计算机视觉中文件处理的一些脚本文件!
首先一定要明确自己的json格式,把自己的数据集设置为yolo所需要的格式。
#Json文件属性不同,提取信息不同
自己的数据集
文件夹格式
json文件格式
[
{
"Code Name": "A270332XX_00871.jpg",
"Name": "galibi",
"W": "0.564815",
"H": "0.587961",
"File Format": "jpg",
"Cat 1": "27",
"Cat 2": "03",
"Cat 3": "32",
"Cat 4": "xx",
"Annotation Type": "binding",
"Point(x,y)": "0.587963,0.522375",
"Label": "0",
"Serving Size": "xx",
"Camera Angle": "xx",
"Cardinal Angle": "xx",
"Color of Container": "xx",
"Material of Container": "xx",
"Illuminance": "xx"
}
]需要提取的是
照片宽 "W": "0.564815",
照片高 "H": "0.587961",
归一化后的x,y值"Point(x,y)": "0.587963,0.522375", *注意:这里是双引号
标签 "Label": "0",
这里的宽和高WH指的是经过归一化处理的值,所以无需进行归一化处理,直接遍历所有文件的值去保存就可以啦。(大部分文件宽和高为照片原本的宽和高)
上图是 json文件的属性,在下面提取中 会用到这些属性。
下面直接对代码讲解:
因为由于工作需要我只使用到了图片json文件的点坐标和label,因此只提取了points和label属性,大家根据需要可以对相应内容进行添加。
dir_json和dir_tx就是你json文件所在的路径和txt文件生成的路径。
在最后的for循环中就是遍历生成txt以及txt中的具体内容。
实现代码
import json
import os
from pathlib import Path # 递归方式
def json2txt(path_json, path_txt):
with open(path_json, 'r', encoding='gb18030') as path_json:
jsonx = json.load(path_json)
filename = path_txt.split(os.sep)[-1]
with open(path_txt, 'w+') as ftxt:
for shape in jsonx:
xy = shape["Point(x,y)"]
label = shape["Label"]
w = shape["W"]
h = shape["H"]
strxy = ' '
ftxt.writelines(str(label) + strxy + str(xy) + strxy + str(w) + strxy + str(h) + "\n")
# dir_json = r'E:\Acryl\datapro\jsonfileall\**\**.json'
jpath = Path('/workspace/yolo/data/dataset/f001json/')
dir_txt = '/workspace/yolo/data/dataset/f5/txtfile/'
if not os.path.exists(dir_txt):
os.makedirs(dir_txt)
# list_json = os.listdir(str('jsonfileall'))
# print(type(list_json))
# for cnt, json_name in enumerate(list_json):
# print(cnt, json_name)
# 这个方法的作用是将Path对象下的符合pattern(正则表达式、通配符)的所有文件获取到,返回一个生成器,可以通过for遍历或者next去获取详细的文件位置
for p in jpath.rglob("*.json"):
# print('%s :/ "%s"' % (("file" if os.path.isfile(str(p)) else "dir "), str(p)))
#print(p)
# # 这里p不迭代
# # 找到所有带有路径的json文件
# list_json = os.listdir(str(p))
# # with open(list_json, 'r', encoding='utf-8') as path_json:
# # jsonx = json.load(list_json)
# for cnt, json_name in enumerate(list_json):
# print('cnt=%d,name=%s' % (cnt, json_name))
# # path_json = dir_json+json_name
# path_json = jpath + json_name
# path_txt = dir_txt + json_name.replace('.json', '.txt')
# print(path_json, path_txt)
# json2txt(path_json, path_txt)
path_txt = dir_txt + os.sep + str(p).split(os.sep)[-1].replace('.json', '.txt')
# print(p, path_txt)
json2txt(p, path_txt)数据预处理扩展
1.使用pandas库读取文件单一json文件代码(可选择)
#将JSON文件读取为Pandas类型
import pandas as pd
#单一json文件测试
df = pd.read_json('E:\datapro\d1.json')2.测试单个json文件提取所需要的信息,并写入txt文件(可选择)
import json
person_dict = {}
final_dict = "E:\Acryl\datapro\labels\"
#import json file and load the content in person_dict as a dictionary
with open('E:\Acryl\datapro\d1.json') as f:
person_dict=json.load(f)
#get the first list from the json(person_dict)
for data in person_dict:
try:
final_dict = final_dict + ("Label: " + data[str('Label')] + "\n")
final_dict = final_dict + ("Point(x,y):" + data[str('Point(x,y)')] + "\n")
final_dict = final_dict + ("W: " + data[str('W')] + "\n")
final_dict = final_dict + ("H: " + data[str('H')] + "\n")
except:
pass
text_file = open("json_list.txt", "w") # write output as a txt
n = text_file.write(final_dict)
text_file.close()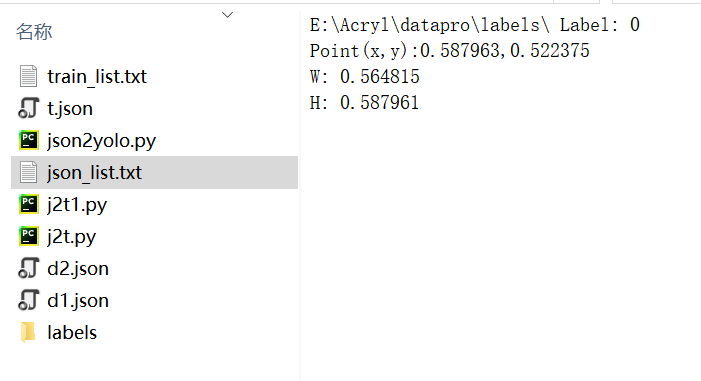
3.YOLO要求的格式: 测试单个json文件提取所需要的信息,并写入txt文件(可选择)
import json
person_dict = {}
final_dict = "E:\Acryl\datapro\labels\ "
#import json file and load the content in person_dict as a dictionary
with open('E:\Acryl\datapro\d1.json') as f:
person_dict=json.load(f)
#get the first list from the json(person_dict)
for data in person_dict:
try:
final_dict =data[str('Label')] +' '+ data[str('Point(x,y)')] +' '+ data[str('W')]+' '+data[str('H')]
except:
pass
text_file = open("json_list.txt", "w") # write output as a txt
n = text_file.write(final_dict)
text_file.close()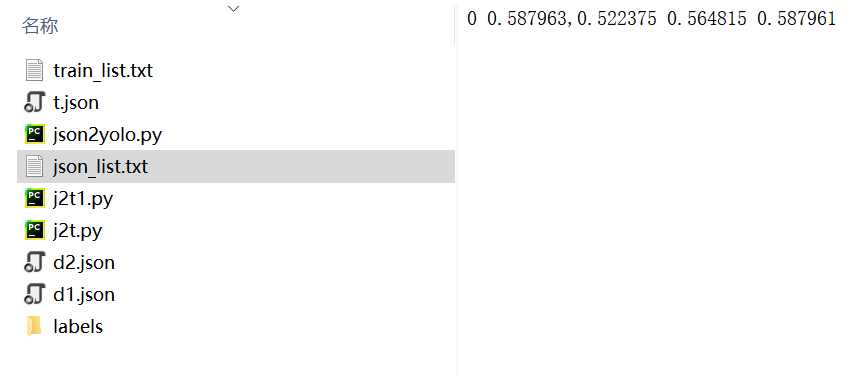
4.遍历一个文件夹下所有json文件夹(可选择)
import os
import requests
from urllib.parse import quote
import re
import json
# 读取文件夹中的文件名
fileList = os.listdir('E:/Acryl/datapro/jsonfile/')
print(fileList)
# 循环读取文件,并请求
for json_id in fileList:
print(json_id)
with open('E:/Acryl/datapro/jsonfile/' + json_id, "r", encoding="utf-8") as f: # 打开文件
data = f.read() # 读取文件
#print(data)测试打印所有数据
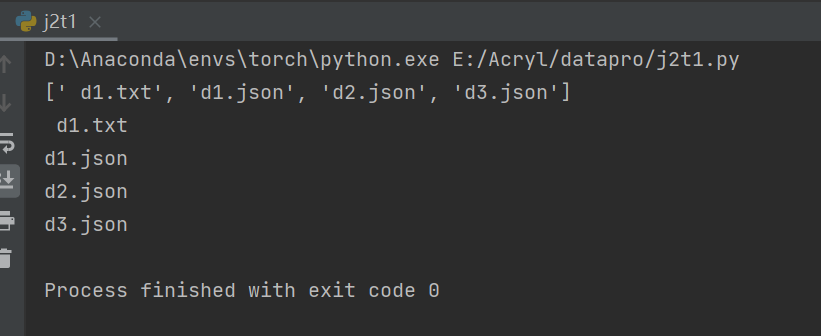
5.查看一个文件夹下所有文件以及子目录文件(可选择)
from pathlib import Path
#只能查看不能读取
if __name__ == '__main__':
p = Path('E:/Acryl/datapro/jsonfileall/')
#print(p)
for path in p.rglob("*"):
print(path)
6.python遍历目录下的所有目录和文件, python解析json文件, python-opencv截取子图(可选择)
import cv2
import os
import json
import numpy as np
"""首先根据传入的主目录路径,得到里面的子文件夹路径,其中每个子文件夹里面分别保存着若干jpg图片和一个json文件"""
def get_dirs(main_dir):
list_dirs = []
for root, dirs, files in os.walk(main_dir):
for dir in dirs:
list_dirs.append(os.path.join(root, dir))
return list_dirs
"""每个文件夹下面包含若干张jpg图片和一个json文件,根据传入的文件夹路径,得到该文件夹下的所有的jpg文件和json文件。(包含路径)"""
def get_file(dir_path):
list_jpgs = []
for root, dirs, files in os.walk(dir_path):
for file in files:
if file.endswith(".jpg"): #过滤得到jpg文件,
#print(os.path.join(root, file))
list_jpgs.append(os.path.join(root, file))
if file.endswith(".json"): #过滤得到json文件
json_path = os.path.join(root, file) #json文件只有一个,就不用列表了
return list_jpgs, json_path #得到所有的jpg文件和json文件的列表(包含路径)
"""
从json文件中获取到坐标信息,打开并加载完json文件之后,开始解析json内容,
json中的object对应着python中的字典,
json中的array对应着python中的列表,
然后无非就是他们的嵌套,一个一个挨着解析就好了。
"""
def get_coordinate(json_path):
coordinates = []
with open(json_path, 'rb') as file_json:
datas = json.load(file_json)
#print(datas['shapes']) #datas的shapes元素是一个列表
for list in datas['shapes']:#逐个遍历datas['shapes']列表中的每个元素,其中每个元素又是一个字典
#print(list['points']) #list字典中的points对应的values值就是坐标信息,而该坐标信息又是两个列表,
coordinates.append(list['points'])
return coordinates
"""根据文件夹下面的json文件里面的坐标信息,从文件夹下面的jpg图片截取子图"""
if __name__ == '__main__':
main_dir = r"F:\tubiao"
i = 0
dirs = get_dirs(main_dir)#这一步是得到文件夹下的所有文件夹路径,其中每个文件夹下面又包含若干照片和一个json文件。
for dir in dirs:#针对每个子文件夹里面的图片和json分别进行处理
print(dir)
j = 0 #每个文件夹里面的截取的子图保存时从0开始。
list_jpgs, json_path = get_file(dir)#这一步是得到每个子文件夹里面的jpg图片路径名字和json路径名字
coordinates = get_coordinate(json_path)#这一步是根据json文件路径得到接送里面保存的坐标信息,
for list_jpg in list_jpgs:#对每个图片进行截图,
for coordinate in coordinates:#根据坐标信息截图,有几个坐标信息就截几个图片
#image = cv2.imread(list_jpg) #不能读取中文路径,用imdecode代替
#print(list_jpg)
image = cv2.imdecode(np.fromfile(list_jpg, dtype=np.uint8), cv2.IMREAD_COLOR)
#image = cv2.cvtColor(image_temp, cv2.COLOR_RGB2BGR) 这个不能加,加上之后截出来的子图保存后颜色都变了。
x1 = int(coordinate[0][0]) #左上角的顶点X
y1 = int(coordinate[0][1]) #左上角的顶点Y
x2 = int(coordinate[1][0]) #右下角的顶点X
y2 = int(coordinate[1][1]) #右下角的顶点Y
cropImg = image[y1:y2, x1:x2] #坐标顺序是Y1:Y2, X1:X2,Y在前,X在后。
save_name = str(i) + "_cut" + str(j) + ".jpg" #因为是截子图,所以加了个cut
save_path = os.path.join(dir,save_name)
j = j + 1
#print(save_path)
# cv2.imwrite(save_path, frame) #保存路径中包含中文,不能用imwrite保存,要用下一行的imencode的方法。
ret = cv2.imencode('.jpg', cropImg)[1].tofile(save_path) # [1]表示imencode的第二个返回值,也就是这张图片对应的内存数据
i = i + 1#保证每个文件夹里面截取子图的时候命名不重复7.python遍历目录下的所有目录和文件, python读取json文件信息, 生成一个list.txt(可选择)
#Y
import json
import os
def readjson():
path = 'E:/Acryl/datapro/jsonfileall/jsonfile/' # 包含所有json文件夹位置
files = os.listdir(path)
label_txt = open('E:/Acryl/datapro/jsonfileall/label_txt.txt', mode='w')
for file in files:
f = open(path + '\\' + file, mode='r', encoding='utf-8')
temp = json.loads(f.read())
for temp in temp:
try:
json_str = temp[str('Label')] + ' ' + temp[str('Point(x,y)')] + ' ' + temp[str('W')] + ' ' + temp[str('H')]
except:
pass
json_str = temp["Label"] + ' ' + temp[str("Point(x,y)")]+' '+ temp[str('W')]+' '+temp[str('H')] # 写入txt文件
label_txt.writelines(json_str + '\n')
print(json_str) # 打印提取的数据
label_txt.close()
if __name__ == '__main__':
readjson()
效果如下
测试数据为三个json文件,json文件同上

运行后输出一个txt文件,如下:
8.自己数据集的json文件为bbox四点信息,需要归一化处理为YOLO格式代码
import os
import json
# 只有一个json文件
json_dir = 'train_annos.json' # json文件路径
out_dir = 'output/' # 输出的 txt 文件路径
def main():
# 读取 json 文件数据
with open(json_dir, 'r') as load_f:
content = json.load(load_f)
# 循环处理
for t in content:
tmp = t['name'].split('.')
filename = out_dir + tmp[0] + '.txt'
if os.path.exists(filename):
# 计算 yolo 数据格式所需要的中心点的 相对 x, y 坐标, w,h 的值
x = (t['bbox'][0] + t['bbox'][2]) / 2 / t['image_width']
y = (t['bbox'][1] + t['bbox'][3]) / 2 / t['image_height']
w = (t['bbox'][2] - t['bbox'][0]) / t['image_width']
h = (t['bbox'][3] - t['bbox'][1]) / t['image_height']
fp = open(filename, mode="r+", encoding="utf-8")
file_str = str(t['category']) + ' ' + str(round(x, 6)) + ' ' + str(round(y, 6)) + ' ' + str(round(w, 6)) + \
' ' + str(round(h, 6))
line_data = fp.readlines()
if len(line_data) != 0:
fp.write('\n' + file_str)
else:
fp.write(file_str)
fp.close()
# 不存在则创建文件
else:
fp = open(filename, mode="w", encoding="utf-8")
fp.close()
if __name__ == '__main__':
main()9.自己数据集的批量读取json文件,读取必要信息转为对应的txt文件(YOLO需要的格式)
import os
import numpy as np
import json
def json2txt(path_json, path_txt):
with open(path_json, 'r', encoding='gb18030') as path_json:
jsonx = json.load(path_json)
with open(path_txt, 'w+') as ftxt:
for shape in jsonx:
xy = shape["Point(x,y)"]
label = shape["Label"]
w = shape["W"]
h = shape["H"]
strxy = ' '
ftxt.writelines(str(label)+ strxy + str(xy) + strxy + str(w)+ strxy + str(h)+"\n")
dir_json = 'E:/Acryl/datapro/jsonfileall/jsonfile/'
dir_txt = 'E:/Acryl/datapro/labels/'
if not os.path.exists(dir_txt):
os.makedirs(dir_txt)
list_json = os.listdir(dir_json)
for cnt, json_name in enumerate(list_json):
print('cnt=%d,name=%s' % (cnt, json_name))
path_json = dir_json + json_name
path_txt = dir_txt + json_name.replace('.json', '.txt')
print(path_json, path_txt)
json2txt(path_json, path_txt)效果

10.遍历多个文件夹,查找并打印json文件信息
import json
import sys
import os
def walkrec(root):
for root, dirs, files in os.walk(root):
for file in files:
path = os.path.join(root, file)
if file.endswith(".json"):
print(file, end=' ')
with open(path) as f:
data = json.load(f)
print(data)
if __name__ == '__main__':
path='E:\\datapro\\jsonfileall' #自己的路径
walkrec(path)
11.python遍历目录下的json文件, 生成一个包含路径的list.txt文件(可选择)
# -*- coding: utf-8 -*-
import os
path1 = '/workspace/yolo/data/dataset/f001json'
def file_name(file_dir):
for root, dirs, files in os.walk(file_dir):
file = open('labellist.txt', 'w+')
for f in files:
# print(os.path.join(path1,f))
i = (os.path.join(path1, f))
file.write( i + '\n')
file.close()
if __name__ == '__main__':
file_name('/workspace/yolo/data/dataset/f001json')效果
labellist.txt
12.批量修改处理txt文件内容
批量修改txt文件,在做YOLO项目时,会需要将文本文件中的某部分内容进行批量替换和修改,所以编写了python程序批量替换所有文本文件中特定部分的内容。
import re
import os
# 38 labels
def reset():
i= 0
path='/workspace/yolo/data/dataset/test/'
#path = "/workspace/yolo/data/dataset/labels0208/"
filelist = os.listdir(path) # 该文件夹下所有文件(包括文件夹)
for files in filelist: # 遍历所有文件
i = i + 1
Olddir = os.path.join(path,files); # 原来的文件路径
if os.path.isdir(Olddir):
continue;
filename = os.path.splitext(files)[0];
filetype = os.path.splitext(files)[1];
filePath = path+filename+filetype
#这里会把所有0->1
alter(filePath,"0","1")
def alter(file,old_str,new_str):
with open(file,"r",encoding="utf-8") as f1,open("%s.bak"% file,"w",encoding="utf-8") as f2:
for line in f1:
if old_str in line:
line = line.replace(old_str,new_str)
f2.write(line)
os.remove(file)
os.rename("%s.bak" % file,file)
reset()方法2:
"""
Created on 2023.02
@author: Elena
"""
# coding=utf-8
import os
path = path='/workspace/yolo/data/dataset/test'
def listfiles(dirpath):
filelist = []
for root, dirs, files in os.walk(dirpath):
for fileObj in files:
filelist.append(os.path.join(root, fileObj))
return filelist
def txt_modify(files):
for file in files:
label_path = os.path.join(path, file)
with open(label_path, 'r+') as f:
lines = f.readlines()
for line in lines:
# e.g.'Bus' is the new one, Truck is the old one
f.seek(0)
f.truncate()
f.write(line.replace('Truck', 'Bus'))
# f.write(line.replace('dog', 'cat').replace('man', 'boy')) # 多个内容的替换
f.close()
def main():
filelist = listfiles(path)
for fileobj in filelist:
f = open(fileobj, 'r+')
lines = f.readlines()
f.seek(0)
f.truncate()
for line in lines:
f.write(line.replace('2 ', '3 '))
f.close()
if __name__ == main():
main()方法3:处理yolo已经转换好的标签数修改
import os
import re
#path = '/workspace/yolo/data/dataset/testjson2txt/1/'
path='/workspace/yolo/data/dataset/labels0208/'
files = []
for file in os.listdir(path):
if file.endswith(".txt"):
files.append(path+file)
for file in files:
with open(file, 'r') as f:
new_data = re.sub('^12', '1', f.read(), flags=re.MULTILINE) # 将列中的12替换为1
print("Down")
with open(file, 'w') as f:
f.write(new_data)别的类型
第四篇—json标签(labelme)转txt标签(YOLOv5专题) - 哔哩哔哩 (bilibili.com)
YOLOV5——将 json 格式的标注数据转化为 YOLO 需要的 txt 格式 - yx啦啦啦 - 博客园 (cnblogs.com)