ConvNext通过模仿Transformer的架构,将CNN在图像层面的表现高于同期的Transformer state-of-art。这里记录下使用ConvNext进行图像分类的配置过程。
平台环境
实验环境及配置:
Pytorch: 1.12.1
CUDA: 11.6 版本(使用 nvcc --version 查看)
GPU:显存8G
操作系统: ubuntu20.04
1 下载ConvNext源码
源码链接
https://github.com/facebookresearch/ConvNeXt
2 环境配置过程,其实可以参看官方文档中的 install.md 的内容,但这里我记录下自己的环境配置过程
2.1 使用Conda构建convnext的虚拟环境
conda create -n convnext python=3.8 -y
2.2 进入虚拟环境
conda activate convnext
2.3 配置PyTorch环境(可以参看该博客)
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.6
2.4 将源码解压后,安装下面的辅助包,注意官方推荐的是 timm 0.3.2,由于我使用的torch版本较高,所以timm 0.3.2在运行时候,会报异常:ImportError:cannot import name ‘container_abcs’ from ‘torch._six’。我的解决方法就是换用高版本的 timm即可,这里使用 timm==0.4.12 版本
pip install timm==0.4.12 tensorboardX six
3 下载预训练模型
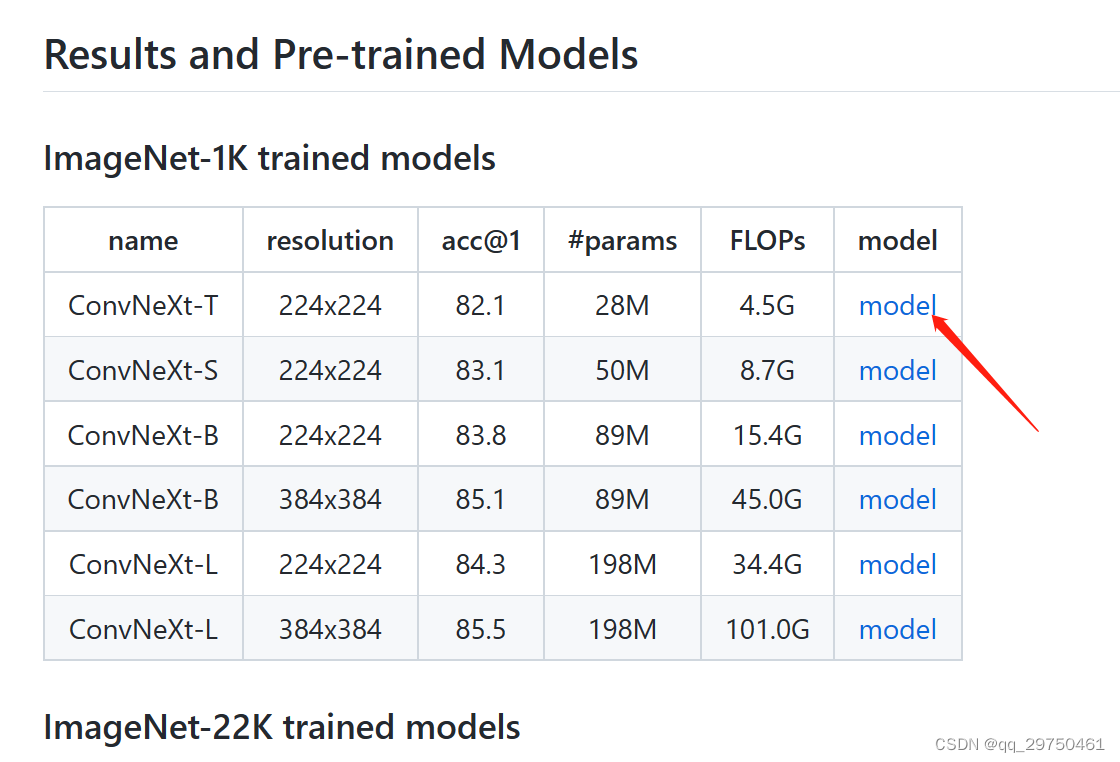
【注】将下载好的模型放置在合适的位置,最好还是在convnext的代码文件夹下,建立个 pre_models这样的文件夹
4 将自定义数据集设置为 ImageNet 的格式,这个可以写程序实现

5 调整程序,这个只是记录下我调整的过程,您的调整过程,可结合您的数据及任务要求进行调整。
5.1 main.py
其中主要是 get_args_parser 函数中的超参数配置,比如:batch_size epochs input_size 等,这里就不详细说了,结合自身情况进行设置。其中主要的参数是 nb_classes,要设置为自身的种类数量。


datasets.py 中,主要修改下面标红的区域,当然我选择的是 IMNET格式的数据,如果您选用的其他格式,可自行设置。

utils.py 中,设置加载预训练模型的头部,要与您的类别数量相对应

我把我的代码贴在这里,仅供参考,其中 100为种类数量
if args.resume:
if args.resume.startswith('https'):
checkpoint = torch.hub.load_state_dict_from_url(
args.resume, map_location='cpu', check_hash=True)
else:
checkpoint = torch.load(args.resume, map_location='cpu')
if checkpoint['model']['head.weight'].shape[0] != 100 and checkpoint['model']['head.weight'].shape[1] == 768:
checkpoint['model']['head.weight'] = torch.nn.Parameter(torch.nn.init.xavier_uniform(torch.empty(100,768)))
checkpoint['model']['head.bias'] = torch.nn.Parameter(torch.randn(100))
else:
checkpoint['model']['head.weight'] = torch.nn.Parameter(torch.nn.init.xavier_uniform(torch.empty(100,1024)))
checkpoint['model']['head.bias'] = torch.nn.Parameter(torch.randn(100))
model_without_ddp.load_state_dict(checkpoint['model'])
print("Resume checkpoint %s" % args.resume)
开启训练(单GPU)
注意:batch_size的计算 nproc_per_nodebatch_sizeupdate_freq = batch_size所以如果显存不大,最好三者设置的合理些。 我的 resume 的模型 和 data_path均在 main.py中配置了,所以这里没有体现
python -m torch.distributed.launch --nproc_per_node=1 main.py --model convnext_tiny --drop_path 0.1 --batch_size 8 --lr 4e-3 --update_freq 1 --model_ema true --model_ema_eval true --output_dir ./save_results
希望可以帮到您!