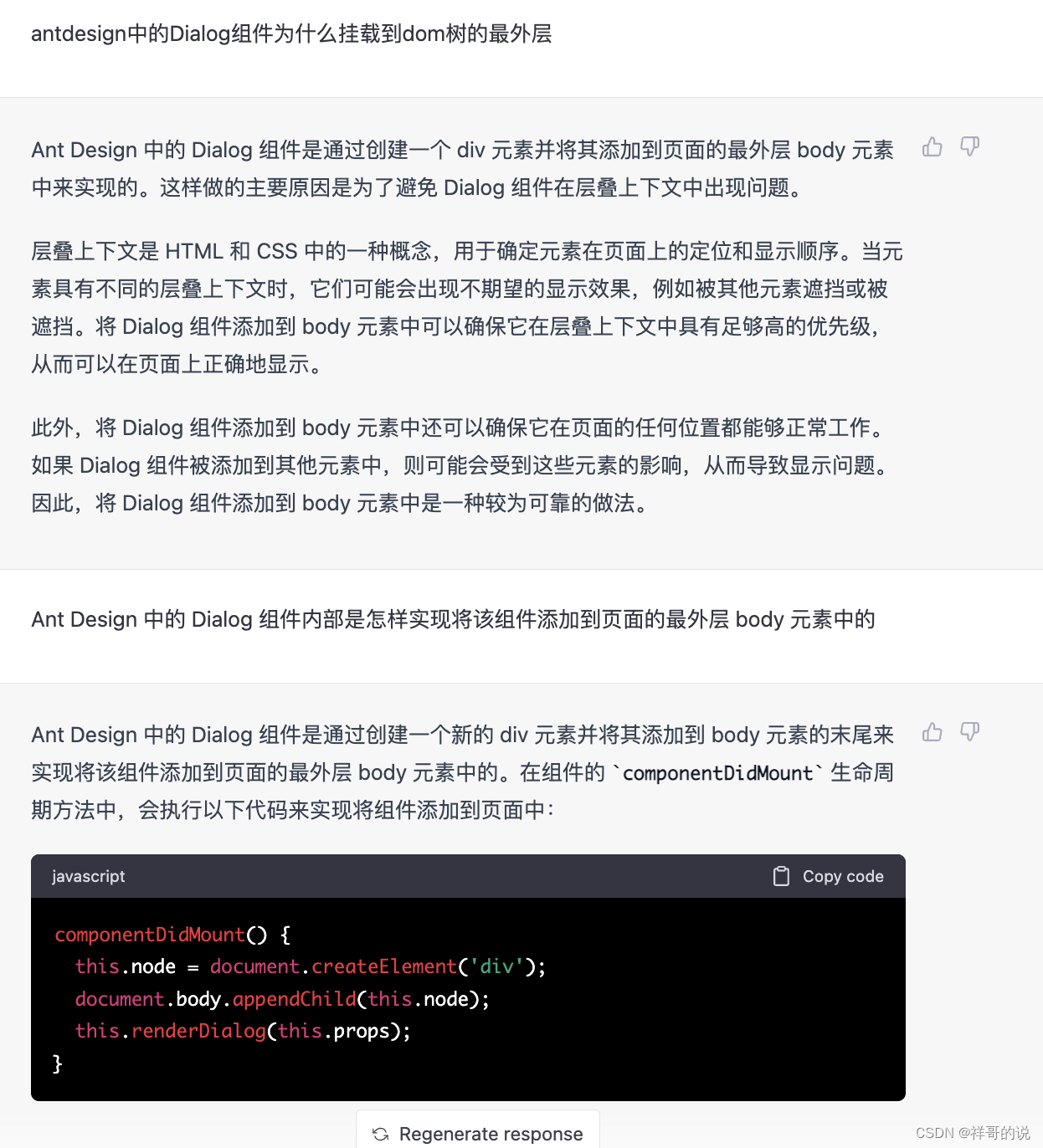
1、React 路由之HashHistory以及BrowserHistory的区别
1.原理上
- HashRouter:利用hash实现路由切换,在路径中包含了#,相当于HTML的锚点定位。(
#符号的英文叫hash,所以叫HashRouter) - BrowserRouter:利用h5 Api实现路由切换,主要是借助history对象,H5引入了history.pushState()和history.replaceState()方法,它们分别可以添加和修改历史记录的条目,这些方法通常与window.onpopstate配合使用。
2、用法上
- BrowserRouter进行组件跳转时可以传递任意参数实现组件间的通信
- HashRouter不能(除非手动拼接URL字符串),因此一般配合Redux使用,实现组件间的数据通信。
3、生产实践上
-
因为BrowserRouter模式下请求的链接都是ip地址:端口/xxxx/xxxx,因此相当于每个URL都会访问一个不同的后端地址,如果后端没有覆盖到路由就会产生404错误。
-
使用BrowserHistory路由方式,可以借助react-router-dom包的Prompt组件进行路由拦截的返回提示。
import {Prompt} from 'react-router-dom';
{/* 新建商品表单返回拦截 */}
{
!isEditStatus && formIsDirty && !get(edit, 'addCancel') && <Prompt message={(location, action) => {
if (action === 'POP') {
baiduMonitor('pro_add_form_back');
// 处理Prompt之后,浏览器由于pop缺少当前页路由记录,导致返回按钮置灰不可点问题
history.pushState(null, null, window.location.href);
return formIsDirty ? '离开此页面?系统可能不会保留您所做的更改。' : true;
}
return true;
}}
/>
}2、判断数组的方法
(1)target instanceof Array
(2) Array.isArray(target)
(3) target.constructor === Array
3、for-in与for-of的区别
for-of:一般用于遍历数组
for-in: 一般用于遍历对象
4、http和https区别,以及https加解密
首先服务器像证书机构进行证书申请:
实际得到的证书是证书机构例如CA通过自己的私钥,将服务器提交的信息(服务器公钥,域名等)进行了签名,最终证书就包含(签名+服务器信息)
当客户端发起HTTPS请求时,
首先客户端发起一次Client Hello:附加支持的TLS版本,对称算法,非对称算法,Hash算法,客户端本地随机数
服务器收到后回应一次Server Hello,附加为确定选用的TLS版本,对称算法,非对称算法,Hash算法,服务端本地随机数。
接着服务器发起一次证书传递通信,将证书+证书机构信息(证书机构公钥,签发机构名称,位置等信息)交给操作系统根证书进行私钥签名并发送
客户端收到后,首先也是通过操作系统公钥进行签名解密与(证书+证书机构信息)Hash后验证。确定无误后,再通过证书的公钥对证书签名进行解密以及Hash验证,确认无误后即确定服务器公钥无误。
接着客户端生成一个pre master secret(随机数),通过服务器公钥加密,发送给服务器,接着客户端和服务端利用之前的随机数以及pre master secret生成对称加密的秘钥开始进行对称加密通信。
通用埋点方案需要考虑到以下几个方面:
- 埋点数据的采集方式
- 埋点数据的传输方式
- 埋点数据的存储和分析方式
下面分别介绍这三个方面的解决方案。
采集方式
前端的埋点数据采集方式一般有以下几种:
- 手动埋点:通过在页面中插入JavaScript代码,手动埋点来收集用户行为数据。
- 自动埋点:通过使用框架或第三方库,自动化地收集用户行为数据。
手动埋点需要开发者手动添加埋点代码,并且对于动态生成的元素,需要在其生成时手动添加埋点代码。自动埋点则是通过框架或第三方库的方式实现,可以自动识别页面中的元素,并为其添加埋点代码。
传输方式
一般来说,前端埋点数据的传输方式有以下几种:
- 直接上报:在浏览器端通过Ajax请求将埋点数据直接上报到后端服务器。
- 间接上报:通过将埋点数据存储在浏览器的localStorage或cookie中,在用户下一次请求时一并上传到后端服务器。
- 使用第三方服务:通过调用第三方服务(如百度统计、Google Analytics等)的API,将埋点数据上传到第三方服务的服务器上。
直接上报的方式可以实时地将数据上传到后端服务器,但是可能会增加服务器的负担,同时还需要考虑到跨域请求的问题。间接上报的方式可以减少服务器的压力,但是需要考虑到数据的实时性和存储容量的问题。使用第三方服务的方式可以减少服务器的负担,并且可以使用第三方服务的分析和监控功能。
存储和分析方式
前端埋点数据的存储和分析方式可以选择自己搭建数据分析平台,也可以选择使用第三方数据分析服务。自己搭建数据分析平台可以更好地控制数据的安全和隐私,同时可以根据实际需求自定义数据分析和展示方式。使用第三方数据分析服务可以省去搭建平台的成本和人力,同时可以直接使用第三方的分析和展示工具。
综上所述,前端通用埋点方案需要根据实际情况选择采集方式、传输方式和存储和分析方式。一般来说,手动埋点和自动埋点结合的方式比较常用,使用Ajax请求或第三方服务的方式进行数据传输,使用自己搭建平台或第三方数据分析服务进行数据存储。