Python基础—文件操作(二)
CSV格式文件
逗号分隔值,以纯文本形式存储表格数据
由任意数目的记录组成,记录间以换行符分隔
每条记录由字段组成,字段间用逗号或制表符分隔
每条记录都有同样的字段序列
如有列名,位于文件第一行
每条记录数据不跨行,无空行

读CSV文件
年,制造商,型号,说明,价值
1997,Ford,E350,"ac, abs, moon",3000.00
1999,Chevy,"Venture""ExtendedEdition""","",4900.00
1999,Chevy,"Venture ""Extended Edition, Very Large""","",5000.00
1996,Jeep,Grand Cherokee,"MUST SELL! \nair, moon roof, loaded",4799.00
CSV文件中的数据基本上都是行和列构成的二维数据
可以使用二维列表的方法对其进行处理
CSV文件“score.csv”:
姓名,C,Java,Python,C#
罗明,95,96,85,63
朱佳,75,93,66,85
李思,86,76,96,93
郑君,88,98,76,90
王雪,99,96,91,88
李立,82,66,100,77
with open('8.2 score.csv', 'r', encoding='utf-8') as csv_obj:
data_lst = []
for line in csv_obj:
data_lst.append(line.strip().split(','))
print(data_lst)
姓名,C,Java,Python,C#
罗明,95,96,85,63
朱佳,75,93,66,85
李思,86,76,96,93
郑君,88,98,76,90
王雪,99,96,91,88
李立,82,66,100,77
[['姓名', 'C', 'Java', 'Python', 'C#'],
['罗明', '95', '96', '85', '63'],
['朱佳', '75', '93', '66', '85'],
['李思', '86', '76', '96', '93'],
['郑君', '88', '98', '76', '90'],
['王雪', '99', '96', '91', '88'],
['李立', '82', '66', '100', '77']]
def read_csv(filename):
"""
接收csv格式文件名为参数,根据逗号将每行切分为一个列表。
每行数据做为二维列表的一个元素,返回二维列表。
"""
return data_lst
with open(filename, 'r', encoding='utf-8') as csv_obj:
data_lst = [line.strip().split(',') for line in csv_obj]
if __name__ == '__main__':
file = '8.2 score.csv' # 定义文件名变量,方便程序扩展和修改
data = read_csv(file) # 读文件转为二维列表
print(data)
# 输出列表
写CSV文件
def write_file(ls, new_file):
"""
接收一个二维列表和一个表示文件名的字符串为参数,
将二维列表中的列表元素中的数据拼接在一起写入文件中,
每写入一组数据加一个换行符。
"""
with open(new_file, 'w', encoding='utf-8') as file: # 写模式
for x in ls:
file.writelines(','.join(x) + '\n')
if __name__ == '__main__':
data = [['姓名', 'C', …], …, ['李立', '82', '66', '100', '77’]]
file = 'score_new.csv’
write_file(data, file)
JSON文件
JSON 是一种跨语言的轻量级通用数据交换格式
JSON是文本格式,键必须用双引号,字符串类型
'
{
"name": "李立",
"phone": "13988776655",
"city": "武汉"
}'
dumps()
load()
内置json库,用于对JSON数据的解析和编码
JSON编码
将Python对象转为JSON格式数据
json.dumps(obj, ensure_ascii=True, indent=None, sort_keys=False)
json.dump(obj,fp, ensure_ascii=True, indent=None,sort_keys=False)
dump(obj, fp) 将“obj”转换为JSON 格式的字符串
将字符串写入到文件对象fp中
json.dumps(obj, ensure_ascii=True, indent=None, sort_keys=False)
import json
默认ensure_ascii=True,会将中文等非ASCII 字符转为unicode编码
设置ensure_ascii=False 可以保持中文原样输出
info = {
'name':'李立', 'phone':'13988776655', 'city':'武汉'}
{
"name": "\u674e\u7acb", "phone": "13988776655", "city": "\u6b66\u6c49"}
print(json.dumps(info, ensure_ascii=False))
{
"name": "李立", "phone": "13988776655", "city": "武汉"}
print(json.dumps(info))
json.dumps(obj, ensure_ascii=True, indent=None, sort_keys=False)
indent 参数可用来对JSON 数据进行格式化输出,默认值为None
可设一个大于0 的整数表示缩进量,可读性更好
{
"name": "李立",
"phone": "13988776655",
"city": "武汉"
}
print(json.dumps(info, ensure_ascii=False, indent=4))
import json
info = {
'name':'李立', 'phone':'13988776655', 'city':'武汉'}
json.dumps(obj, ensure_ascii=True, indent=None, sort_keys=False)
默认不排序
可设置sort_keys=True使转换结果按照字典升序排序
{
"name": "李立",
"phone": "13988776655",
"city": "武汉"
}
print(json.dumps(info,ensure_ascii=False,indent=4,sort_keys=True))
{
"city": "武汉",
"name": "李立",
"phone": "13988776655"
}
import json
info = {
'name':'李立', 'phone':'13988776655', 'city':'武汉'}
json.dump(obj,fp, ensure_ascii=True, indent=None,sort_keys=False)
将JSON 数据写入到一个具有写权限的文件对象中
{
"name": "李立",
"phone": "13988776655",
"city": "武汉"
}
print(json.dump(info,ensure_ascii=False,indent=4))
import json
info = {
'name':'李立', 'phone':'13988776655', 'city':'武汉'}
“
test.json” 文件中的数据
文件与文件夹操作
获取当前工作目录
os.getcwd()
返回当前程序工作目录的绝对路径
import os
result = os.getcwd()
print(result)
# F:\weiyun\2020
改变当前工作目录
os.chdir()
改变当前工作目录
import os
# \\'解析为'\','D:/testpath/path'
os.chdir('D:\\testpath\\path')
result = os.getcwd()
print(result)
# D:\testpath\path
获取文件名称列表
os.listdir()
获取指定文件夹中所有文件和文件夹的名称列表
import os
result = os.listdir('E:/股票数据/data')
print(result)
['600000.csv', '600006.csv', '600007.csv', '600008.csv',
'600009.csv',
'600010.csv', …… , '688399.csv']
创建文件夹
os.mkdir()创建文件夹
os.makedirs()递归创建文件夹
import os
os.mkdir('score')
os.makedirs('score/python/final')
删除空目录
os.rmdir()
删除空目录
os.removedirs()递归删除空目录
import os
os.rmdir('score')
os.removedirs('score/python/final/')
文件重命名与删除
os.rename(oldname, newname)文件更名
os.remove(filename)
删除文件
os.path.exists(filename)
检测存在性
import os
if os.path.exists('XRD.txt'):
os.rename('XRD.txt', 'xrd.txt')
print('XRD.txt更名成功')
os.remove('xrd.txt')
print('xrd.txt已经被删除')
else:
print('XRD.txt不存在')
检测文件并读取数据
from os import path
def read_csv(filename):
with open(filename, 'r', encoding='GBK') as csv_obj:
data_lst = [line.strip().split(',') for line in csv_obj]
return data_lst
def check_path(filepath, filename):
if path.exists(filepath) and path.exists(filepath + filename):
return read_csv(filepath + filename)
else:
return '路径或文件名不存在'
if __name__ == "__main__":
data_path = 'E:/股票数据/data/'
data_file = '600009.csv'
data = check_path(data_path, data_file)
print(data)
NumPy(Numerical Python )
单一数据类型的多维数组ndarray
对数组快速处理的通用函数ufunc

numpy.genfromtxt()
从文本文件中获取数据
并提供缺失值处理等更复杂的操作
numpy.genfromtxt(fname, dtype=<class 'float'>, comments='#',
delimiter=None,
skip_header=0,skip_footer=0, missing_values=None,
filling_values=None, usecols=None, autostrip=False,
max_rows=None, encoding='bytes'…)
numpy.loadtxt(fname, dtype=<class 'float'>, comments='#',
delimiter=None,
converters=None,
skiprows=0, usecols=None,
unpack=False, ndmin=0,
encoding='bytes',max_rows=None)
文件“8.5 score.csv” 保存学生成绩数据,其数据部分包括
整数、浮点数和缺失数据(郑君C 语言和VB 成绩缺失)
姓名,学号,C语言,Java,Python,VB,C++,总分
朱佳,0121701100511,75.2,93,66,85,88,407
李思,0121701100513,86, 76,96,93,67,418
郑君,0121701100514,, 98,76,,89,263
王雪,0121701100515,99, 96,91,88,86,460
罗明,0121701100510,95,96,85,63,91,430
fname:文件、字符串、字符序列或生成器
dtype:生成数组的数据类型,默认值是float,str表示字符串
numpy.genfromtxt()
import numpy as np
file = '8.5 score.csv'
data = np.genfromtxt(file, dtype=str, delimiter=',', encoding='utf-8')
print(data)
[['姓名' '学号' 'C语言' 'Java' 'Python' 'VB' 'C++' '总分']
['朱佳' '0121701100511' '75.2' '93' '66' '85' '88' '407']
['李思' '0121701100513' '86' ' 76' '96' '93' '67' '418']
['郑君' '0121701100514' '' ' 98' '76' '' '89' '263']
['王雪' '0121701100515' '99' ' 96' '91' '88' '86' '460']
['罗明' '0121701100510' '95' '96' '85' '63' '91' '430']]
delimiter:用于定义如何拆分数据行,默认用空白字符分隔
skip_header:在文件开头跳过的行数,缺省值为skip_header=0
dtype=None 时,每个列的类型从每行的各列数据中迭代确定
import numpy as np
file = '8.5 score.csv'
data = np.genfromtxt(file,dtype=None,delimiter=',',skip_header=1,encoding='utf-8')
print(data)
[('朱佳', 121701100511, 75.2, 93, 66, 85, 88, 407)
('李思', 121701100513, 86. , 76, 96, 93, 67, 418)
('郑君', 121701100514, nan, 98, 76, -1, 89, 263)
('王雪', 121701100515, 99. , 96, 91, 88, 86, 460)
('罗明', 121701100510, 95. , 96, 85, 63, 91, 430)]
filling_values:用设置的值做作为默认值替代缺失数据
import numpy as np
file = '8.5 score.csv'
data = np.genfromtxt(file, dtype=None, delimiter=',', filling_values=0, skip_header=1, encoding='utf-8')
print(data)
[('朱佳', 121701100511, 75.2, 93, 66, 85, 88, 407)
('李思', 121701100513, 86. , 76, 96, 93, 67, 418)
('郑君', 121701100514, 0. , 98, 76, 0, 89, 263)
('王雪', 121701100515, 99. , 96, 91, 88, 86, 460)
('罗明', 121701100510, 95. , 96, 85, 63, 91, 430)]
names:值为None、True、字符串或序列之一
值为“True”时,跳过skip_header行数后读取的第1行作为字段名
import numpy as np
file = '8.5 score.csv'
data = np.genfromtxt(file, dtype=None, delimiter=',', names=True, filling_values=0, encoding='utf-8')
print(data[['姓名', '学号', 'Python']]) # 以多个字段为索引时,放入列表中
[('朱佳', 121701100511, 66)
('李思', 121701100513, 96)
('郑君', 121701100514, 76)
('王雪', 121701100515, 91)
('罗明', 121701100510, 85)]
ufunc函数
通用函数,是对数组的每个元素进行运算的函数
数组的运算可以用运算函数,也可以写为数组运算表达式
import numpy as np
a = np.array((1, 2, 3, 4, 5)) # 数组[ 1 2 3 4 5]
b = np.array((6, 7, 8, 9, 10)) # 数组[ 6 7 8 9 10]
print(np.add(a, b))
# 输出[ 7 9 11 13 15]
print(a + b)
# 输出[ 7 9 11 13 15]
[ 7 9 11 13 15]
[ 7 9 11 13 15]

内置随机数函数、三角函数、双曲函数、指数和对数函数、算术运
算、复数处理和统计等近百种数学函数,快速对数据进行各种运算
import numpy as np
a = np.array((1, 2, 3, 4)) # 将元组转换为数组[1 2 3 4]
print(np.sum(a))
# 数组元素求和,输出10
print(a ** 2)
# 数组每个元素平方,[ 1 4 9 16]
print(a % 3)
# 数组每个元素对3 取模,[1 2 0 1]
print(np.sqrt(a)) # 开方[1. 1.41421356 1.73205081 2. ]
print(np.square(a)) # 每个元素2次方的数组,[ 1 4 9 16]
统计分析
数字型特征的描述性统计主要包括计算数字型数据的完整情况、最
小值、最大值、均值、中位数、极差、标准差、方差和协方差等
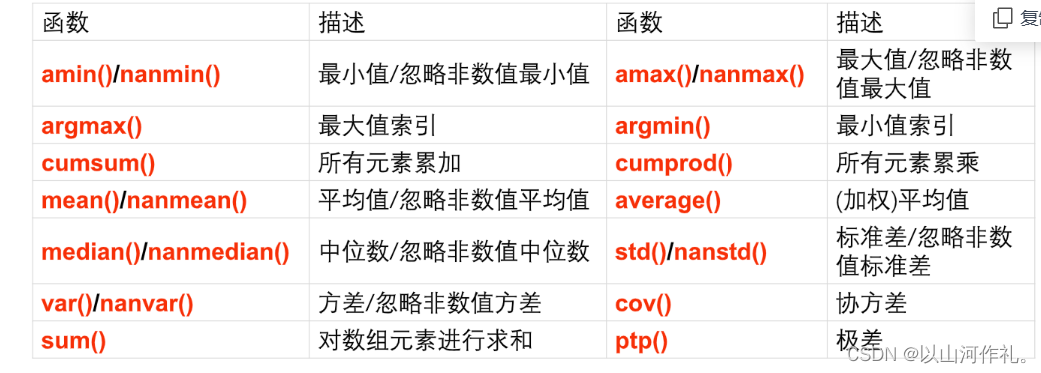
数字型特征的描述性统计主要包括计算数字型数据的完整情况、最
小值、最大值、均值、中位数、极差、标准差、方差和协方差等
import numpy as np
arr = np.random.randint(100, size=(3, 4))
print(np.max(arr), np.argmax(arr)) # 数组最大值及位置序号,输出98 2
print(np.cumsum(arr)) # 数组元素逐个累加,[ 35 92 190 287 314 378 460 536 565 656 711 808]
print(np.mean(arr)) # 返回平均值,输出67.33333333333333
print(np.median(arr)) # 返回中位数,输出70.0
数组切片
读文件返回数组,切片应用
data[行索引或切片,列索引或切片]
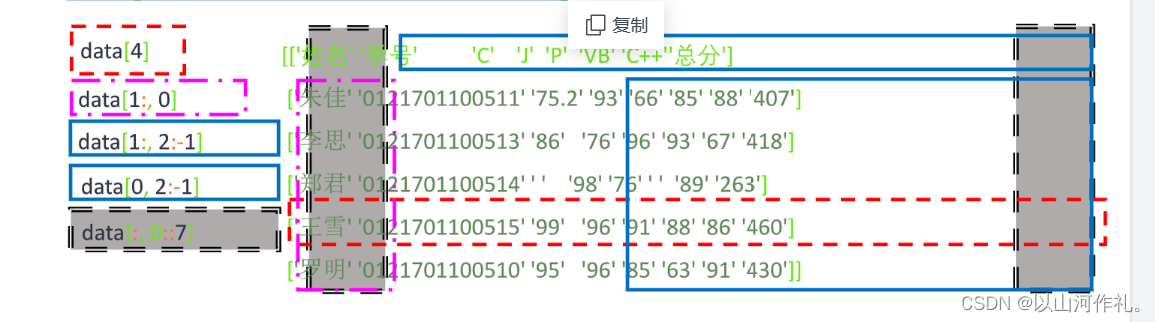
import numpy as np
file = '8.5 score.csv'
data = np.genfromtxt(file, dtype=str, delimiter=',', encoding='utf-8')
print(data[0]) # ['姓名' '学号' 'C语言' 'Java' 'Python' 'VB' 'C++' '总分']
print(data[1:, 0]) # ['朱佳' '李思' '郑君' '王雪' '罗明']
print(data[0, 2:-1]) # ['C语言' 'Java' 'Python' 'VB' 'C++']
print(data[1:, 2:-1])
print(data[:, 0::7])
[['75.2' '93' '66' '85' '88']
['86' ' 76' '96' '93' '67']
[' ' ' 98' '76' ' ' '89']
['99' ' 96' '91' '88' '86']
['95' '96' '85' '63' '91']]
[['姓名' '总分']
['朱佳' '407']
['李思' '418']
['郑君' '263']
['王雪' '460']
['罗明' '430']]
悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。