一、相关概念
1、什么是跨域?
跨域又称为跨源,是指在违反了浏览器的同源政策,也就是协议、域名和端口号三者不完全一致的情况下产生的。只要客户端与浏览器的三者有一项不同,就属于不同源,就会产生跨域。
很多初级开发者有一种错误的认知:只有ajax请求才会产生跨域。但其实这是一种很片面的想法,因为浏览器的同源政策不仅限制了ajax请求,同时还限制了图片、字体、css、音视频文件、iframe等其他诸多互联网资源,只是各自被限制后的行为表现有所不同而已。
2、什么是跨站?
与跨域类似的,还有一个跨站的概念,跨站仅仅是指域名不同的情况(包括顶级域名和二级域名),所以它与跨域其实是一种包含关系:跨站一定会跨域,但跨域不一定会跨站。
例如:从f1.a.com中向f2.a.com发起ajax请求会构成跨域,但不构成跨站,因为两者的域名相同;而从f1.a.com向f1.b.com发出的请求构成跨站,同时也是跨域,因为两者的二级域名不同。
3、什么是域名?
域名是互联网上某一台计算机的名称,由一串通过.进行连接的字符串组成,用于在进行数据传输时标识对应的计算机的电子方位。而且域名其实是IP地址的一种代称,当我们使用域名去访问某个网站时,互联网会通过DNS 去查找对应的IP地址,然后才能访问到对应的计算机。
域名本身具有一套很复杂的命名规则,在此我们就不过多赘述了,其格式大约为[三级域名].二级域名.顶级域名,我们以www.three.two.com为例,进行简单了解,其中.com是顶级域名,.two是二级域名,.three是三级域名,而www则是主机名。
二、相关理解
1、跨域存在的意义
我们讲了这么多的跨域的解决方案,但我们不得不思考这样一个问题:浏览器为什么要设置这么一道障碍?几乎所有人都知道答案,那就是为了安全。可这个安全是为了谁?
有人说是为了浏览器的安全,避免恶意脚本的执行,对客户端造成损害,但这是片面的。
也有人说是为了服务端的安全,避免服务器被攻击,但通过抓包可以发现,当出现跨域时,其实服务端的数据已经完整返回了,也就是说其实服务器对于跨域并不知情,所以这种说法也是片面的。
其实跨域真正的意义是为了保护数据资源的安全,例如:图片、字体、音视频、css、js等等。也就是说:我们可以通过跨域,去决定我们的私有资源对于哪些应用是开放的,对于那些资源是禁止访问的。
以生活中的例子来说:资源是超市货架上的物品,任何用户都可以进入超市,是不被拦截的。但是出门的时候,如果你没有付款,商品是会被拦截的。收银员这时候就相当于浏览器的角色,对商品和用户进行校验,只有用户付款之后,有了权限,才能让用户拿着商品离开,否则人离开,商品留下,也就是产生跨域了。
2、跨域的几种解决方案
请转看我的这一篇博客:同源政策和跨域解决方案
3、当请求跨域时,怎样才能携带相关凭据?
当ajax请求发生跨域时,就算通过上面的某种方式解决了跨域,但是该请求默认还是不会携带相关凭据的(如:cookie、SSL证书、HTTP认证信息等)。但某些场景下我们是需要这些凭据的。
想要解决这个问题我们需要客户端和服务端共同配合,客户端需要设置xhr.withCredentials为true,此时如果是跨域,则会携带所有cookie,如果是跨站,则只会携带samesite=none且设置了Secure属性的cookie(同时还必须是https协议,否则不会生效)。
xhr.withCredentials = true;
Set-Cookie: ***** SameSite=None; Secure
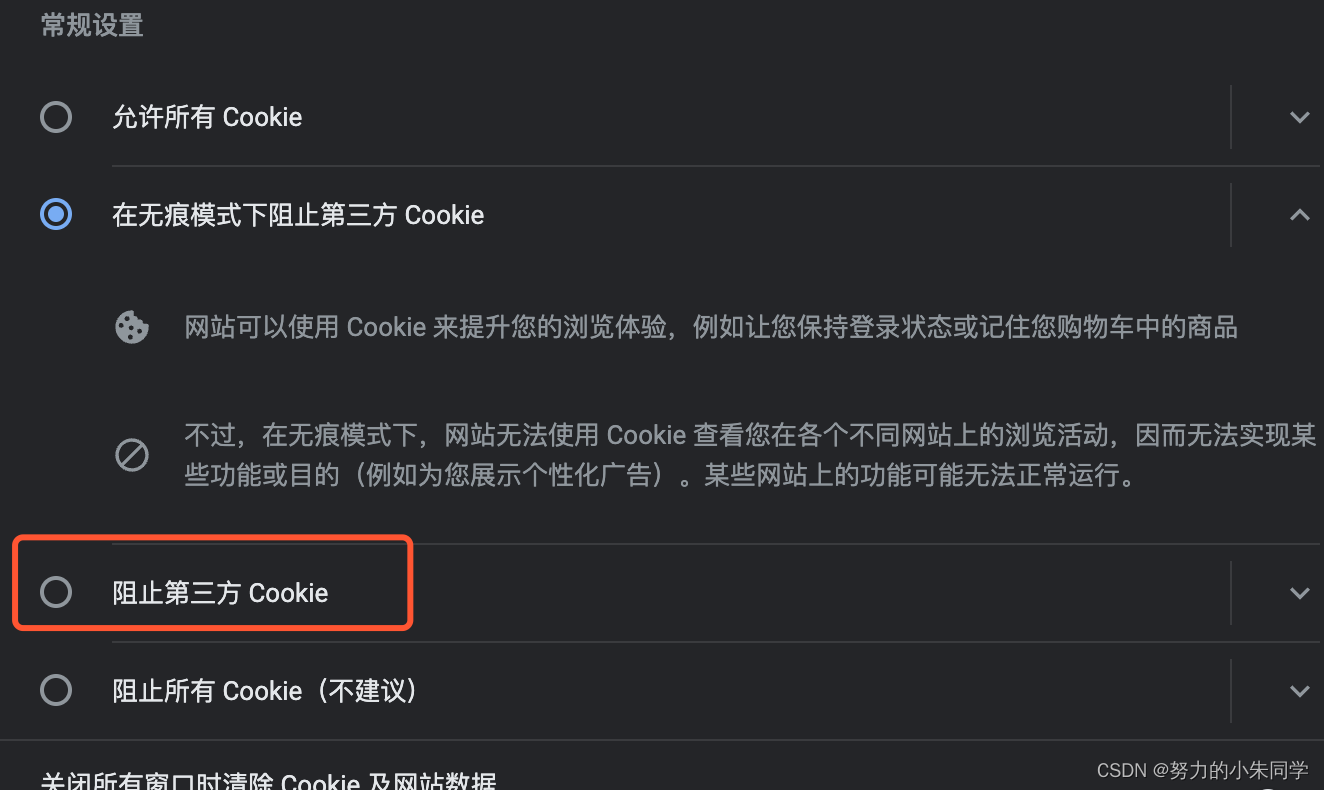
客户端除了代码层面上的设置,还需要检查浏览器的设置,如果浏览器设置了“组织第三方cookie”选项,那么跨域时也无法携带任何cookie(Safari任意模式和Chrome的无痕模式下默认勾选,Chrome正常模式下未勾选)
服务端则需要设置响应头中的Access-Control-Allow-Credentials为 true
// 以nginx为例
add_header Access-Control-Allow-Credentials true;
4、简单请求产生跨域的具体方案
首先我们要搞清一个概念:什么是简单请求?
当一个请求同时满足下面五个条件时,就是一个简单请求:
- ① 请求方式为
get/head/post三者之一。 - ② 除了
user-agent自动设置的头部之外,仅能使用cors安全的头部(请求头)之一:accept,accept-language,content-language,content-type。 - ③
content-type只能是:text/plain,multipart/form-data,application/x-www-form-urlencoded其中之一。 - ④ 请求中的任意
XMLHttpRequest对象均没有注册任何事件监听器;XMLHttpRequest对象可以使用XMLHttpRequest.upload属性访问。 - ⑤ 请求中没有使用
ReadableStream对象。
通常情况下,条件④、⑤不会出现,所以我们主要关注前三条即可。
对于简单请求产生跨域时,我们只需要在服务端设置响应头:Access-Control-Allow-Origin: *(或者具体的origin地址),即可解决跨域问题。
但是当客户端设置请求的xhr.withCredentials = true时,请求会携带凭据,所以Access-Control-Allow-Origin的值就不能设置为 *,必须为具体的origin地址。
//这里可以是变量,也可以是具体写固定的origin
add_header Access-Control-Allow-Origin $http_origin;
5、复杂请求解决跨域的具体方案
知道了简单请求的定义,所以只要不是简单请求,那就一定是复杂请求。常见的几种情况:
- ① 请求方法为
PUT、DELETE等除了HEAD、GET、POST之外方法。 - ② 请求头中的
Content-Type值为application/json。 - ③请求头中有自定义头部,比如我们鉴权经常会使用的“Auth”字段,会常放在请求头中。
复杂请求进行时,分为两步:第一步是客户端发出:options请求(预检请求,HTTP/1.1),该请求将携带以下的请求头部信息:
// 告诉服务器,接下来将使用什么请求方法
Access-Control-Request-Method
// 告诉服务器接下来将携带哪些请求头部(除了user-agent预设的头部之外,通常是自定义头部)
Access-Control-Request-Headers
服务端接收到预检请求之后,会对其进行校验,然后返回以下响应头部信息:
// 告诉客户端允许的请求方法
Access-Control-Allow-Method
// 告诉客户端允许携带的头部(如果有自定义头部,需要在这里列出)
Access-Control-Allow-Headers
// 预检请求的响应结果(Access-Control-Allow-Method和Access-Control-Allow-Headers)的缓存时间,不能超过浏览器的默认上限(当前版本Chrome为2小时,firfox24小时)。-1为禁用缓存。
Access-Control-Allow-Max-Age
// 告知哪些头部可以供客户端通过xhr.getResponseHeader获取到,逗号分隔。即使不设置,也不影响跨域请求的完成
Access-Control-Expose-Headers
// 告诉客户端允许的origin,对于复杂请求,不能为通配符*,只能为具体的origin
Access-Control-Allow-Origin
/ 告诉客户端是否允许携带凭据(cookie)
Access-Control-Allow-Credentials
以上的响应头部信息,并不是必须全部返回的,我们可以根据具体情况决定返回那些头部信息:
- ① 只有
Access-Control-Allow-Origin是必须返回的。 - ② 如果没有特殊请求头,可以不返回
Access-Control-Allow-Headers。 - ③ 如果没有携带凭据,可以不返回
Access-Control-Allow-Credentials。
特殊的,当客户端请求携带凭据(withCredentials=true)时,以下三个响应头部的值不能设置为通配符*:
//当XHR请求设置了withCredentials=true,以下头部的值不能为*,需要设置具体的值
// 必须为具体的origin,不然会报错提示不能为*
Access-Control-Allow-Origin
// 必须为具体的header名称,逗号分隔。不会报错提示不能为*,但是不生效
Access-Control-Expose-Headers
// 除了GET、POST、HEAD之外的METHOD名称,逗号分隔。不会报错提示不能为*,但是不生效
Access-Control-Allow-Method
三、几种资源产生跨域后具体表现
1、字体跨域
当a.com试图加载一个b.com下的字体时:
// a.com
@font-face {
font-family: 'my-font';
src: url(http://b.com/Alibaba-PuHuiTi-Regular.ttf);
}
浏览器控制台会抛出下面的跨域错误:


此时我们只需要在字体所在的服务端b.com设置响应头,对a.com进行授权,即可使其正常访问:
add_header Access-Control-Allow-Origin 'http://a.com/';
2、图片的跨域
图片的查看是不会产生跨域的,跨域主要限制的是图片的下载。
当图片是同源时,我们可以通过用a标签结合download属性进行下载:
<a href="//a.xkw.com/1.jpg" download="1.jpg">下载图片</a>
当图片是不同源时,上面的方法只能打开图片,而不会进行下载。此时我们可以结合canvas绘图下载:
//a.com页面
const canvas = document.createElement('canvas')
// 设置画布宽高
canvas.width = '1684'
canvas.height = '1190'
const cxt = canvas.getContext("2d");
const img = new Image();
img.crossOrigin = 'anonymous';
// 图片加载完成后
img.onload = function () {
// 将图片渲染到画布上
cxt.drawImage(img, 0, 0);
// 将画布转化成base64
const image = canvas.toDataURL("image/png")
// 模拟a标签点击下载
const dlLink = document.createElement('a');
dlLink.download = 'testfile';
dlLink.href = image;
document.body.appendChild(dlLink);
dlLink.click();
document.body.removeChild(dlLink);
};
// 设置图片地址
img.src = '//b.com/1.jpg';
这其中最重要的一行代码便是img.crossOrigin = 'anonymous',表示以CORS的方式去请求这个张图片,而且服务端需要设置CORS的响应头:Access-Control-Allow-Origin: https://a.com,如果客户端未设置img.crossOrigin = 'anonymous' 则会报错:

意为污染的画布不可以被导出为base64编码格式,因为上面绘制了跨域的图片。同理,如果服务端未设置相应的响应头,也还是跨域,会报错。
3、JavaScript文件的跨域
虽然JavaScript的执行并不会受到跨域的限制,但如果宿主页面想要捕获到引入的js文件中抛出的异常,此时就需要配置CORS,也就是给<scriot>标签增加crossorigin="anonymous"属性:
<script src="//b.com/b.js" crossorigin="anonymous"></script>
对应的js文件也必须返回对应的CORS响应头:
Access-Control-Allow-Origin: http://a.com或者*
配置完成后,宿主页面可以通过下面的代码获取到完整的异常信息:
window.onerror = function (msg, url, line) {
console.log(msg, url, line);
}