1、监控和报警
Doris可以使用Prometheus和Grafana进行监控和采集,官网下载对应版本即可:
➢ Prometheus 官网下载:https://prometheus.io/download/
➢ Grafana 官网下载:https://grafana.com/grafana/download
Doris 的监控数据通过 FE 和 BE 的 http 接口向外暴露。监控数据以 key-value 的文本形
式对外展现。每个 key 还可能有不同的 Label 加以区分。当用户搭建好 Doris 后,可以在浏览器,通过以下接口访问监控数据.
Frontend: fe_host:fe_http_port/metrics,如 http://hadoop1:8030/metrics
Backend: be_host:be_web_server_port/metrics,如 http://hadoop1:8040/metrics
整个监控架构如下图
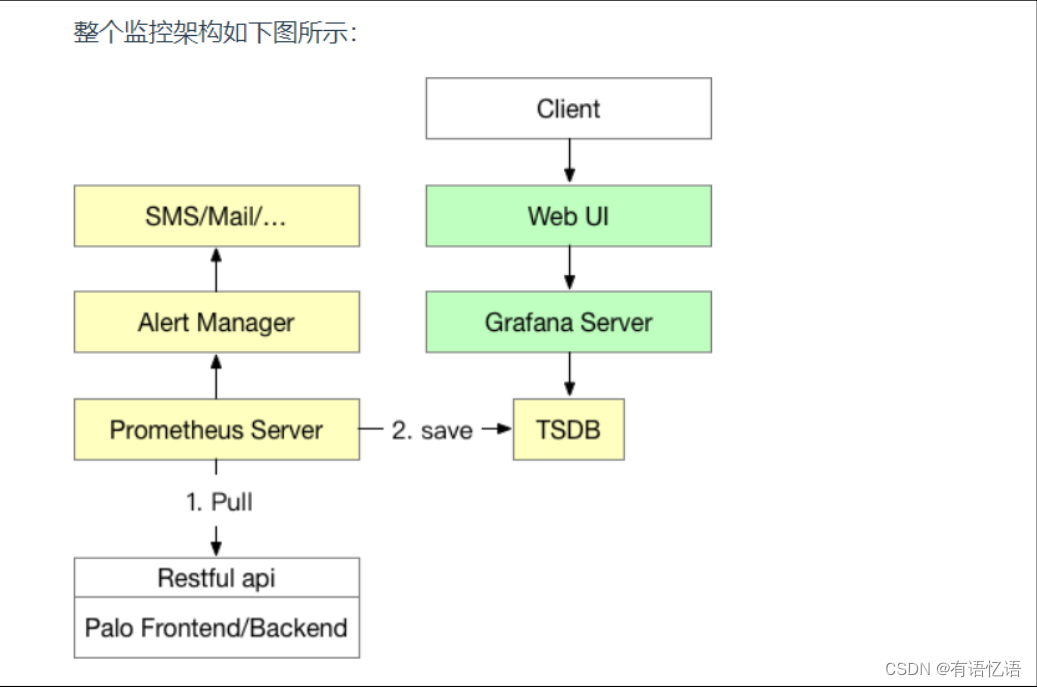
1.1、Prometheus
(1)上传 prometheus-2.26.0.linux-amd64.tar.gz,并进行解压
tar -zxvf prometheus-2.26.0.linux-amd64.tar.gz -C /opt/module
mv prometheus-2.26.0.linux-amd64 prometheus-2.26.0
(2)配置 promethues.yml
配置两个 targets 分别配置 FE 和 BE,并且定义 labels 和 groups 指定组。如果有多个集群则再加 -job_name 标签,进行相同配置
vim /opt/module/prometheus-2.26.0/prometheus.yml
scrape_configs:
- job_name: 'prometheus_doris'
static_configs:
- targets: ['hadoop1:8030','hadoop2:8030','hadoop3:8030']
labels:
group: fe
- targets: ['hadoop1:8040','hadoop2:8040','hadoop3:8040']
labels:
group: be
(3)启动 prometheus
nohup ./prometheus --web.listen-address="0.0.0.0:8181" &
该命令将后台运行 Prometheus,并指定其 web 端口为 8181。启动后,即开始采集数
据,并将数据存放在 data 目录中。
(4)通过浏览器访问 prometheus
http://hadoop1:8181
点击导航栏中,Status -> Targets,可以看到所有分组 Job 的监控主机节点。正常情况下,所有节点都应为 UP,表示数据采集正常。点击某一个 Endpoint,即可看到当前的监控数值。
(5)停止 prometheus,直接 kill -9 即可
1.2、Grafana
(1)上传 grafana-7.5.2.linux-amd64.tar.gz,并进行解压
tar -zxvf grafana-7.5.2.linux-amd64.tar.gz -C /opt/module/
mv grafana-7.5.2.linux-amd64 grafana-7.5.2
(2)配置 conf/defaults.ini
vim /opt/module/grafana-7.5.2/conf/defaults.ini
http_addr = hadoop1
http_port = 8182
(3)启动 granafa
nohup /opt/module/grafana-7.5.2/bin/grafana-server &
(4)通过浏览器访问,配置数据源 Prometheus
账号密码都是 admin
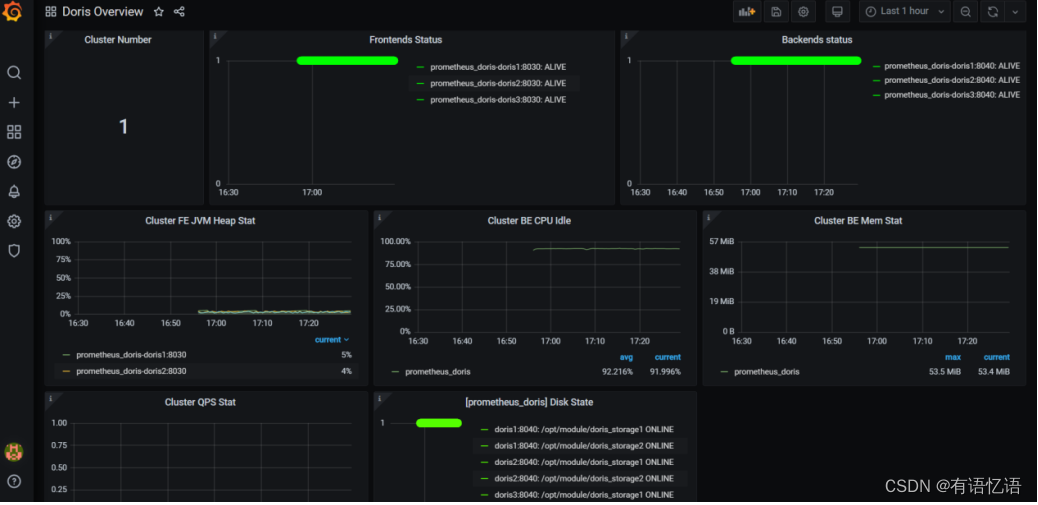
(5)添加 dashboard
模板下载地址:https://grafana.com/grafana/dashboards/9734/revisions
上传准备好的 doris-overview_rev4.json
2、优化
2.1、查看 QueryProfile
利用查询执行的统计结果,可以更好的帮助我们了解 Doris 的执行情况,并有针对性的
进行相应 Debug 与调优工作。
FE 将查询计划拆分成为 Fragment 下发到 BE 进行任务执行。BE 在执行 Fragment 时记
录了运行状态时的统计值,并将 Fragment 执行的统计信息输出到日志之中。 FE 也可以通过开关将各个 Fragment 记录的这些统计值进行搜集,并在 FE 的 Web 页面上打印结果。
2.1.1、使用方式
1)开启 profile:
set enable_profile=true;
2)执行一个查询:
SELECT t1 FROM test JOIN test2 where test.t1 = test2.t2;
3)通过 FE 的 UI 查看:
http://hadoop1:8030/ QueryProfile/
2.1.2、参数说明
1)Fragment
| AverageThreadTokens | 执行 Fragment 使用线程数目,不包含线程池的使用情况 |
|---|---|
| Buffer Pool PeakReservation | Buffer Pool 使用的内存的峰值 |
| MemoryLimit | 查询时的内存限制 |
| PeakMemoryUsage | 整个 Instance 在查询时内存使用的峰值 |
| RowsProduced | 处理列的行数 |
2)BlockMgr
| BlocksCreated BlockMgr | 创建的 Blocks 数目 |
|---|---|
| BlocksRecycled | 重用的 Blocks 数目 |
| BytesWritten | 总的落盘写数据量 |
| MaxBlockSize | 单个 Block 的大小 |
| TotalReadBlockTime | 读 Block 的总耗时 |
3)DataStreamSender
| BytesSent | 发送的总数据量 = 接受者 * 发送数据量 |
|---|---|
| IgnoreRows | 过滤的行数 |
| LocalBytesSent | 数据在 Exchange 过程中,记录本机节点的自发自收数据量 |
| OverallThroughput | 总的吞吐量 = BytesSent / 时间 |
| SerializeBatchTime | 发送数据序列化消耗的时间 |
| UncompressedRowBatchSize | 发送数据压缩前的 RowBatch 的大小 |
4)ODBC_TABLE_SINK
| NumSentRows | 写入外表的总行数 |
|---|---|
| TupleConvertTime | 发送数据序列化为 Insert 语句的耗时 |
| ResultSendTime | 通过 ODBC Driver 写入的耗时 |
5)EXCHANGE_NODE
| BytesReceived | 通过网络接收的数据量大小 |
|---|---|
| MergeGetNext | 当下层节点存在排序时,会在 EXCHANGE NODE 进行统一的归并排序,输出有序结果。该指标记录了 Merge 排序的总耗时,包含了 MergeGetNextBatch 耗时。 |
| MergeGetNextBatch | Merge 节点取数据的耗时,如果为单层 Merge 排序,则取数据的对象为网络队列。若为多层 Merge 排序取数据对象为 Child Merger。 |
| ChildMergeGetNext | 当下层的发送数据的 Sender 过多时,单线程的 Merge 会成为性能瓶颈,Doris 会启动多个 Child Merge 线程并行归并排序。记录了 Child Merge 的排序耗时 该数值是多个线程的累加值。 |
| ChildMergeGetNextBatch | Child Merge 节点从取数据的耗时,如果耗时过大,可能的瓶颈为下层的数据发送节点。 |
| DataArrivalWaitTime | 等待 Sender 发送数据的总时间 |
| FirstBatchArrivalWaitTime | 等待第一个 batch 从 Sender 获取的时间 |
| DeserializeRowBatchTimer | 反序列化网络数据的耗时 |
| SendersBlockedTotalTimer(*) | DataStreamRecv 的队列的内存被打满,Sender 端等待的耗时 |
| ConvertRowBatchTime | 接收数据转为 RowBatch 的耗时 |
| RowsReturned | 接收行的数目 |
| RowsReturnedRate | 接收行的速率 |
6)SORT_NODE
| InMemorySortTime | 内存之中的排序耗时 |
|---|---|
| InitialRunsCreated | 初始化排序的趟数(如果内存排序的话,该数为 1) |
| SortDataSize | 总的排序数据量 |
| MergeGetNext | MergeSort 从多个 sort_run 获取下一个 batch 的耗时 (仅在 |
| 落盘时计时) | |
| MergeGetNextBatch | MergeSort 提取下一个 sort_run 的 batch 的耗时 (仅在落盘时计时) |
| TotalMergesPerformed | 进行外排 merge 的次数 |
7)AGGREGATION_NODE
| PartitionsCreated | 聚合查询拆分成 Partition 的个数 |
|---|---|
| GetResultsTime | 从各个 partition 之中获取聚合结果的时间 |
| HTResizeTime | HashTable 进行 resize 消耗的时间 |
| HTResize | HashTable 进行 resize 的次数 |
| HashBuckets | HashTable 中 Buckets 的个数 |
| HashBucketsWithDuplicate | HashTable 有 DuplicateNode 的 Buckets 的个数 |
| HashCollisions | HashTable 产生哈希冲突的次数 |
| HashDuplicateNodes | HashTable 出现 Buckets 相同 DuplicateNode 的个数 |
| HashFailedProbe | HashTable Probe 操作失败的次数 |
| HashFilledBuckets | HashTable 填入数据的 Buckets 数目 |
| HashProbe | HashTable 查询的次数 |
| HashTravelLength | HashTable 查询时移动的步数 |
8)HASH_JOIN_NODE
| ExecOption | 对右孩子构造 HashTable 的方式(同步 or 异步),Join 中右孩子可能是表或子查询,左孩子同理 |
|---|---|
| BuildBuckets | HashTable 中 Buckets 的个数 |
| BuildRows | HashTable 的行数 |
| BuildTime | 构造 HashTable 的耗时 |
| LoadFactor | HashTable 的负载因子(即非空 Buckets 的数量) |
| ProbeRows | 遍历左孩子进行 Hash Probe 的行数 |
| ProbeTime | 遍历左孩子进行 Hash Probe 的耗时,不包括对左孩子 |
| RowBatch | 调用 GetNext 的耗时 |
| PushDownComputeTime | 谓词下推条件计算耗时 |
| PushDownTime | 谓词下推的总耗时,Join 时对满足要求的右孩子,转为左孩子的 in 查询 |
9)CROSS_JOIN_NODE
| ExecOption | 对右孩子构造 RowBatchList 的方式(同步 or 异步) |
|---|---|
| BuildRows | RowBatchList 的行数(即右孩子的行数) |
| BuildTime | 构造 RowBatchList 的耗时 |
| LeftChildRows | 左孩子的行数 |
| LeftChildTime | 遍历左孩子,和右孩子求笛卡尔积的耗时,不包括对左孩子 RowBatch 调用 GetNext 的耗时 |
10)UNION_NODE
| MaterializeExprsEvaluateTime | Union 两端字段类型不一致时,类型转换表达式计算及物化结果的耗时 |
|---|
11)ANALYTIC_EVAL_NODE
| EvaluationTime | 分析函数(窗口函数)计算总耗时 |
|---|---|
| GetNewBlockTime | 初始化时申请一个新的 Block 的耗时,Block 用来缓存Rows 窗口或整个分区,用于分析函数计算 |
| PinTime | 后续申请新的 Block 或将写入磁盘的 Block 重新读取回内存的耗时 |
| UnpinTime | 对暂不需要使用的 Block 或当前操作符内存压力大时,将Block 的数据刷入磁盘的耗时 |
12)OLAP_SCAN_NODE
OLAP_SCAN_NODE 节点负责具体的数据扫描任务。一个 OLAP_SCAN_NODE 会生
成一个或多个 OlapScanner 。每个 Scanner 线程负责扫描部分数据。查询中的部分或全部
谓词条件会推送给 OLAP_SCAN_NODE。这些谓词条件中一部分会继续下推给存储引擎,
以便利用存储引擎的索引进行数据过滤。另一部分会保留在 OLAP_SCAN_NODE 中,用于
过滤从存储引擎中返回的数据。
OLAP_SCAN_NODE 节点的 Profile 通常用于分析数据扫描的效率,依据调用关系分
为 OLAP_SCAN_NODE、OlapScanner、SegmentIterator 三层。
OLAP_SCAN_NODE (id=0):(Active: 1.2ms, % non-child: 0.00%)
- BytesRead: 265.00 B # 从数据文件中读取到的数据量。假设读取到了是 10
个 32 位整型,则数据量为 10 * 4B = 40 Bytes。这个数据仅表示数据在内存中全展开的大小,并不
代表实际的 IO 大小。
- NumDiskAccess: 1 # 该 ScanNode 节点涉及到的磁盘数量。
- NumScanners: 20 # 该 ScanNode 生成的 Scanner 数量。
- PeakMemoryUsage: 0.00 # 查询时内存使用的峰值,暂未使用
- RowsRead: 7 # 从存储引擎返回到 Scanner 的行数,不包括经
Scanner 过滤的行数。
- RowsReturned: 7 # 从 ScanNode 返回给上层节点的行数。
- RowsReturnedRate: 6.979K /sec # RowsReturned/ActiveTime
- TabletCount : 20 # 该 ScanNode 涉及的 Tablet 数量。
- TotalReadThroughput: 74.70 KB/sec # BytesRead 除以该节点运行的总时间(从 Open
到 Close),对于 IO 受限的查询,接近磁盘的总吞吐量。
- ScannerBatchWaitTime: 426.886us # 用于统计 transfer 线程等待 scaner 线程返
回 rowbatch 的时间。
- ScannerWorkerWaitTime: 17.745us # 用于统计 scanner thread 等待线程池中可用
工作线程的时间。
OlapScanner:
- BlockConvertTime: 8.941us # 将向量化 Block 转换为行结构的 RowBlock 的耗
时。向量化 Block 在 V1 中为 VectorizedRowBatch,V2 中为 RowBlockV2。
- BlockFetchTime: 468.974us # Rowset Reader 获取 Block 的时间。
- ReaderInitTime: 5.475ms # OlapScanner 初始化 Reader 的时间。V1 中包
括组建 MergeHeap 的时间。V2 中包括生成各级 Iterator 并读取第一组 Block 的时间。
- RowsDelFiltered: 0 # 包括根据 Tablet 中存在的 Delete 信息过滤掉
的行数,以及 unique key 模型下对被标记的删除行过滤的行数。
- RowsPushedCondFiltered: 0 # 根据传递下推的谓词过滤掉的条件,比如 Join 计
算中从 BuildTable 传递给 ProbeTable 的条件。该数值不准确,因为如果过滤效果差,就不再过滤了。
- ScanTime: 39.24us # 从 ScanNode 返回给上层节点的时间。
- ShowHintsTime_V1: 0ns # V2 中无意义。V1 中读取部分数据来进行
ScanRange 的切分。
SegmentIterator:
- BitmapIndexFilterTimer: 779ns # 利用 bitmap 索引过滤数据的耗时。
- BlockLoadTime: 415.925us # SegmentReader(V1) 或
SegmentIterator(V2) 获取 block 的时间。
- BlockSeekCount: 12 # 读取 Segment 时进行 block seek 的次数。
- BlockSeekTime: 222.556us # 读取 Segment 时进行 block seek 的耗时。
- BlocksLoad: 6 # 读取 Block 的数量
- CachedPagesNum: 30 # 仅 V2 中,当开启 PageCache 后,命中 Cache
的 Page 数量。
- CompressedBytesRead: 0.00 # V1 中,从文件中读取的解压前的数据大小。V2
中,读取到的没有命中 PageCache 的 Page 的压缩前的大小。
- DecompressorTimer: 0ns # 数据解压耗时。
- IOTimer: 0ns # 实际从操作系统读取数据的 IO 时间。
- IndexLoadTime_V1: 0ns # 仅 V1 中,读取 Index Stream 的耗时。
- NumSegmentFiltered: 0 # 在生成 Segment Iterator 时,通过列统计信息
和查询条件,完全过滤掉的 Segment 数量。
- NumSegmentTotal: 6 # 查询涉及的所有 Segment 数量。
- RawRowsRead: 7 # 存储引擎中读取的原始行数。详情见下文。
- RowsBitmapIndexFiltered: 0 # 仅 V2 中,通过 Bitmap 索引过滤掉的行数。
- RowsBloomFilterFiltered: 0 # 仅 V2 中,通过 BloomFilter 索引过滤掉的行
数。
- RowsKeyRangeFiltered: 0 # 仅 V2 中,通过 SortkeyIndex 索引过滤掉的行
数。
- RowsStatsFiltered: 0 # V2 中,通过 ZoneMap 索引过滤掉的行数,包含删
除条件。V1 中还包含通过 BloomFilter 过滤掉的行数。
- RowsConditionsFiltered: 0 # 仅 V2 中,通过各种列索引过滤掉的行数。
- RowsVectorPredFiltered: 0 # 通过向量化条件过滤操作过滤掉的行数。
- TotalPagesNum: 30 # 仅 V2 中,读取的总 Page 数量。
- UncompressedBytesRead: 0.00 # V1 中为读取的数据文件解压后的大小(如果文件
无需解压,则直接统计文件大小)。V2 中,仅统计未命中 PageCache 的 Page 解压后的大小(如果
Page 无需解压,直接统计 Page 大小)
- VectorPredEvalTime: 0ns # 向量化条件过滤操作的耗时。
- ShortPredEvalTime: 0ns # 短路谓词过滤操作的耗时。
- PredColumnReadTime: 0ns # 谓词列读取的耗时。
- LazyReadTime: 0ns # 非谓词列读取的耗时。
- OutputColumnTime: 0ns # 物化列的耗时。
13)Buffer pool
| AllocTime | 内存分配耗时 |
|---|---|
| CumulativeAllocationBytes | 累计内存分配的量 |
| CumulativeAllocations | 累计的内存分配次数 |
| PeakReservation | Reservation 的峰值 |
| PeakUnpinnedBytes | unpin 的内存数据量 |
| PeakUsedReservation | Reservation 的内存使用量 |
| ReservationLimit | BufferPool 的 Reservation 的限制量 |
2.1.3、调试方式
https://doris.apache.org/zh-CN/developer-guide/debug-tool.html
2.2、 Join Reorder
Join Reorder 功能可以通过代价模型自动帮助调整 SQL 中 Join 的顺序,以帮助获得最优的 Join 效率。 可通过会话变量开启
set enable_cost_based_join_reorder=true
2.2.1 原理
数据库一旦涉及到多表 Join,Join 的顺序对整个 Join 查询的性能是影响很大的。假设
有三张表 Join,参考下面这张图,左边是 a 表跟 b 张表先做 Join,中间结果的有 2000 行,
然后与 c 表再进行 Join 计算。
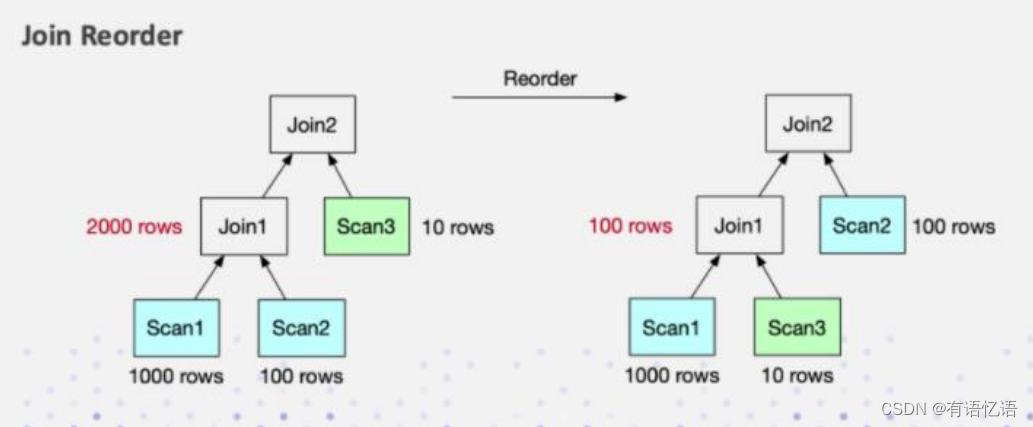
接下来看右图,把 Join 的顺序调整了一下。把 a 表先与 c 表 Join,生成的中间结果
只有 100,然后最终再与 b 表 Join 计算。最终的 Join 结果是一样的,但是它生成的中间
结果有 20 倍的差距,这就会产生一个很大的性能 Diff 了。
Doris 目前支持基于规则的 Join Reorder 算法。它的逻辑是:
(1)让大表、跟小表尽量做 Join,它生成的中间结果是尽可能小的。
(2)把有条件的 Join 表往前放,也就是说尽量让有条件的 Join 表进行过滤
(3)Hash Join 的优先级高于 Nest Loop Join,因为 Hash join 本身是比 Nest Loop Join
快很多的。
2.2.2 示例
1)查看未开启 Join Reorder 的执行计划
explain graph
select *
from example_site_visit
join example_site_visit2
on example_site_visit.user_id=example_site_visit2.user_id
join example_site_visit3
on example_site_visit.user_id=example_site_visit3.user_id;
2)开启 Join Reorder
set enable_cost_based_join_reorder=true
3)查看开启 Join Reorder 后的执行计划
explain graph
select *
from example_site_visit
join example_site_visit2
on example_site_visit.user_id=example_site_visit2.user_id
join example_site_visit3
on example_site_visit.user_id=example_site_visit3.user_id;
2.3 Join 的优化原则
(1)在做 Join 的时候,要尽量选择同类型或者简单类型的列,同类型的话就减少它的
数据 Cast,简单类型本身 Join 计算就很快。
(2)尽量选择 Key 列进行 Join, 原因前面在 Runtime Filter 的时候也介绍了,Key
列在延迟物化上能起到一个比较好的效果。
(3)大表之间的 Join ,尽量让它 Co-location ,因为大表之间的网络开销是很大的,
如果需要去做 Shuffle 的话,代价是很高的。
(4)合理的使用 Runtime Filter,它在 Join 过滤率高的场景下效果是非常显著的。但
是它并不是万灵药,而是有一定副作用的,所以需要根据具体的 SQL 的粒度做开关。
(5)涉及到多表 Join 的时候,需要去判断 Join 的合理性。尽量保证左表为大表,右
表为小表,然后 Hash Join 会优于 Nest Loop Join。必要的时可以通过 SQL Rewrite,利用
Hint 去调整 Join 的顺序。

2.4 导入导出性能优化
在提交 LOAD 作业前,先执行 set enable_profile=true 打开会话变量。然后提交导入作
业。待导入作业完成后,可以在 FE 的 web 页面的 Queris 标签中查看到导入作业的
Profile。这个 Profile 可以帮助分析导入作业的运行状态。当前只有作业成功执行后,才能
查看 Profile。
2.4.1 FE 配置
1)以下配置属于 FE 的系统配置,可以通过修改 FE 的配置文件 fe.conf 来修改配置。
| max_load_timeout_second min_load_timeout_second | 最大、最小导入超时时间,单位秒,默认最大 3 天,最小 1 秒。用户自定义的导入超时时间不可超过这个范围。该参数通用于所有的导入方式。 |
|---|---|
| desired_max_waiting_jobs | 在等待队列中的导入任务最大个数,默认为 100。当在 FE 中处于PENDING 状态(也就是等待执行的)导入个数超过该值,新的导入请求则会被拒绝。仅对异步执行的导入有效,当异步执行的导入等待个数超过默认值,则后续的创建导入请求会被拒绝。 |
| max_running_txn_num_per_db | 每个 Database 中正在运行的导入最大个数(不区分导入类型,统一计数),默认 100。如果是同步导入作业,则导入会被拒绝。如果是异步导入作业。则作业会在队列中等待。 |
2)Broker 相关的 FE 配置:
| min_bytes_per_broker_scanner | 单个 BE 处理的数据量的最小值,默认 64MB,单位 bytes |
|---|---|
| max_bytes_per_broker_scanner | 单个 BE 处理的数据量的最大值,默认 3G,单位 bytes |
| max_broker_concurrency | 作业的最大的导入并发数,默认 10 |
⚫ 本次导入并发数 = Math.min(源文件大小/最小处理量,最大并发数,当前 BE 节点个数)
⚫ 本次导入单个 BE 的处理量 = 源文件大小/本次导入的并发数
3)Stream Load 相关的 FE 配置:
| stream_load_default_timeout_second | 导入任务的超时时间(以秒为单位),默认 600 秒。也可以在 stream load 请求中设置单独的超时时间。 |
|---|
4)Export 导出相关 FE 配置
| export_checker_interval_second | 调度间隔,默认 5 秒。设置该参数需重启 FE。 |
|---|---|
| export_running_job_num_limit | 正在运行的 Export 作业数量限制。如果超过,则作业将等待并处于PENDING 状态。默认为 5,可以运行时调整。 |
| export_task_default_timeout_second | Export 作业默认超时时间。默认为 2 小时。可以运行时调整。 |
| export_tablet_num_per_task | 一个查询计划负责的最大分片数。默认为 5。 |
8.4.2 BE 配置
1)以下配置属于 BE 的系统配置,可以通过修改 BE 的配置文件 be.conf 来修改配置。
| push_write_mbytes_per_sec | BE 上单个 Tablet 的写入速度限制,默认 10,即 10MB/s。通常 BE 对单个 Tablet 的最大写入速度,根据 Schema 以及系统的不同,大约在 10-30MB/s 之间。可以适当调整这个参数来控制导入速度。 |
|---|---|
| write_buffer_size | 导入数据在 BE 上会先写入一个 memtable,memtable 达到阈值后才会写回磁盘。默认大小是 100MB。过小的阈值可能导致 BE 上存在大量的小文件。可以适当提高这个阈值减少文件数量。但过大的阈值可能导致 RPC 超时,见下面的配置说明。 |
| tablet_writer_rpc_timeout_sec | 导入过程中,发送一个 Batch(1024 行)的 RPC 超时时间。默认 600 秒。因为该 RPC 可能涉及多个 memtable 的写盘操作,所以可能会因为写盘导致 RPC 超时,可以适当调整这个超时时间来减少超时错误(如 send batch fail 错误)。同时,如果调大 write_buffer_size 配置,也需要适当调大这个参数。 |
| streaming_load_rpc_max_alive_time_sec | 在导入过程中,Doris 会为每一个 Tablet 开启一个 Writer,用于接收数据并写入。这个参数指定了 Writer 的等待超时时间。如果在这个时间内,Writer 没有收到任何数据,则 Writer 会被自动销毁。当系统处理速度较慢时,Writer 可能长时间接收不到下一批数据,导致导入报错:TabletWriter add batch with unknown id。此时可适当增大这个配置。默认为 600 秒。 |
| load_process_max_memory_limit_bytesload_process_max_memory_limit_percent | 限制了单个 Backend 上,可用于导入任务的最大内存和最大内存百分比。 |
| load_process_max_memory_limit_percent | 默认为 80,表示对Backend 总内存限制的百分比(总内存限制 mem_limit 默认为 80%,表示对物理内存的百分比)。即假设物理内存为 M,则默认导入内存限制为 M * 80% * 80%。 |
| load_process_max_memory_limit_bytes | 默认为 100GB。系统会在两个参数中取较小者,作为最终的 Backend 导入内存使用上限。 |
| label_keep_max_second | 设置导入任务记录保留时间。已经完成的( FINISHED or CANCELLED )导入任务记录会保留在 Doris 系统中一段时间,时间由此参数决定。参数默认值时间为 3 天。该参数通用与所有类型的导入任务。 |
2)Stream Load 相关 BE 配置
| streaming_load_max_mb | Stream load 的最大导入大小,默认为 10G,单位 MB。如果用户的原始文件超过这个值,则需要调大。 |
|---|
2.4.3 性能分析
导入过程中的查询超时,建议先看监控,grafana 上的数据。比如是否导入占用了过多
的 IO 或者 cpu 等,导致了相互影响,再逐步根据 pprof (8.1.3 提到的调试工具)+ 代码
分析。
2.4.4 Broker 导入大文件
由于单个导入 BE 最大的处理量为 3G,超过 3G 的待导入文件就需要通过调整Broker load 的导入参数来实现大文件的导入。
1)修改 fe.conf 中配置
根据当前 BE 的个数和原始文件的大小修改单个 BE 的最大扫描量和最大并发数。
max_broker_concurrency = BE 个数
当前导入任务单个 BE 处理的数据量 = 原始文件大小 / max_broker_concurrency
max_bytes_per_broker_scanner >= 当前导入任务单个 BE 处理的数据量
比如一个 100G 的文件,集群的 BE 个数为 10 个。
max_broker_concurrency = 10
max_bytes_per_broker_scanner >= 10G = 100G / 10
修改后,所有的 BE 会并发的处理导入任务,每个 BE 处理原始文件的一部分。
注意:上述两个 FE 中的配置均为系统配置,也就是说其修改是作用于所有的 Broker load 的任务的。
2)合理设置 timeout 时间
在创建导入的时候自定义当前导入任务的 timeout 时间
单个BE处理数据量/最慢导入速度(MB/s)>=timeout时间>=单个BE处理数据量/10M/s
比如一个 100G 的文件,集群的 BE 个数为 10 个
timeout >= 1000s = 10G / 10M/s
当计算出的 timeout 时间超过系统默认的导入最大超时时间 4 小时,不推荐将导入最
大超时时间直接改大来解决问题。最好是通过切分待导入文件并且分多次导入来解决问题。
因为单次导入超过 4 小时的话,导入失败后重试的时间成本很高。
3)评估导入最大数据量
可以通过如下公式计算出 Doris 集群期望最大导入文件数据量:
期望最大导入文件数据量 = 14400s * 10M/s * BE 个数
比如:集群的 BE 个数为 10 个
期望最大导入文件数据量 = 14400s * 10M/s * 10 = 1440000M ≈ 1440G
注意:一般环境可能达不到 10M/s 的速度,所以建议超过 500G 的文件都进行文件切分,再导入。
2.5 Bitmap 索引
用户可以通过创建 bitmap index 加速查询
1)创建索引
语法:
CREATE INDEX [IF NOT EXISTS] index_name ON table_name (column
[, ...],) [USING BITMAP] [COMMENT'balabala'];
注意: BITMAP 索引仅在单列上创建
示例:在 table1 上为 siteid 创建 bitmap 索引
CREATE INDEX table_bitmap ON table1 (siteid) USING BITMAP COMMENT
'table1_bitmap_index';
2)查看索引
语法:
SHOW INDEX[ES] FROM [db_name.]table_name [FROM database];
或者
SHOW KEY[S] FROM [db_name.]table_name [FROM database];
示例:展示 table1 索引
SHOW INDEX FROM test_db.table1;
3)删除索引
语法:
DROP INDEX [IF EXISTS] index_name ON [db_name.]table_name;
示例:
DROP INDEX IF EXISTS table_bitmap ON test_db.table1;
2.6 BloomFilter 索引
Doris的BloomFilter索引是从通过建表的时候指定,或者通过表的ALTER操作来完成。Bloom Filter 本质上是一种位图结构,用于快速的判断一个给定的值是否在一个集合中。这种判断会产生小概率的误判。即如果返回 false,则一定不在这个集合内。而如果范围 true,则有可能在这个集合内。
BloomFilter 索引也是以 Block 为粒度创建的。每个 Block 中,指定列的值作为一个集合生成一个 BloomFilter 索引条目,用于在查询是快速过滤不满足条件的数据。
1)建表时指定 BloomFilter 索引
CREATE TABLE IF NOT EXISTS sale_detail_bloom (
sale_date date NOT NULL COMMENT "销售时间",customer_id int NOT NULL COMMENT "客户编号",
saler_id int NOT NULL COMMENT "销售员",
sku_id int NOT NULL COMMENT "商品编号",
category_id int NOT NULL COMMENT "商品分类",
sale_count int NOT NULL COMMENT "销售数量",
sale_price DECIMAL(12,2) NOT NULL COMMENT "单价",
sale_amt DECIMAL(20,2) COMMENT "销售总金额"
)
Duplicate KEY(sale_date, customer_id,saler_id,sku_id,category_id)
PARTITION BY RANGE(sale_date)
(
PARTITION P_202111 VALUES [('2021-11-01'), ('2021-12-01'))
)
DISTRIBUTED BY HASH(saler_id) BUCKETS 10
PROPERTIES (
"replication_num" = "3",
"bloom_filter_columns"="saler_id,category_id",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "MONTH",
"dynamic_partition.time_zone" = "Asia/Shanghai",
"dynamic_partition.start" = "-2147483648",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "P_",
"dynamic_partition.replication_num" = "3",
"dynamic_partition.buckets" = "3"
);
2)查看 BloomFilter 索引
SHOW CREATE TABLE sale_detail_bloom
3)修改 BloomFilter 索引
ALTER TABLE test_db.sale_detail_bloom SET ("bloom_filter_columns"
= "customer_id,sku_id");
4)删除 BloomFilter 索引
ALTER TABLE test_db.sale_detail_bloom SET ("bloom_filter_columns"
= "");
8.7 合理设置分桶分区数
(1)一个表的 Tablet 总数量等于 (Partition num * Bucket num)。
(2)一个表的 Tablet 数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量。
(3)单个 Tablet 的数据量理论上没有上下界,但建议在 1G - 10G 的范围内。如果单个 Tablet 数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,且会增加 Schema Change 或者 Rollup 操作失败重试的代价(这些操作失败重试的粒度是 Tablet)。
(4)当 Tablet 的数据量原则和数量原则冲突时,建议优先考虑数据量原则。
(5)在建表时,每个分区的 Bucket 数量统一指定。但是在动态增加分区时(ADDPARTITION),可以单独指定新分区的 Bucket 数量。可以利用这个功能方便的应对数据缩小或膨胀。
(6)一个 Partition 的 Bucket 数量一旦指定,不可更改。所以在确定 Bucket 数量时,
需要预先考虑集群扩容的情况。比如当前只有 3 台 host,每台 host 有 1 块盘。如果
Bucket 的数量只设置为 3 或更小,那么后期即使再增加机器,也不能提高并发度。
(7)举一些例子:假设在有 10 台 BE,每台 BE 一块磁盘的情况下。如果一个表总大
小为 500MB,则可以考虑 4-8 个分片。5GB:8-16 个。50GB:32 个。500GB:建议分区,
每个分区大小在 50GB 左右,每个分区 16-32 个分片。5TB:建议分区,每个分区大小在
50GB 左右,每个分区 16-32 个分片。
注:表的数据量可以通过 show data 命令查看,结果除以副本数,即表的数据量。
3、数据备份及恢复
Doris 支持将当前数据以文件的形式,通过 broker 备份到远端存储系统中。之后可以
通过 恢复 命令,从远端存储系统中将数据恢复到任意 Doris 集群。通过这个功能,Doris
可以支持将数据定期的进行快照备份。也可以通过这个功能,在不同集群间进行数据迁移。
该功能需要 Doris 版本 0.8.2+
使用该功能,需要部署对应远端存储的 broker。如 BOS、HDFS 等。可以通过 SHOW
BROKER; 查看当前部署的 broker。
3.1、简要原理说明
3.1.1 备份(Backup)
备份操作是将指定表或分区的数据,直接以 Doris 存储的文件的形式,上传到远端仓库中进行存储。当用户提交 Backup 请求后,系统内部会做如下操作:
1)快照及快照上传
快照阶段会对指定的表或分区数据文件进行快照。之后,备份都是对快照进行操作。在快照之后,对表进行的更改、导入等操作都不再影响备份的结果。快照只是对当前数据文件产生一个硬链,耗时很少。快照完成后,会开始对这些快照文件进行逐一上传。快照上传由各个 Backend 并发完成。
2)元数据准备及上传
数据文件快照上传完成后,Frontend 会首先将对应元数据写成本地文件,然后通过broker 将本地元数据文件上传到远端仓库。完成最终备份作业。
3.1.2 恢复(Restore)
恢复操作需要指定一个远端仓库中已存在的备份,然后将这个备份的内容恢复到本地集群中。当用户提交 Restore 请求后,系统内部会做如下操作:
1)在本地创建对应的元数据
这一步首先会在本地集群中,创建恢复对应的表分区等结构。创建完成后,该表可见,但是不可访问。
2)本地 snapshot
这一步是将上一步创建的表做一个快照。这其实是一个空快照(因为刚创建的表是没有数据的),其目的主要是在 Backend 上产生对应的快照目录,用于之后接收从远端仓库下载的快照文件。
3)下载快照
远端仓库中的快照文件,会被下载到对应的上一步生成的快照目录中。这一步由各个Backend 并发完成。
4)生效快照
快照下载完成后,我们要将各个快照映射为当前本地表的元数据。然后重新加载这些快照,使之生效,完成最终的恢复作业。
3.1.3 最佳实践
1)备份
当前我们支持最小分区(Partition)粒度的全量备份(增量备份有可能在未来版本支持)。
如果需要对数据进行定期备份,首先需要在建表时,合理的规划表的分区及分桶,比如按时
间进行分区。然后在之后的运行过程中,按照分区粒度进行定期的数据备份。
2)数据迁移
用户可以先将数据备份到远端仓库,再通过远端仓库将数据恢复到另一个集群,完成数
据迁移。因为数据备份是通过快照的形式完成的,所以,在备份作业的快照阶段之后的新的
导入数据,是不会备份的。因此,在快照完成后,到恢复作业完成这期间,在原集群上导入
的数据,都需要在新集群上同样导入一遍。
建议在迁移完成后,对新旧两个集群并行导入一段时间。完成数据和业务正确性校验后,再将业务迁移到新的集群。
3)重点说明
(1)备份恢复相关的操作目前只允许拥有 ADMIN 权限的用户执行。
(2)一个 Database 内,只允许有一个正在执行的备份或恢复作业。
(3)备份和恢复都支持最小分区(Partition)级别的操作,当表的数据量很大时,建议
按分区分别执行,以降低失败重试的代价。
(4)因为备份恢复操作,操作的都是实际的数据文件。所以当一个表的分片过多,或
者一个分片有过多的小版本时,可能即使总数据量很小,依然需要备份或恢复很长时间。用
户可以通过 SHOW PARTITIONS FROM table_name; 和 SHOW TABLET FROM table_name;
来查看各个分区的分片数量,以及各个分片的文件版本数量,来预估作业执行时间。文件数
量对作业执行的时间影响非常大,所以建议在建表时,合理规划分区分桶,以避免过多的分
片。
(5)当通过 SHOW BACKUP 或者 SHOW RESTORE 命令查看作业状态时。有可能
会在 TaskErrMsg 一列中看到错误信息。但只要 State 列不为 CANCELLED,则说明作业
依然在继续。这些 Task 有可能会重试成功。当然,有些 Task 错误,也会直接导致作业失
败。
(6)如果恢复作业是一次覆盖操作(指定恢复数据到已经存在的表或分区中),那么
从恢复作业的 COMMIT 阶段开始,当前集群上被覆盖的数据有可能不能再被还原。此时如
果恢复作业失败或被取消,有可能造成之前的数据已损坏且无法访问。这种情况下,只能通
过再次执行恢复操作,并等待作业完成。因此,我们建议,如无必要,尽量不要使用覆盖的
方式恢复数据,除非确认当前数据已不再使用。
3.2 备份
3.2.1 创建一个远端仓库路径
CREATE REPOSITORY `hdfs_ods_dw_backup`
WITH BROKER `broker_name`
ON LOCATION "hdfs://hadoop1:8020/tmp/doris_backup"
PROPERTIES (
"username" = "",
"password" = ""
)
3.2.2 执行备份
语法:
BACKUP SNAPSHOT [db_name].{snapshot_name}
TO `repository_name`
ON (
`table_name` [PARTITION (`p1`, ...)],
...
)
PROPERTIES ("key"="value", ...);
示例:
BACKUP SNAPSHOT test_db.backup1
TO hdfs_ods_dw_backup
ON
(
table1
);
3.2.3 查看备份任务
SHOW BACKUP [FROM db_name]
3.2.4 查看远端仓库镜像
语法:
SHOW SNAPSHOT ON `repo_name`
[WHERE SNAPSHOT = "snapshot" [AND TIMESTAMP =
"backup_timestamp"]];
示例一:查看仓库 hdfs_ods_dw_backup 中已有的备份:
SHOW SNAPSHOT ON hdfs_ods_dw_backup;
示例二:仅查看仓库 hdfs_ods_dw_backup 中名称为 backup1 的备份:
SHOW SNAPSHOT ON hdfs_ods_dw_backup WHERE SNAPSHOT = "backup1";
示例三:查看仓库 hdfs_ods_dw_backup 中名称为 backup1 的备份,时间版本为 “2021-
05-05-15-34-26” 的详细信息:
SHOW SNAPSHOT ON hdfs_ods_dw_backup
WHERE SNAPSHOT = "backup1" AND TIMESTAMP = "2021-05-05-15-34-
26";
9.2.5 取消备份
取消一个正在执行的备份作业语法:
CANCEL BACKUP FROM db_name;
示例:取消 test_db 下的 BACKUP 任务
CANCEL BACKUP FROM test_db;
3.3 恢复
将之前通过 BACKUP 命令备份的数据,恢复到指定数据库下。该命令为异步操作。提
交成功后,需通过 SHOW RESTORE 命令查看进度。
⚫ 仅支持恢复 OLAP 类型的表
⚫ 支持一次恢复多张表,这个需要和你对应的备份里的表一致
3.3.1 使用语法
RESTORE SNAPSHOT [db_name].{snapshot_name}
FROM `repository_name`
ON (
`table_name` [PARTITION (`p1`, ...)] [AS `tbl_alias`],
...
)
PROPERTIES ("key"="value", ...);
说明:
(1)同一数据库下只能有一个正在执行的 BACKUP 或 RESTORE 任务。
(2)ON 子句中标识需要恢复的表和分区。如果不指定分区,则默认恢复该表的所有分区。所指定的表和分区必须已存在于仓库备份中
(3)可以通过 AS 语句将仓库中备份的表名恢复为新的表。但新表名不能已存在于数据库中。分区名称不能修改。
(4)可以将仓库中备份的表恢复替换数据库中已有的同名表,但须保证两张表的表结构完全一致。表结构包括:表名、列、分区、Rollup 等等。
(5)可以指定恢复表的部分分区,系统会检查分区 Range 或者 List 是否能够匹配。
(6)PROPERTIES 目前支持以下属性:
“backup_timestamp” = “2018-05-04-16-45-08”:指定了恢复对应备份的哪个时间版本,必填。该信息可以通过 SHOW SNAPSHOT ON repo; 语句获得。 “replication_num” = “3”:指定恢复的表或分区的副本数。默认为 3。若恢复已存在的表或分区,则副本数必须和已存在表或分区的副本数相同。同时,必须有足够的host 容纳多个副本。
“timeout” = “3600”:任务超时时间,默认为一天。单位秒。
“meta_version” = 40:使用指定的 meta_version 来读取之前备份的元数据。注意,
该参数作为临时方案,仅用于恢复老版本 Doris 备份的数据。最新版本的备份数据
中已经包含 meta version,无需再指定。
3.3.2 使用示例
1)示例一
从 example_repo 中恢复备份 snapshot_1 中的表 backup_tbl 到数据库 example_db1,
时间版本为 “2021-05-04-16-45-08”。恢复为 1 个副本:
RESTORE SNAPSHOT example_db1.`snapshot_1`
FROM `example_repo`
ON ( `backup_tbl` )
PROPERTIES
(
"backup_timestamp"="2021-05-04-16-45-08",
"replication_num" = "1"
);
2)示例二
从 example_repo 中恢复备份 snapshot_2 中的表 backup_tbl 的分区 p1,p2,以及表
backup_tbl2 到数据库 example_db1,并重命名为 new_tbl,时间版本为 “2021-05-04-17-11-
01”。默认恢复为 3 个副本:
RESTORE SNAPSHOT example_db1.`snapshot_2`
FROM `example_repo`
ON
(
`backup_tbl` PARTITION (`p1`, `p2`),
`backup_tbl2` AS `new_tbl`
)
PROPERTIES
(
"backup_timestamp"="2021-05-04-17-11-01"
);
3)演示
RESTORE SNAPSHOT test_db.backup1
FROM `hdfs_ods_dw_backup`
ON
(
table1 AS table_restore
)
PROPERTIES
(
"backup_timestamp"="2022-04-01-16-45-19"
);
3.3.3 查看恢复任务
可以通过下面的语句查看数据恢复的情况
SHOW RESTORE [FROM db_name]
3.3.4 取消恢复
下面的语句用于取消一个正在执行数据恢复的作业:
CANCEL RESTORE FROM db_name;
当取消处于 COMMIT 或之后阶段的恢复左右时,可能导致被恢复的表无法访问。此时
只能通过再次执行恢复作业进行数据恢复
示例:取消 example_db 下的 RESTORE 任务。
CANCEL RESTORE FROM example_db;
3.4 删除远端仓库
该语句用于删除一个已创建的仓库。仅 root 或 superuser 用户可以删除仓库。这里的
用户是指 Doris 的用户 语法:
DROP REPOSITORY `repo_name`;
说明:
删除仓库,仅仅是删除该仓库在 Doris 中的映射,不会删除实际的仓库数据。删除后,
可以再次通过指定相同的 broker 和 LOCATION 映射到该仓库。
示例:删除名为 hdfs_ods_dw_backup 的仓库:
DROP REPOSITORY `hdfs_ods_dw_backup`;