3)先出现的现用于构造