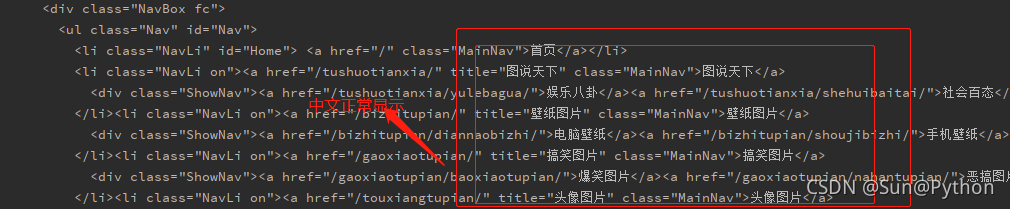
问题描述:使用python的requests.request()获取网页数据时,中文显示乱码?
例子:
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2021/9/7 9:35
# @Author : Sun
# @Email : [email protected]
# @File : sun_test.py
# @Software: PyCharm
import requests
from bs4 import BeautifulSoup
url = "https://www.****.cc/*******/"
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36 "
}
response = requests.request(method="Get", url=url, headers=header)
result = response.text
print(result)
# 查看headers中Content-Type
print(response.headers)
结果:
 原因为:请求中没有指定编码格式,默认用ISO-8859-1编码格式进行编码。Latin1是ISO-8859-1的别名,有些环境下写作Latin-1。因此想获取中文必须先编码在解码
原因为:请求中没有指定编码格式,默认用ISO-8859-1编码格式进行编码。Latin1是ISO-8859-1的别名,有些环境下写作Latin-1。因此想获取中文必须先编码在解码
response = requests.request(method="Get", url=url, headers=header)
result2 = response.text.encode("latin1").decode("utf-8")
print(result2)
结果: