嗨,又来爬图片来了,发现了一个算宝藏的网站,打算爬一波情侣头。
首先来测试一下,先抓包。F12,就不教了,看图:
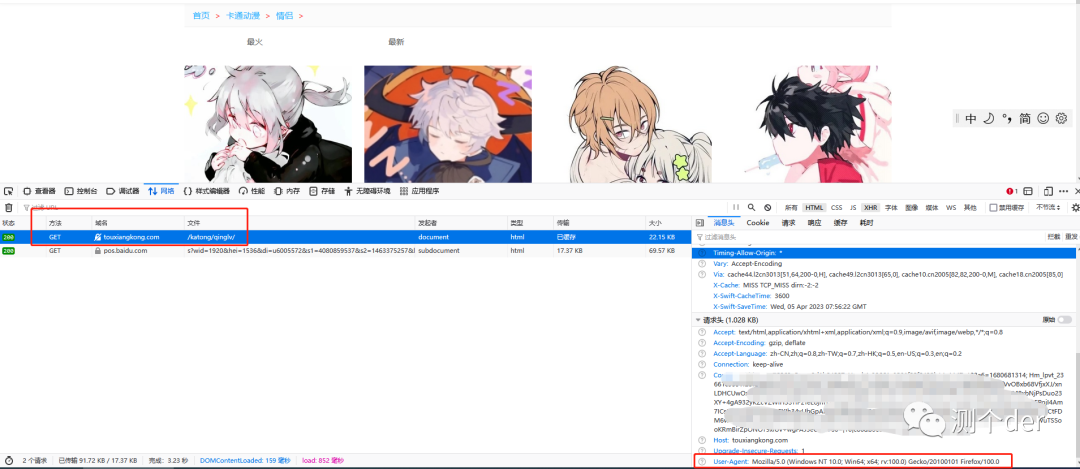
Get请求,URL地址也给到了,header的User-Agent也看到了,这类网上很多,随意百度也行。
接下来找里面的一张图片地址,例如:http://img.touxiangkong.com/uploads/allimg/2023030410/2yknchwxmew.jpg
浅浅的测试一下,能不难爬。
import requests
jpg_url = 'http://img.touxiangkong.com/uploads/allimg/2023030410/2yknchwxmew.jpg'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
}
result = requests.get(url=jpg_url, headers=headers).content
with open('11.jpg','wb') as w:
w.write(result)不出意外的意外,是没有意外的,下载成了。(如果有gbk或者其他的编码无法解码,可以直接修改pycharm里面的setting里面的encoding编码。或者指定result.encoding='utf-8')
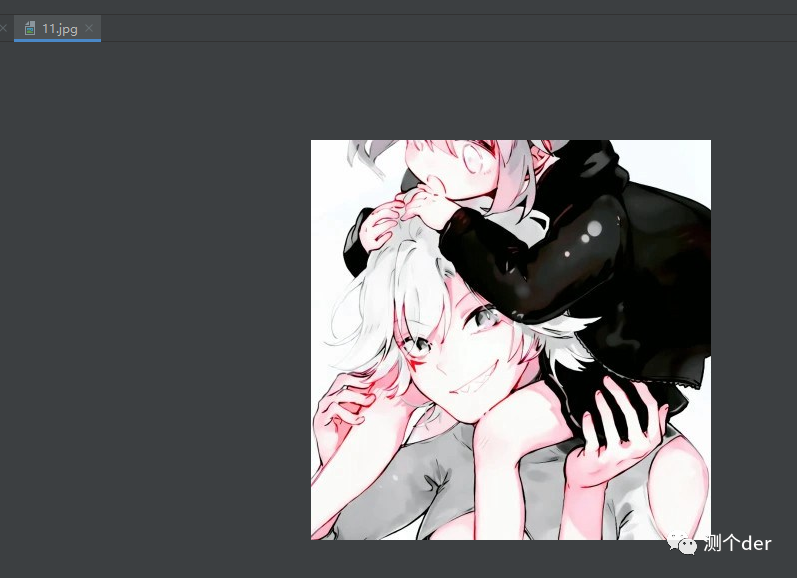
接下来分析一下,如何爬取:
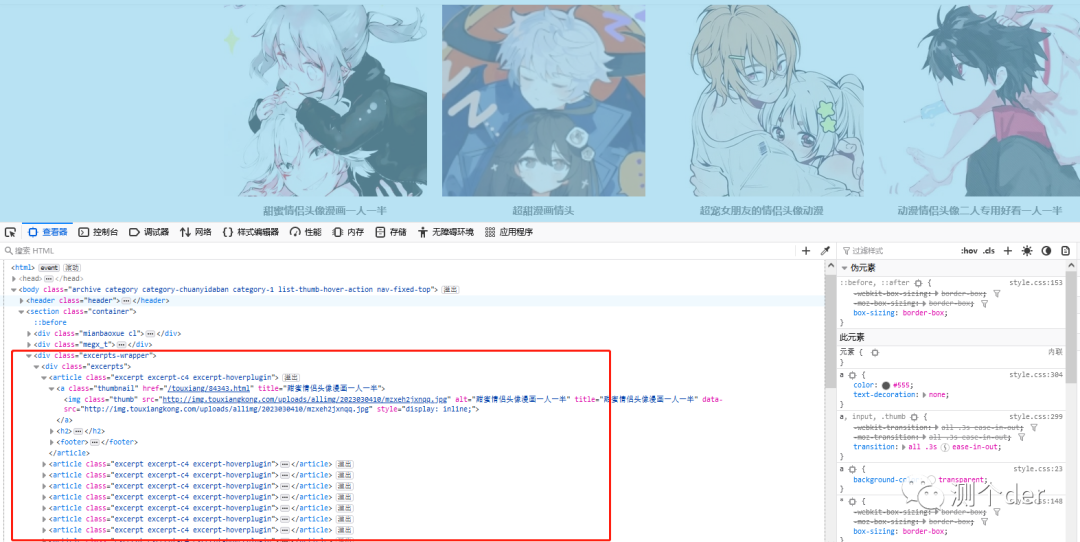
看到了吗,画框的全部都是,今天要全部下载吗?不,我不想,但是你可以。
先把里面的url全部拿出来。
我们使用xpath。别问为什么,想用啥用啥。bs4也行,selenium也可以。
先请求一下网站
url = 'http://touxiangkong.com/katong/qinglv/'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
}
result = requests.get(url=url, headers=headers).content.decode('utf-8')
print(result)然后根据信息获取关键url(有些博主是直接在网页端看的,都可以--CTRL+U即可)
 很明显,我们直接锁定这一块,实在看不懂的,学一下HTML,再不行,直接看最后,拿代码跑吧。
很明显,我们直接锁定这一块,实在看不懂的,学一下HTML,再不行,直接看最后,拿代码跑吧。
import requests
from lxml import etree
url = 'http://touxiangkong.com/katong/qinglv/'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
}
result = requests.get(url=url, headers=headers)
result.encoding = 'utf-8'
html = etree.HTML(result.text)
get_html_href = html.xpath('//*[@class="excerpts-wrapper"]/div/article/a/@href')
print(get_html_href)到了这里,我们就把http://touxiangkong.com/katong/qinglv下的所有的情侣头像网页地址拿到了。可以看到第一个就是我们上面请求的网页,也就是/touxiang/84343.html。
「其实这还有第二页,第三页...这里就不演示了,怎么样获取,gitee上很多就给到了示例,可以直接去看看」
我们把第一页的前三个搞到手。还是一样的操作,点进去,然后CTRL+U,看源码获取链接。
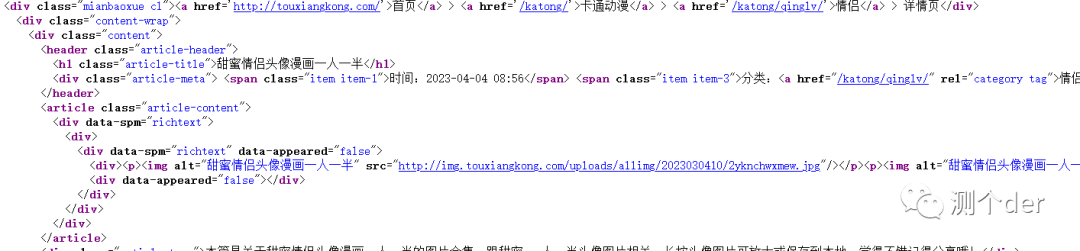 也就是这一段了。拿到它,先请求。
也就是这一段了。拿到它,先请求。
import requests
from lxml import etree
url = 'http://touxiangkong.com/katong/qinglv/'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
}
result = requests.get(url=url, headers=headers)
result.encoding = 'utf-8'
html = etree.HTML(result.text)
get_html_href = html.xpath('//*[@class="excerpts-wrapper"]/div/article/a/@href')
index = 'http://touxiangkong.com/touxiang/'
for other_url in get_html_href[:3]:
index_url = index + other_url
print(index_url)
"""
http://touxiangkong.com/touxiang/84343.html
http://touxiangkong.com/touxiang/84340.html
http://touxiangkong.com/touxiang/84174.html
"""这样也就拿到了前三个网页的url了,还是需要分析。
「点进去84343.html的网页后你会发现网址是:http://touxiangkong.com/touxiang/84343.html。所以不用想也知道,需要组合起来。」
接下来请求这些地址,拿到text。然后获取到他们的url
import requests
from lxml import etree
url = 'http://touxiangkong.com/katong/qinglv/'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
}
result = requests.get(url=url, headers=headers)
result.encoding = 'utf-8'
html = etree.HTML(result.text)
get_html_href = html.xpath('//*[@class="excerpts-wrapper"]/div/article/a/@href')
index = 'http://touxiangkong.com'
url_list = []
for other_url in get_html_href[:3]:
index_url = index + other_url
url_list.append(index_url)
for html_value in url_list:
other_result = requests.get(url=html_value, headers=headers)
other_result.encoding = 'utf-8'
other_html = etree.HTML(other_result.text)
get_other_href = other_html.xpath('//*[@class="content-wrap"]/div/article/div/div/div/div/p/img/@src')
print(get_other_href)别问我的xpath为什么这么写,太low了。你想!
获取到全部的url后,就可以开始下载了,最后还剩下一个问题,就是名称问题了,没办法,因为网址这边没有可以获取的名称,所以我们随意点。
数字命名,最后看看完整,没有封装的代码:
import requests
from lxml import etree
url = 'http://touxiangkong.com/katong/qinglv/'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
}
result = requests.get(url=url, headers=headers)
result.encoding = 'utf-8'
html = etree.HTML(result.text)
get_html_href = html.xpath('//*[@class="excerpts-wrapper"]/div/article/a/@href')
index = 'http://touxiangkong.com'
url_list = []
for other_url in get_html_href[:3]:
index_url = index + other_url
url_list.append(index_url)
for html_value in url_list:
other_result = requests.get(url=html_value, headers=headers)
other_result.encoding = 'utf-8'
other_html = etree.HTML(other_result.text)
get_other_href = other_html.xpath('//*[@class="content-wrap"]/div/article/div/div/div/div/p/img/@src')
num = 0
for img_url in get_other_href:
img_request = requests.get(url=img_url, headers=headers).content
with open(f'情头{num}.jpg','wb') as w:
w.write(img_request)
num += 1最后效果呈现:
最终封装源码地址:https://gitee.com/qinganan_admin/reptile-case.git