GCN图卷积网络
GCN全称graph convolutional networks.图卷积网络,提出于2017年。GCN的出现标志着图神经网络的出现。深度学习最常用的网络结构就是CNN,RNN,GCN与CNN不仅名字相似,其实理解起来也很类似,都是特征提取器。不同的是,CNN提取的是张量数据特征,而GCN提出的是图结构数据特征。
1.计算过程
初期研究者为了从数学上严谨的推导GCN公式是有效的,所以会涉及到诸如傅里叶变换,拉普拉斯算子的知识。其实对于我们使用者而言,我们可以绕开那些知识并且毫无影响的理解GCN。
以下就是GCN网络层的基础公式。
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) w ( l ) ) H^{(l+1)} = \sigma(\widetilde{D}^{-\frac{1}{2}}\widetilde{A}\widetilde{D}^{-\frac{1}{2}}H^{(l)}w^{(l)}) H(l+1)=σ(D
−21A
D
−21H(l)w(l))
其中 H l H^{l} Hl指第 l l l层的输入特征, H l + 1 H^{l+1} Hl+1自然就是指输出特征。 w l w^l wl指线性变换矩阵。 σ ( ⋅ ) \sigma(·) σ(⋅)是非线性激活函数,如ReLU,Sigmoid等。
那么重点就是那些A和D是什么了。
首先说 A ~ \widetilde{A} A
,通常邻接矩阵用A表示,邻接矩阵中的 A i j A_{ij} Aij就是节点i与节点j之间是否有路径,1为有,0为无。在A头上加个波浪线的 A ~ \widetilde{A} A
叫做“有自连的邻接矩阵”,以下简称自连邻接矩阵。定义如下:
A ~ = A + I \widetilde{A } = A + I A
=A+I
I I I是单位矩阵,A是邻接矩阵。因为我们对于邻接矩阵的定义是矩阵中的值为对应位置节点与节点之间的关系,而节点中对角线的位置是节点与自身的关系。而节点与自身并无边相连,所以邻接矩阵中的对角线自然都为0。但是如果我们接受这一设定进行下游计算,那么就无法在邻接矩阵中区分“自身节点”与“无连接节点”。所以将A加上一个单位矩阵1得到 A ~ \widetilde{A} A
,便能使得对角线为1,就好比添加了自连的设定。

如图所示, A ~ \widetilde{A} A
就是在A的对角线上加上1
D ~ \widetilde{D} D
是自连矩阵的度矩阵,定义如下:
D ~ i i = Σ j A ~ i j \widetilde{D}_{ii}=Σ_j\widetilde{A}_{ij} D
ii=ΣjA
ij
则 D ~ \widetilde{D} D
为:

D ~ i i \widetilde{D}_{ii} D
ii就是第i个节点的邻居个数+1
所以:
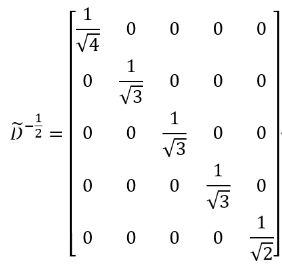
D ~ − 1 2 \widetilde{D}^{-\frac{1}{2}} D
−21就是在自连度矩阵的基础上开平方根取逆。求矩阵的平方根和逆的过程其实很复杂,好在 D ~ \widetilde{D} D
只是一个对角矩阵,所以在这我们直接可以通过给每个元素开根取倒数的方式得到 D ~ − 1 2 \widetilde{D}^{-\frac{1}{2}} D
−21。无向无权图中,度矩阵描述的就是节点度的数量;若是有向图,则是出度的数量;若是有权图,则是目标节点与每个邻居连接边的权重和。而自连度矩阵,就是在度矩阵的基础上加个单位矩阵也就是每个节点度的数量加1。
所以GCN公式( H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) w ( l ) ) H^{(l+1)} = \sigma(\widetilde{D}^{-\frac{1}{2}}\widetilde{A}\widetilde{D}^{-\frac{1}{2}}H^{(l)}w^{(l)}) H(l+1)=σ(D
−21A
D
−21H(l)w(l)))中,
D ~ − 1 2 A ~ D ~ − 1 2 \widetilde{D}^{-\frac{1}{2}}\widetilde{A}\widetilde{D}^{-\frac{1}{2}} D
−21A
D
−21这些其实都是从邻接矩阵计算过来的,我们甚至可以把这些看做一个常量。模型需要学习的仅仅是 w ( l ) w^{(l)} w(l)这个权重矩阵。我们懂得这个公式,那么只需构建一个图,统计出邻接矩阵,直接代入公式即可实现GCN网络。
2.公式原理
为了更好地理解上述公式的含义,比如为什么要引入 D ~ \widetilde{D} D
、为什么要对 D ~ \widetilde{D} D
取 − 1 2 -\frac{1}{2} −21次方而不是 1 2 \frac{1}{2} 21次方,下面将对上述公式进行详细解释
首先我们可以考虑将公式进行简化,即
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) w ( l ) ) = σ ( A ~ H ( l ) w ( l ) ) H^{(l+1)} = \sigma(\widetilde{D}^{-\frac{1}{2}}\widetilde{A}\widetilde{D}^{-\frac{1}{2}}H^{(l)}w^{(l)})= \sigma(\widetilde{A}H^{(l)}w^{(l)}) H(l+1)=σ(D
−21A
D
−21H(l)w(l))=σ(A
H(l)w(l))
对于 A ~ H ( l ) \widetilde{A}H^{(l)} A
H(l)

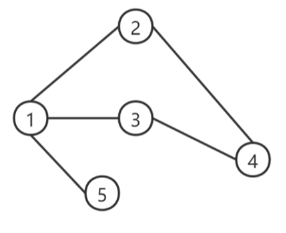
如上图所示,在自连邻接矩阵满足上图的数据场景时,下一层第一个节点的向量表示就是当前层节点h1,h2,h3,h4这些节点向量表示的和, 这一过程的可视化意义如下图所示:

这其实是一个消息传递的过程,经这样消息传递的操作后,下一层的节点1就聚集了它一阶邻居与自身的信息。这就很有效的保留了图结构给我们承载的信息。 到这里我们就理解了 A ~ H ( l ) \widetilde{A}H^{(l)} A
H(l)的含义,即聚合周围节点的信息,来更新自己。
但是简单的聚合似乎不太合理,因为不同的节点重要性不一样,如果一个节点的「度」非常大,即与他相邻的节点非常多,那么它传递的消息,权重就应该小一点。这其实很好理解,比如保险经理张三的好友有2000个,当然你也是其中一个;而你幼时的青梅竹马小红加上你仅有10个好友。那么张三与小红对于定义你的权重自然就不该一样。我们来看度矩阵D在这起到的作用,我们知道节点的度代表着它一阶邻居的数量,所以乘以度矩阵的逆也就是稀释掉度很大的节点的重要度。
D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) \widetilde{D}^{-\frac{1}{2}}\widetilde{A}\widetilde{D}^{-\frac{1}{2}}H^{(l)} D
−21A
D
−21H(l)这一计算的可视化意义如下:

这就像是一个加权求和操作,度越大权重就越低。图中每条边权重分母左边的 4 \sqrt4 4是节点1自身度的逆平方根。
上述就是GCN公式的计算意义,我们也可结合具体场景自定义消息传递的计算方式。图神经网络之所以有效,就是因为它很好的利用了图结构的信息。它的起点就是别人的终点。本身无监督统计图数据信息已经可以给我们的预测带来很高的准确率。此时只需要一点少量的标注数据进行有监督的训练就可以媲美大数据训练的神经网络模型。