ABBYY FineReader PDF是一款文本处理软件,其强大的OCR文字识别功能可以轻松准确地识别PDF文档和图片,并且对抓取出的文字、图像、表格和超链接进行编辑,支持将PDF和图片直接转换为pdf、word、excel或rtf、odt、ppt等不同格式的文档。

在翻译实践过程中,我们会遇到各种各样的文档格式。有些文档可以直接进行检索、编辑,然而有些文档是扫描件,无法直接检索、编辑文档内容,给文字处理带来了不少麻烦。不知大家有没有遇到过这种“棘手”的情况呢?小编曾面对不可编辑的文档抓耳挠腮,不知如何是好。直到遇见了它——ABBYY FineReader PDF。
工具简介:
ABBYY FineReader PDF助力专业人士最大程度提高数字化工作场所中的效率。FineReader PDF采用ABBYY最新推出的基于AI的OCR(Optical Character Recognition) 光学字符识别技术,可以更轻松地对各种文档进行数字化、检索、编辑等处理。因此,信息工作者可以将更多的时间和精力投入到各自的专业领域。

ABBYY Finereader 15 Win-安装包下载:
https://wm.makeding.com/iclk/?zoneid=50027
主要功能
ABBYY FineReader PDF功能十分强大,其中包括编辑和整理PDF、协作和批准PDF、保护和签署 PDF、将PDF转换为Excel、Word等格式、使用OCR对纸质文档和扫描件进行数字化处理等等。本期分享将着重介绍ABBYY FineReader PDF的OCR(光学字符识别)功能。跟着小编一起操作哟~
OCR功能
1)首先,先打开ABBYY FineReader PDF,在界面中选择“在ORC编辑器中打开”。
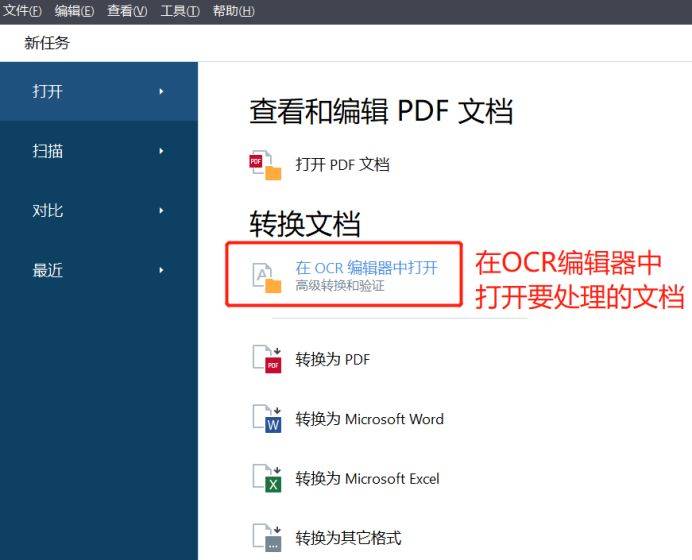
2)用ORC编辑器打开文档时,可进行预处理,即根据需求选择识别整个文档,或文档中的部分页面,以此提高文档识别的效率与精准度。

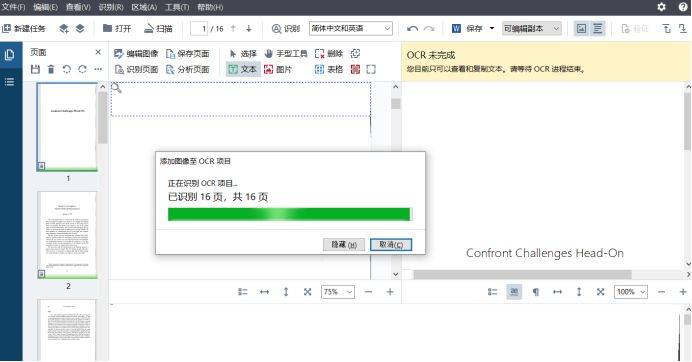
3)选定需要识别的页面之后,ORC编辑器就开始识别啦!只需稍等片刻,它便能自动将扫描件、PDF等文件识别出来。
4)识别完成后,页面呈现四个不同的区域,分别为:页面缩图预览、扫描框内文字预览、OCR识别前、OCR识别后。
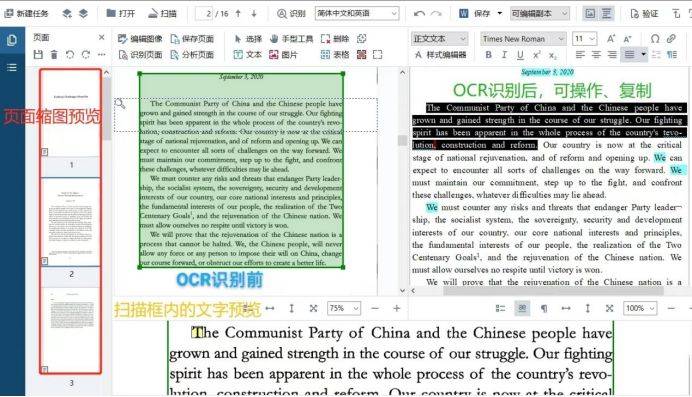
5)最后,就能根据需求提取扫描框内的文字、保存为多种格式的文档啦~

这么实用的文档处理小工具相信大家很快就上手啦!快跟小编一起运用工具,为翻译实践赋能吧!