简介
由于挺多时候如果不太熟系kafka消费者详细的话,很容易产生问题,所有剖析一定的原理很重要。
Kafka消费者图解
消费方式
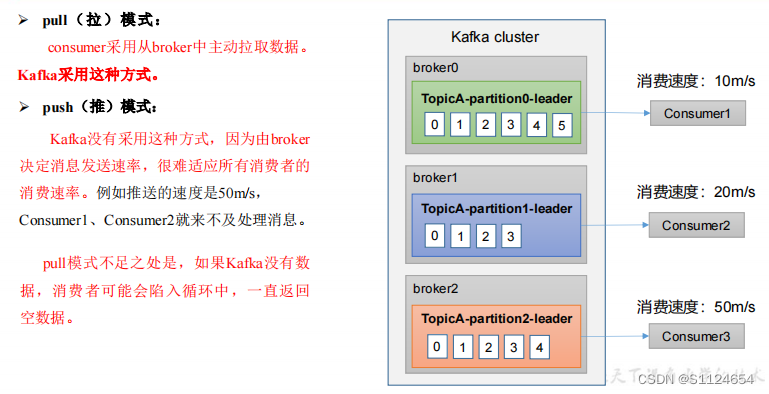
消费者总体工作流程
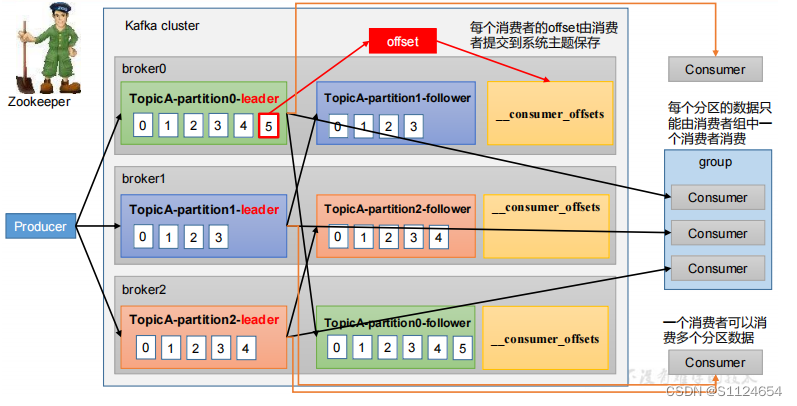
消费者组初始化流程

消费者详细消费流程

消费者重要参数
bootstrap.servers
向 Kafka 集群建立初始连接用到的 host/port 列表。
key.deserializer&value.deserializer
指定接收消息的 key 和 value 的反序列化类型。一定要写全
类名。
group.id
标记消费者所属的消费者组。
enable.auto.commit
默认值为 true,消费者会自动周期性地向服务器提交偏移
量。
auto.commit.interval.ms
如果设置了 enable.auto.commit 的值为 true , 则该值定义了
消费者偏移量向 Kafka 提交的频率, 默认 5s 。
auto.offset.reset
当 Kafka 中没有初始偏移量或当前偏移量在服务器中不存在 (如,数据被删除了),该如何处理? earliest :自动重置偏 移量到最早的偏移量。 latest :默认,自动重置偏移量为最 新的偏移量。 none :如果消费组原来的( previous )偏移量 不存在,则向消费者抛异常。 anything :向消费者抛异常。
offsets.topic.num.partitions
__consumer_offsets 的分区数, 默认是 50 个分区。
heartbeat.interval.ms
Kafka 消费者和 coordinator 之间的心跳时间, 默认 3s 。 该条目的值必须小于session.timeout.ms ,也不应该高于 session.timeout.ms 的 1/3 。
session.timeout.ms
Kafka 消费者和 coordinator 之间连接超时时间, 默认 45s。 超过该值,该消费者被移除,消费者组执行再平衡。
max.poll.interval.ms
消费者处理消息的最大时长, 默认是 5 分钟 。超过该值,该 消费者被移除,消费者组执行再平衡。
fetch.min.bytes
默认 1 个字节。消费者 获取服务器端一批消息最小的字节数。
fetch.max.wait.ms
默认 500ms 。如果没有从服务器端获取到一批数据的最小字节数 。该时间到,仍然会返回数据。
fetch.max.bytes
默认 Default: 52428800 (50 m)。消费者 获取服务器端一批 消息最大的字节数。如果服务器端一批次的数据大于该值 (50m)仍然可以拉取回来这批数据,因此,这不是一个绝 对最大值。一批次的大小受 message.max.bytes ( broker config) or max.message.bytes ( topic config )影响。
max.poll.records
一次 poll 拉取数据返回消息的最大条数, 默认是 500 条。
Kafka消费者Api
一个消费者消费一个主题
注意:
在消费者 API 代码中必须配置消费者组 id。命令行启动消费者不填写消费者组
id 会被自动填写随机的消费者组 id。
创建一个独立消费者,消费 first 主题中数据。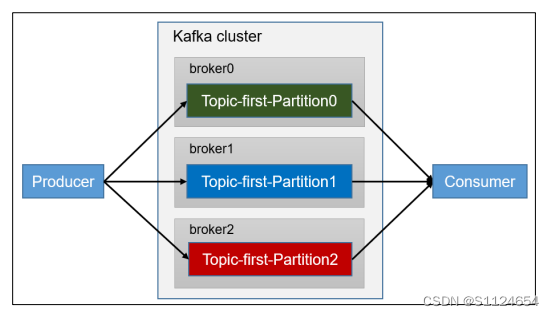
消费者代码
maven依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>2.1.0</version>
</dependency>生产者代码

public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
//kafka集群,broker-list
props.put("bootstrap.servers", "master:9092");
//批次大小
props.put("batch.size", 16384);
//等待时间
props.put("linger.ms", 1);
//RecordAccumulator缓冲区大小
props.put("buffer.memory", 33554432 * 2);
//消息压缩
props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<String, String>("first", i + "", "msg" + i), new Callback() {
//回调函数,该方法会在Producer收到ack时调用,为异步调用
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println("success->" + metadata.partition());
} else {
exception.printStackTrace();
}
}
});
}
Thread.sleep(10000);
}消费者代码
public static void main(String[] args) {
// 1.创建消费者的配置对象
Properties properties = new Properties();
// 2.给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"master:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
// 创建消费者对象
KafkaConsumer<String, String> kafkaConsumer = new
KafkaConsumer<String, String>(properties);
// 注册要消费的主题(可以消费多个主题)
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
// 拉取数据打印
while (true) {
// 设置 1s 中消费一批数据
ConsumerRecords<String, String> consumerRecords =
kafkaConsumer.poll(Duration.ofSeconds(1));
// 打印消费到的数据
for (ConsumerRecord<String, String> consumerRecord :
consumerRecords) {
System.out.println(consumerRecord);
}
}
}首先消费的时候有两种情况
1、KafkaConsumer.subscribe():为consumer自动分配partition,有内部算法保证topic-partition以最优的方式均匀分配给同group下的不同consumer。
2、KafkaConsumer.assign():为consumer手动、显示的指定需要消费的topic-partitions。
由下面的实验证明,下面博主的结论是有错误的
kafka从指定位置消费_程序三两行的技术博客_51CTO博客
消费者不同的消费方式实验(subscribe和assign)
1.先查看下分区。
./kafka-topics.sh --bootstrap-server localhost:9092 --list #高版本
./kafka-topics.sh --list --zookeeper localhost:2181[bigdata@master bin]$ ./kafka-topics.sh --bootstrap-server localhost:9092 --list
ATLAS_ENTITIES
ATLAS_HOOK
__consumer_offsets
comment_info
first
2.查看下测试的first分区的数量。
./kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic first如下现在有4个分区,如果分区不太够做实验的话,添加几个新分区
./kafka-topics.sh --bootstrap-server localhost:9092 --alter --topic first --partitions 3[bigdata@master bin]$ ./kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic first
Topic: first PartitionCount: 4 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: first Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: first Partition: 1 Leader: 2 Replicas: 2 Isr: 2
Topic: first Partition: 2 Leader: 0 Replicas: 0 Isr: 0
Topic: first Partition: 3 Leader: 1 Replicas: 1 Isr: 1
3.查看下现在分区的offset。
#查看消费者组对应主题的offset
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test[bigdata@master bin]$ ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test
Consumer group 'test' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
test first 3 15 15 0 - - -
test first 2 6 6 0 - - -
test first 1 3 3 0 - - -
test first 0 6 6 0 - - -
4.查看kafka内所有的消费者组。
#查看所有的消费者组
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list[bigdata@master bin]$ ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
test
由上面可以看到现在的first主题对应的分区有0,1,2,3,分别对应的offset为6,3,6,15
生产者代码
先发送10条信息
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
//kafka集群,broker-list
props.put("bootstrap.servers", "master:9092");
//批次大小
props.put("batch.size", 16384);
//等待时间
props.put("linger.ms", 1);
//RecordAccumulator缓冲区大小
props.put("buffer.memory", 33554432 * 2);
//消息压缩
props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<String, String>("first", i + "", "msg" + i), new Callback() {
//回调函数,该方法会在Producer收到ack时调用,为异步调用
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println("success->" + metadata.partition());
} else {
exception.printStackTrace();
}
}
});
}
Thread.sleep(10000);
}消费者(assign方式消费主题first分区1的数据)
先启动消费者
public static void main(String[] args) {
// 1.创建消费者的配置对象
Properties properties = new Properties();
// 2.给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"master:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
// 创建消费者对象
KafkaConsumer<String, String> kafkaConsumer = new
KafkaConsumer<String, String>(properties);
// 注册要消费的主题(可以消费多个主题)
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
// 拉取数据打印
while (true) {
// 设置 1s 中消费一批数据
ConsumerRecords<String, String> consumerRecords =
kafkaConsumer.poll(Duration.ofSeconds(1));
// 打印消费到的数据
for (ConsumerRecord<String, String> consumerRecord :
consumerRecords) {
System.out.println(consumerRecord);
}
}
}然后启动生产者(生产10条消息)
success->1
success->3
success->3
success->3
success->3
success->3
success->0
success->0
success->2
success->2
消费者打印为(从信息可以看出知识消费了分区1的数据,从offset3开始消费)
ConsumerRecord(topic = first, partition = 1, leaderEpoch = 0, offset = 3, CreateTime = 1677119322219, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 4, value = msg4)
这个时候查看一下现在的主题分区offset情况
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test[bigdata@master bin]$ ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test
Consumer group 'test' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
test first 3 15 20 5 - - -
test first 2 6 8 2 - - -
test first 1 4 4 0 - - -
test first 0 6 8 2 - - -
可以发现还是之前的first主题对应的分区有0,1,2,3,分别对应的offset为6,3,6,15,现在first主题对应的分区有0,1,2,3,分别对应的offset为6,4,6,15。说明指定分区消费成功。
消费者2(subscribe方式,为了不影响实验效果先关闭上面的assign消费者)
public static void main(String[] args) {
// 1.创建消费者的配置对象
Properties properties = new Properties();
// 2.给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"master:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
// 创建消费者对象
KafkaConsumer<String, String> kafkaConsumer = new
KafkaConsumer<String, String>(properties);
// 注册要消费的主题(可以消费多个主题)
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
// 拉取数据打印
while (true) {
// 设置 1s 中消费一批数据
ConsumerRecords<String, String> consumerRecords =
kafkaConsumer.poll(Duration.ofSeconds(1));
// 打印消费到的数据
for (ConsumerRecord<String, String> consumerRecord :
consumerRecords) {
System.out.println(consumerRecord);
}
}
}控制台打印如下
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 6, CreateTime = 1677119322219, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 5, value = msg5)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 7, CreateTime = 1677119322219, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 6, value = msg6)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 15, CreateTime = 1677119322219, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 1, value = msg1)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 16, CreateTime = 1677119322219, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 3, value = msg3)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 17, CreateTime = 1677119322219, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 7, value = msg7)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 18, CreateTime = 1677119322220, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 8, value = msg8)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 19, CreateTime = 1677119322220, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 9, value = msg9)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 6, CreateTime = 1677119322116, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 0, value = msg0)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 7, CreateTime = 1677119322219, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 2, value = msg2)
查看现在的主题offset的情况
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test[bigdata@master bin]$ ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
test first 0 8 8 0 consumer-1-4b3191cc-ba22-46f2-a991-efb131666551 /192.168.66.240 consumer-1
test first 1 4 4 0 consumer-1-4b3191cc-ba22-46f2-a991-efb131666551 /192.168.66.240 consumer-1
test first 2 8 8 0 consumer-1-4b3191cc-ba22-46f2-a991-efb131666551 /192.168.66.240 consumer-1
test first 3 20 20 0 consumer-1-4b3191cc-ba22-46f2-a991-efb131666551 /192.168.66.240 consumer-1
刚才由assign消费完以后first主题对应的分区有0,1,2,3,分别对应的offset为6,4,6,15。启动subscribe以后first主题对应的分区有0,1,2,3,分别对应的offset为8,4,8,20,消费到刚才发送消息的10条里面的9条,有一条被特点的assign消费了。
latest&earliest
设置参数
//一般配置earliest 或者latest 值,因为在kafka官网上面默认的配置就是latest
props.put("auto.offset.reset", "latest");
现在重新创建一个消费者(第一个消费者组为test,下面的是testtow)
public static void main(String[] args) {
// 1.创建消费者的配置对象
Properties properties = new Properties();
// 2.给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"master:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "testtow");
// 创建消费者对象
KafkaConsumer<String, String> kafkaConsumer = new
KafkaConsumer<String, String>(properties);
// 注册要消费的主题(可以消费多个主题)
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
// 拉取数据打印
while (true) {
// 设置 1s 中消费一批数据
ConsumerRecords<String, String> consumerRecords =
kafkaConsumer.poll(Duration.ofSeconds(1));
// 打印消费到的数据
for (ConsumerRecord<String, String> consumerRecord :
consumerRecords) {
System.out.println(consumerRecord);
}
}
}启动以后可以看到没有任何输出,并且对应分区的offset直接到了最新的位置,可以看出启动以后直接把offset设置成了最新提交的offset,所以之前提交过的就没有消费到。
查看下对应消费者组的offset(可以看到是从最后一个消息开始消费的)
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group testtow[bigdata@master bin]$ ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group testtow
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
testtow first 0 8 8 0 consumer-1-33685b26-546e-4c6e-bf90-ae26ba0bf271 /192.168.66.240 consumer-1
testtow first 1 4 4 0 consumer-1-33685b26-546e-4c6e-bf90-ae26ba0bf271 /192.168.66.240 consumer-1
testtow first 2 8 8 0 consumer-1-33685b26-546e-4c6e-bf90-ae26ba0bf271 /192.168.66.240 consumer-1
testtow first 3 20 20 0 consumer-1-33685b26-546e-4c6e-bf90-ae26ba0bf271 /192.168.66.240 consumer-1
然后停止消费者,启动生产者,发送完消息以后,在启动下消费者testtow,可以看到消费到了10条信息。
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 20, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 1, value = msg1)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 21, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 3, value = msg3)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 22, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 7, value = msg7)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 23, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 8, value = msg8)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 24, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 9, value = msg9)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 8, CreateTime = 1677120679017, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 0, value = msg0)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 9, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 2, value = msg2)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 8, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 5, value = msg5)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 9, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 6, value = msg6)
ConsumerRecord(topic = first, partition = 1, leaderEpoch = 0, offset = 4, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 4, value = msg4)
查看下消费者组testtow的offset。
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group testtow[bigdata@master bin]$ ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group testtow
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
testtow first 0 10 10 0 consumer-1-2e719407-1302-44ea-9db4-6bbe165a0a23 /192.168.66.240 consumer-1
testtow first 1 5 5 0 consumer-1-2e719407-1302-44ea-9db4-6bbe165a0a23 /192.168.66.240 consumer-1
testtow first 2 10 10 0 consumer-1-2e719407-1302-44ea-9db4-6bbe165a0a23 /192.168.66.240 consumer-1
testtow first 3 25 25 0 consumer-1-2e719407-1302-44ea-9db4-6bbe165a0a23 /192.168.66.240 consumer-1
查看下消费者组test的offset(可以看到不同的消费者组消费对应的offset是互相独立的)。
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test[bigdata@master bin]$ ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test
Consumer group 'test' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
test first 3 20 25 5 - - -
test first 2 8 10 2 - - -
test first 1 4 5 1 - - -
test first 0 8 10 2 - - -
然后启动消费组test(可以看到同样消费到了10条信息)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 8, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 5, value = msg5)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 9, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 6, value = msg6)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 20, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 1, value = msg1)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 21, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 3, value = msg3)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 22, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 7, value = msg7)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 23, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 8, value = msg8)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 24, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 9, value = msg9)
ConsumerRecord(topic = first, partition = 1, leaderEpoch = 0, offset = 4, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 4, value = msg4)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 8, CreateTime = 1677120679017, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 0, value = msg0)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 9, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 2, value = msg2)
现在测试下earliest(重新创建一个消费者组testthree,用earliest的方式)
public static void main(String[] args) {
// 1.创建消费者的配置对象
Properties properties = new Properties();
// 2.给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"master:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "testthree");
properties.put("auto.offset.reset", "earliest");
// 创建消费者对象
KafkaConsumer<String, String> kafkaConsumer = new
KafkaConsumer<String, String>(properties);
// 注册要消费的主题(可以消费多个主题)
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
// 拉取数据打印
while (true) {
// 设置 1s 中消费一批数据
ConsumerRecords<String, String> consumerRecords =
kafkaConsumer.poll(Duration.ofSeconds(1));
// 打印消费到的数据
for (ConsumerRecord<String, String> consumerRecord :
consumerRecords) {
System.out.println(consumerRecord);
}
}
}打印的信息为(可以看到是从最开始的地方消费)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 0, CreateTime = 1677117688626, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 1, value = msg1)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 1, CreateTime = 1677117688626, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 3, value = msg3)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 2, CreateTime = 1677117688626, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 7, value = msg7)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 3, CreateTime = 1677117688626, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 8, value = msg8)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 4, CreateTime = 1677117688627, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 9, value = msg9)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 5, CreateTime = 1677117706457, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 1, value = msg1)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 6, CreateTime = 1677117706458, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 3, value = msg3)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 7, CreateTime = 1677117706458, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 7, value = msg7)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 8, CreateTime = 1677117706458, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 8, value = msg8)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 9, CreateTime = 1677117706458, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 9, value = msg9)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 10, CreateTime = 1677119214986, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 1, value = msg1)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 11, CreateTime = 1677119214986, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 3, value = msg3)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 12, CreateTime = 1677119214986, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 7, value = msg7)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 13, CreateTime = 1677119214986, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 8, value = msg8)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 14, CreateTime = 1677119214986, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 9, value = msg9)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 15, CreateTime = 1677119322219, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 1, value = msg1)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 16, CreateTime = 1677119322219, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 3, value = msg3)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 17, CreateTime = 1677119322219, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 7, value = msg7)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 18, CreateTime = 1677119322220, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 8, value = msg8)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 19, CreateTime = 1677119322220, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 9, value = msg9)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 20, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 1, value = msg1)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 21, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 3, value = msg3)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 22, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 7, value = msg7)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 23, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 8, value = msg8)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 24, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 9, value = msg9)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 0, CreateTime = 1677117688502, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 0, value = msg0)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 1, CreateTime = 1677117688626, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 2, value = msg2)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 2, CreateTime = 1677117706379, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 0, value = msg0)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 3, CreateTime = 1677117706458, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 2, value = msg2)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 4, CreateTime = 1677119214862, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 0, value = msg0)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 5, CreateTime = 1677119214986, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 2, value = msg2)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 6, CreateTime = 1677119322116, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 0, value = msg0)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 7, CreateTime = 1677119322219, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 2, value = msg2)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 8, CreateTime = 1677120679017, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 0, value = msg0)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 9, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 2, value = msg2)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 0, CreateTime = 1677117688626, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 5, value = msg5)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 1, CreateTime = 1677117688626, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 6, value = msg6)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 2, CreateTime = 1677117706458, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 5, value = msg5)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 3, CreateTime = 1677117706458, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 6, value = msg6)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 4, CreateTime = 1677119214986, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 5, value = msg5)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 5, CreateTime = 1677119214986, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 6, value = msg6)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 6, CreateTime = 1677119322219, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 5, value = msg5)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 7, CreateTime = 1677119322219, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 6, value = msg6)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 8, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 5, value = msg5)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 9, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 6, value = msg6)
ConsumerRecord(topic = first, partition = 1, leaderEpoch = 0, offset = 0, CreateTime = 1677117688626, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 4, value = msg4)
ConsumerRecord(topic = first, partition = 1, leaderEpoch = 0, offset = 1, CreateTime = 1677117706458, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 4, value = msg4)
ConsumerRecord(topic = first, partition = 1, leaderEpoch = 0, offset = 2, CreateTime = 1677119214986, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 4, value = msg4)
ConsumerRecord(topic = first, partition = 1, leaderEpoch = 0, offset = 3, CreateTime = 1677119322219, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 4, value = msg4)
ConsumerRecord(topic = first, partition = 1, leaderEpoch = 0, offset = 4, CreateTime = 1677120679103, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 4, value = msg4)
关闭testthree,然后重新启动(可以看到如果第一次没有消费消息,从最开始的地方消费,如果开始的地方消费了一次那么就从,末尾消费)

指定offset消费
auto.offset.reset = earliest | latest | none 默认是 latest 。
(1) earliest :自动将偏移量重置为最早的偏移量, --from-beginning 。
(2) latest (默认值) :自动将偏移量重置为最新偏移量。
(3) none :如果未找到消费者组的先前偏移量,则向消费者抛出异常。
任意位置消费案例
先查看下现在的分区信息
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test[bigdata@master bin]$ ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
test first 0 14 14 0 consumer-1-6104feeb-6d1a-4d90-bf06-58b3f2c8c89a /192.168.66.240 consumer-1
test first 1 7 7 0 consumer-1-6104feeb-6d1a-4d90-bf06-58b3f2c8c89a /192.168.66.240 consumer-1
test first 2 14 14 0 consumer-1-6104feeb-6d1a-4d90-bf06-58b3f2c8c89a /192.168.66.240 consumer-1
test first 3 35 35 0 consumer-1-6104feeb-6d1a-4d90-bf06-58b3f2c8c89a /192.168.66.240 consumer-1
下面指定从每个分区的offerset为30开始消费
public static void main(String[] args) {
// 配置信息
Properties properties = new Properties();
// 连接
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"master:9092");
// key value 反序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
// 1 创建一个消费者
KafkaConsumer<String, String> kafkaConsumer = new
KafkaConsumer<>(properties);
// 2 订阅一个主题
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
Set<TopicPartition> assignment= new HashSet<>();
while (assignment.size() == 0) {
kafkaConsumer.poll(Duration.ofSeconds(1));
// 获取消费者分区分配信息(有了分区分配信息才能开始消费)
assignment = kafkaConsumer.assignment();
}
// 遍历所有分区,并指定 offset 从 1700 的位置开始消费
for (TopicPartition tp: assignment) {
kafkaConsumer.seek(tp, 30);
}
// 3 消费该主题数据
while (true) {
ConsumerRecords<String, String> consumerRecords =
kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> consumerRecord :
consumerRecords) {
System.out.println(consumerRecord);
}
}
}消费到的数据为(并且指定的位置可以重复的消费)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 30, CreateTime = 1677121290475, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 1, value = msg1)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 31, CreateTime = 1677121290476, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 3, value = msg3)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 32, CreateTime = 1677121290476, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 7, value = msg7)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 33, CreateTime = 1677121290476, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 8, value = msg8)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 34, CreateTime = 1677121290476, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 9, value = msg9)
指定时间消费
public static void main(String[] args) {
Properties properties = new Properties();
// 连接
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"master:9092");
// key value 反序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
// 1 创建一个消费者
KafkaConsumer<String, String> kafkaConsumer = new
KafkaConsumer<>(properties);
// 2 订阅一个主题
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
Set<TopicPartition> assignment = new HashSet<>();
while (assignment.size() == 0) {
kafkaConsumer.poll(Duration.ofSeconds(1));
// 获取消费者分区分配信息(有了分区分配信息才能开始消费)
assignment = kafkaConsumer.assignment();
}
HashMap<TopicPartition, Long> timestampToSearch = new
HashMap<>();
// 封装集合存储,每个分区对应一天前的数据
for (TopicPartition topicPartition : assignment) {
// timestampToSearch.put(topicPartition,
// System.currentTimeMillis() - 1 * 24 * 3600 * 1000);
timestampToSearch.put(topicPartition,
1677121290476L);
}
// 获取从 1 天前开始消费的每个分区的 offset
Map<TopicPartition, OffsetAndTimestamp> offsets =
kafkaConsumer.offsetsForTimes(timestampToSearch);
// 遍历每个分区,对每个分区设置消费时间。
for (TopicPartition topicPartition : assignment) {
OffsetAndTimestamp offsetAndTimestamp =
offsets.get(topicPartition);
// 根据时间指定开始消费的位置
if (offsetAndTimestamp != null){
kafkaConsumer.seek(topicPartition,
offsetAndTimestamp.offset());
}
}
// 3 消费该主题数据
while (true) {
ConsumerRecords<String, String> consumerRecords =
kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> consumerRecord :
consumerRecords) {
System.out.println(consumerRecord);
}
}
}得到的数据为(可以看错是指定创建时间为开始消费的位置上面指定的是1677121290476L,所以下面的都是从这个时间开始的到后面最后的数据都能够消费到)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 12, CreateTime = 1677121290476, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 5, value = msg5)
ConsumerRecord(topic = first, partition = 2, leaderEpoch = 0, offset = 13, CreateTime = 1677121290476, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 6, value = msg6)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 31, CreateTime = 1677121290476, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 3, value = msg3)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 32, CreateTime = 1677121290476, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 7, value = msg7)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 33, CreateTime = 1677121290476, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 8, value = msg8)
ConsumerRecord(topic = first, partition = 3, leaderEpoch = 0, offset = 34, CreateTime = 1677121290476, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 9, value = msg9)
ConsumerRecord(topic = first, partition = 1, leaderEpoch = 0, offset = 6, CreateTime = 1677121290476, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 4, value = msg4)
ConsumerRecord(topic = first, partition = 0, leaderEpoch = 0, offset = 13, CreateTime = 1677121290476, serialized key size = 1, serialized value size = 4, headers = RecordHeaders(headers = [], isReadOnly = false), key = 2, value = msg2)
消费者事务
为什么要事务?
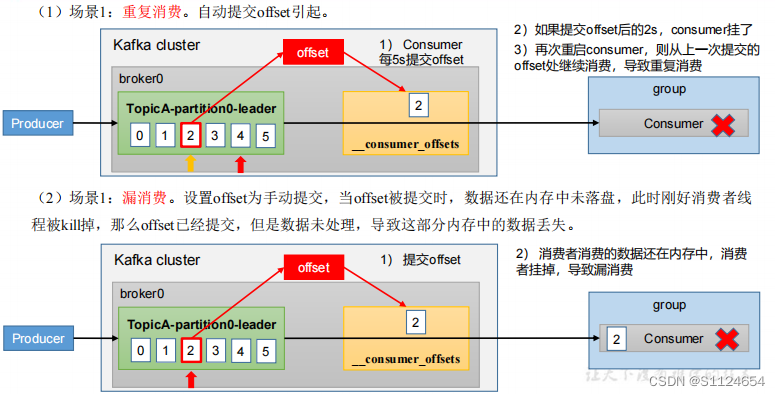
数据积压
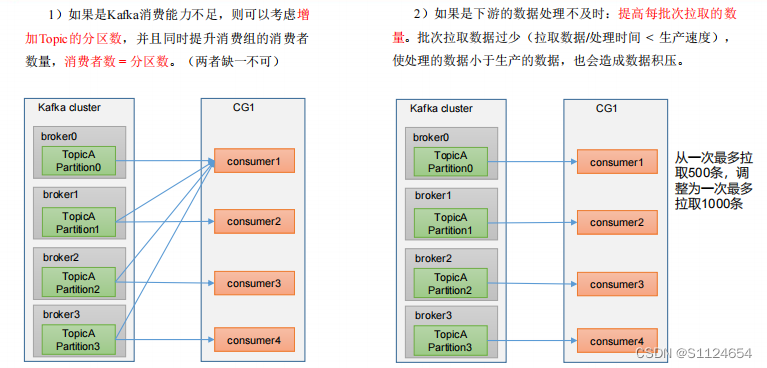
相关参数
fetch.max.bytes
默认 Default: 52428800 (50 m)。消费者 获取服务器端一批 消息最大的字节数。如果服务器端一批次的数据大于该值 (50m)仍然可以拉取回来这批数据,因此,这不是一个绝 对最大值。一批的大小受 message.max.bytes ( broker config) or max.message.bytes ( topic config )影响。
max.poll.records
一次 poll 拉取数据返回消息的最大条数,默认是 500 条 。
消费者分区分配&在平衡
配置参数
partition.assignment.strategy
默认策略就是Range和Sticky

Range 以及再平衡
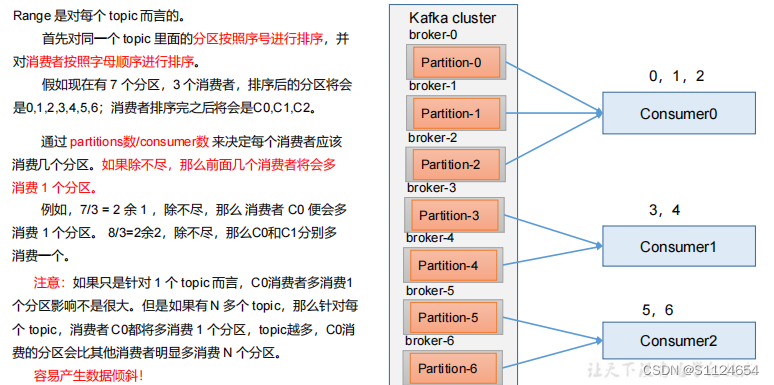
修改分区数
bin/kafka-topics.sh --bootstrap-server master:9092 --alter --topic first --partitions 7总结:
- 如果消费者0宕机那么0,1,2这一次的消息就会全部给消费者1消费
- 然后后面就是在平衡以后的分配消费者1消费0,1,2,消费者2消费4,5,6。
RoundRobin
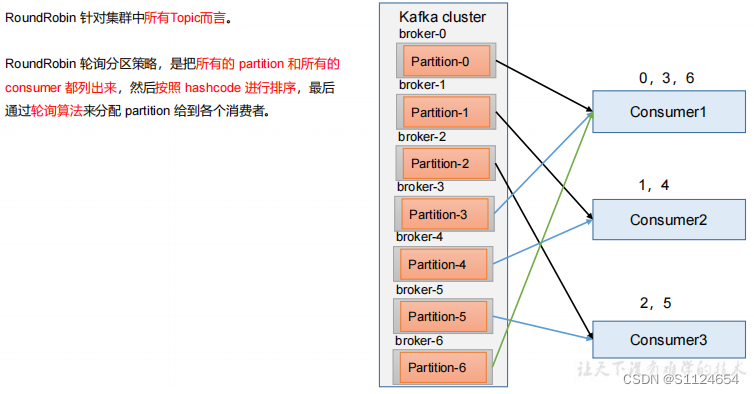
总结:
- 如果消费者0宕机,那么把0,3,6轮询的分配给消费者2和消费者3 。
- 然后在轮训的平衡。
Sticky
尽量随机均匀分部在每一个broker(生产环境尽量用它)。
实验RoundRobin
先创建7个分区。
./kafka-topics.sh --bootstrap-server master:9092 --alter --topic first --partitions 7查看分区情况。
./kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic first[bigdata@master bin]$ ./kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic first
Topic: first PartitionCount: 7 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: first Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: first Partition: 1 Leader: 2 Replicas: 2 Isr: 2
Topic: first Partition: 2 Leader: 0 Replicas: 0 Isr: 0
Topic: first Partition: 3 Leader: 1 Replicas: 1 Isr: 1
Topic: first Partition: 4 Leader: 2 Replicas: 2 Isr: 2
Topic: first Partition: 5 Leader: 0 Replicas: 0 Isr: 0
Topic: first Partition: 6 Leader: 1 Replicas: 1 Isr: 1
消费者代码
public static void main(String[] args) {
// 1.创建消费者的配置对象
Properties properties = new Properties();
// 2.给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"master:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
properties.put("partition.assignment.strategy","org.apache.kafka.clients.consumer.RoundRobinAssignor");
// 创建消费者对象
KafkaConsumer<String, String> kafkaConsumer = new
KafkaConsumer<String, String>(properties);
// 注册要消费的主题(可以消费多个主题)
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
// 拉取数据打印
while (true) {
// 设置 1s 中消费一批数据
ConsumerRecords<String, String> consumerRecords =
kafkaConsumer.poll(Duration.ofSeconds(1));
// 打印消费到的数据
for (ConsumerRecord<String, String> consumerRecord :
consumerRecords) {
System.out.println(consumerRecord);
}
}
}
启动3个消费者。
 下面分别消费到了3,4,3条信息,在启动生产者生成 了10条信息以后。
下面分别消费到了3,4,3条信息,在启动生产者生成 了10条信息以后。
 下面关闭一个消费者,然后在生产10条,过了一会,对应的消费者消费到了关闭的消费者的信息。
下面关闭一个消费者,然后在生产10条,过了一会,对应的消费者消费到了关闭的消费者的信息。

注意:消费者组开始设定好是哪一种以后,后面修改在均衡策略会报错,也就是一个消费者组只能够开始的时候缺点是哪一种消费均衡。也就是说开始是3,4,3分配,后面挂了一个以后,两个没哟挂的为2,2,过了以后以后是然后在个分配两条2,2,也就是挂了的平均分配到其他的两个消费者里面,后面发送在均衡以后的情况是6,4。也就是均衡好了,后面如果加入消费者也就是现在是2个,把刚才挂掉的加入以后又变成了3,4,3。
实验Range
消费者代码
public static void main(String[] args) {
// 1.创建消费者的配置对象
Properties properties = new Properties();
// 2.给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"master:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test1");
properties.put("partition.assignment.strategy","org.apache.kafka.clients.consumer.RangeAssignor");
// 创建消费者对象
KafkaConsumer<String, String> kafkaConsumer = new
KafkaConsumer<String, String>(properties);
// 注册要消费的主题(可以消费多个主题)
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);
// 拉取数据打印
while (true) {
// 设置 1s 中消费一批数据
ConsumerRecords<String, String> consumerRecords =
kafkaConsumer.poll(Duration.ofSeconds(1));
// 打印消费到的数据
for (ConsumerRecord<String, String> consumerRecord :
consumerRecords) {
System.out.println(consumerRecord);
}
}
}如果消费者挂了以后,会把消费任务全部的给下一个消费者,而不是负载均衡的情况。也就是说开始是2,2,6,后面是2,2。让后其中一个消费者在收到全部剩下的6条信息。后面就一直是2,6,如果挂掉的新加入进来那么又变成2,2,6。
默认的就是Range

Flume消费Kafka源码解析
看源码得到的结论是Flume实现了Kakfa Source的exactly-once语义。
这里研究下Flume的Kafka Source是怎么消费kafka的信息的呢?
前言
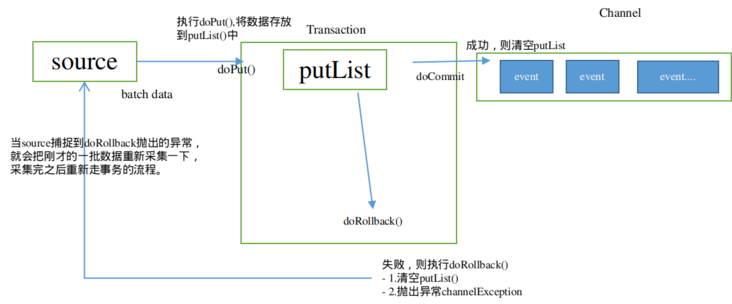
put事务
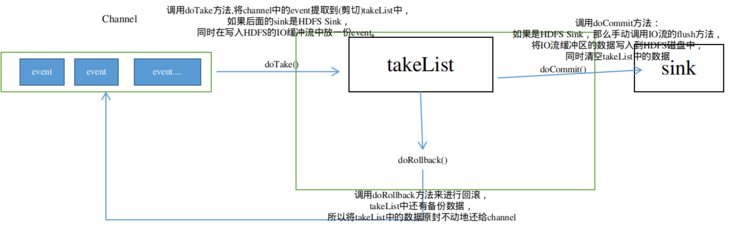
take事务
参考文章
大数据 - 三.Flume事务和内部原理 - 个人文章 - SegmentFault 思否
找到源码
https://github.com/apache/flume

查看原理
1.查看配置类信息,可以看到默认的提交offset方式是false。所以我们可以猜到flume是相关事务处理完以后,手动提交的offset,哪个在source的事务有一个dotake的方法。

相关消费kafka的源代码(自己标注了中文注解)
@Override
protected Status doProcess() throws EventDeliveryException {
final String batchUUID = UUID.randomUUID().toString();
String kafkaKey;
Event event;
byte[] eventBody;
try {
// prepare time variables for new batch
final long nanoBatchStartTime = System.nanoTime();
final long batchStartTime = System.currentTimeMillis();
final long maxBatchEndTime = System.currentTimeMillis() + maxBatchDurationMillis;
//如果拉取的数据小于每一批次的上限并且时间小于消费者等待的时间
while (eventList.size() < batchUpperLimit &&
System.currentTimeMillis() < maxBatchEndTime) {
//如果消费到的记录为空,也就是没有消费到数据
if (it == null || !it.hasNext()) {
// Obtaining new records
// Poll time is remainder time for current batch.
long durMs = Math.max(0L, maxBatchEndTime - System.currentTimeMillis());
Duration duration = Duration.ofMillis(durMs);
ConsumerRecords<String, byte[]> records = consumer.poll(duration);
it = records.iterator();
// this flag is set to true in a callback when some partitions are revoked.
// If there are any records we commit them.
if (rebalanceFlag.compareAndSet(true, false)) {
break;
}
//如果没有读取到数据那么就跳出循环
// check records after poll
if (!it.hasNext()) {
counter.incrementKafkaEmptyCount();
log.debug("Returning with backoff. No more data to read");
// batch time exceeded
break;
}
}
//这里是获取到了kafka的数据
// get next message
ConsumerRecord<String, byte[]> message = it.next();
kafkaKey = message.key();
//如果是Avro格式进入这里
if (useAvroEventFormat) {
//Assume the event is in Avro format using the AvroFlumeEvent schema
//Will need to catch the exception if it is not
ByteArrayInputStream in =
new ByteArrayInputStream(message.value());
decoder = DecoderFactory.get().directBinaryDecoder(in, decoder);
if (!reader.isPresent()) {
reader = Optional.of(
new SpecificDatumReader<AvroFlumeEvent>(AvroFlumeEvent.class));
}
//This may throw an exception but it will be caught by the
//exception handler below and logged at error
AvroFlumeEvent avroevent = reader.get().read(null, decoder);
eventBody = avroevent.getBody().array();
headers = toStringMap(avroevent.getHeaders());
} else {
//普通的数据格式在这个地方
eventBody = message.value();
headers.clear();
headers = new HashMap<String, String>(4);
}
//在消息的头部设置一些必要的信息
// Add headers to event (timestamp, topic, partition, key) only if they don't exist
if (!headers.containsKey(TIMESTAMP_HEADER)) {
headers.put(TIMESTAMP_HEADER, String.valueOf(message.timestamp()));
}
if (!headerMap.isEmpty()) {
Headers kafkaHeaders = message.headers();
for (Map.Entry<String, String> entry : headerMap.entrySet()) {
for (Header kafkaHeader : kafkaHeaders.headers(entry.getValue())) {
headers.put(entry.getKey(), new String(kafkaHeader.value()));
}
}
}
// Only set the topic header if setTopicHeader and it isn't already populated
if (setTopicHeader && !headers.containsKey(topicHeader)) {
headers.put(topicHeader, message.topic());
}
if (!headers.containsKey(PARTITION_HEADER)) {
headers.put(PARTITION_HEADER, String.valueOf(message.partition()));
}
if (!headers.containsKey(OFFSET_HEADER)) {
headers.put(OFFSET_HEADER, String.valueOf(message.offset()));
}
if (kafkaKey != null) {
headers.put(KEY_HEADER, kafkaKey);
}
if (log.isTraceEnabled()) {
if (LogPrivacyUtil.allowLogRawData()) {
log.trace("Topic: {} Partition: {} Message: {}", new String[]{
message.topic(),
String.valueOf(message.partition()),
new String(eventBody)
});
} else {
log.trace("Topic: {} Partition: {} Message arrived.",
message.topic(),
String.valueOf(message.partition()));
}
}
//把kafka的ConsumerRecord封装成Flume的一个event
event = EventBuilder.withBody(eventBody, headers);
//把拉取的一批次kafka的数据一天天的添加到eventList里面
eventList.add(event);
if (log.isDebugEnabled()) {
log.debug("Waited: {} ", System.currentTimeMillis() - batchStartTime);
log.debug("Event #: {}", eventList.size());
}
// For each partition store next offset that is going to be read.
tpAndOffsetMetadata.put(new TopicPartition(message.topic(), message.partition()),
new OffsetAndMetadata(message.offset() + 1, batchUUID));
}
//如果有拉取到kafka的信息进入这里
if (eventList.size() > 0) {
counter.addToKafkaEventGetTimer((System.nanoTime() - nanoBatchStartTime) / (1000 * 1000));
counter.addToEventReceivedCount((long) eventList.size());
getChannelProcessor().processEventBatch(eventList);
counter.addToEventAcceptedCount(eventList.size());
//处理完以后写入channel
if (log.isDebugEnabled()) {
log.debug("Wrote {} events to channel", eventList.size());
}
eventList.clear();
//提交到channel以后手动提交kafka的偏移量
if (!tpAndOffsetMetadata.isEmpty()) {
long commitStartTime = System.nanoTime();
consumer.commitSync(tpAndOffsetMetadata);
long commitEndTime = System.nanoTime();
counter.addToKafkaCommitTimer((commitEndTime - commitStartTime) / (1000 * 1000));
tpAndOffsetMetadata.clear();
}
return Status.READY;
}
return Status.BACKOFF;
} catch (Exception e) {
log.error("KafkaSource EXCEPTION, {}", e);
counter.incrementEventReadOrChannelFail(e);
return Status.BACKOFF;
}
}也就是说上面得到的结论是Flume关闭了自动提交offset,Flume在每一次消费到数据以后放到channel以后手动提交的offset,这里就会出现点问题,如果提交到channel以后突然程序挂了,那么就会有重复消费的情况,Flume保证了消费Kafka的最少一次语义。这个就想到了Flink保证消费Kafka的精确一次语义,是通过checkpoint实现的,Sink向JobManage确认状态都保存到检查点时,checkpoint才真正的完成,也就是Sink端又幂等操作,或者是事务就能够保证exactly-once语义,而在这里的Flume显然只是保证最少一次的语义。然而Flume的processEventBatch方法里面实现了事务,所以Flume也是实现了exactly-once。
Flume使用的是Kafka生产者的事务。