union all操作
UNION ALL 运算符可合并多个 SELECT 命令的输出,而不会消除重复的行。
UNION ALL运算符涉及每个 SELECT命令,以在相同数据类型的输出中具有相等数量的字段。
这里注意union和union all的区别在于union是去重的,而union all不去重。
KES union all语法
KES union all的语法如下:
SELECT expression_1, expression_2, ... expression_n
FROM tables
[WHERE condition(s)]
UNION ALL
SELECT expression_1, expression_2, ... expression_n
FROM tables
[WHERE condition(s)];
注意: 在以上语法中,两个表达式必须具有相等数量的表达式。
各参数说明如下:
| 参数 | 说明 |
| expression_1,expression_2,... expression_n | 要检索的target列 |
| tables | 要查询的表 |
| where条件 | 过滤条件 |
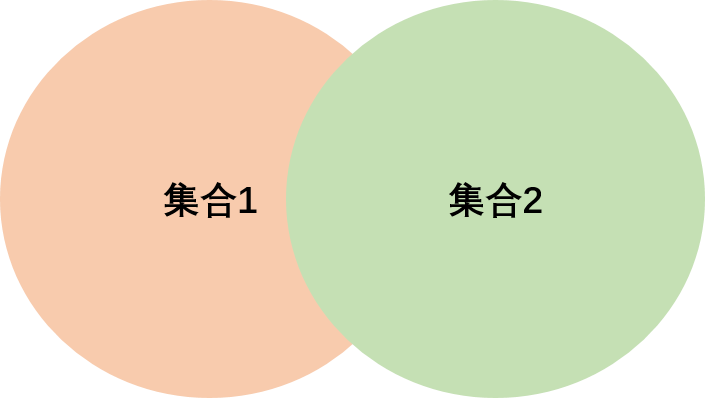
我们可以通过下图了解 UNION ALL运算符的工作方式:
KES对union all的优化
KES对顶层的union all进行扁平化处理,将union all集合操作转换成AppendRelInfo的形式。例如下面的例子中:
explain select * from tab_01 where id < 100 union all select * from tab_02 where id < 50;
QUERY PLAN
---------------------------------------------------------------------
Append (cost=0.00..596067.72 rows=3158 width=18)
-> Seq Scan on tab_01 (cost=0.00..298007.66 rows=1579 width=18)
Filter: (id < 100)
-> Seq Scan on tab_02 (cost=0.00..298012.69 rows=1579 width=18)
Filter: (id < 50)
(5 rows)

通过计划可以看到KES将两个查询转换成Append节点进行处理。
KES未做优化前union all的查询树结构如下:
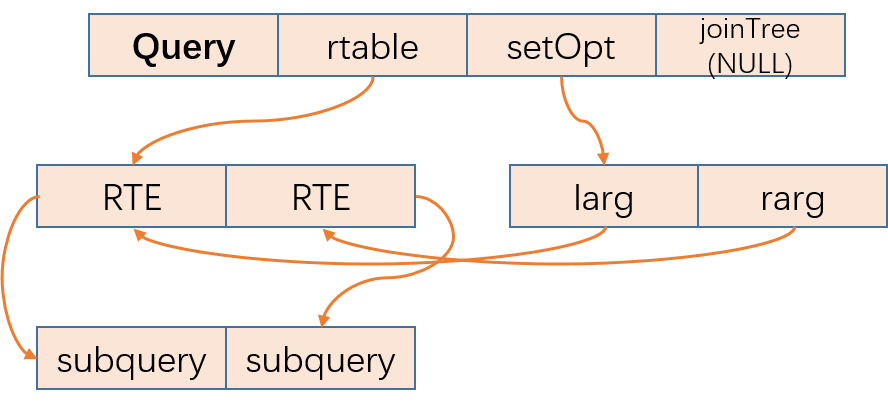
优化前,每个范围表是一个子查询,集合操作的左右参数是两个子查询。
KES将union all优化后的查询结构如下:
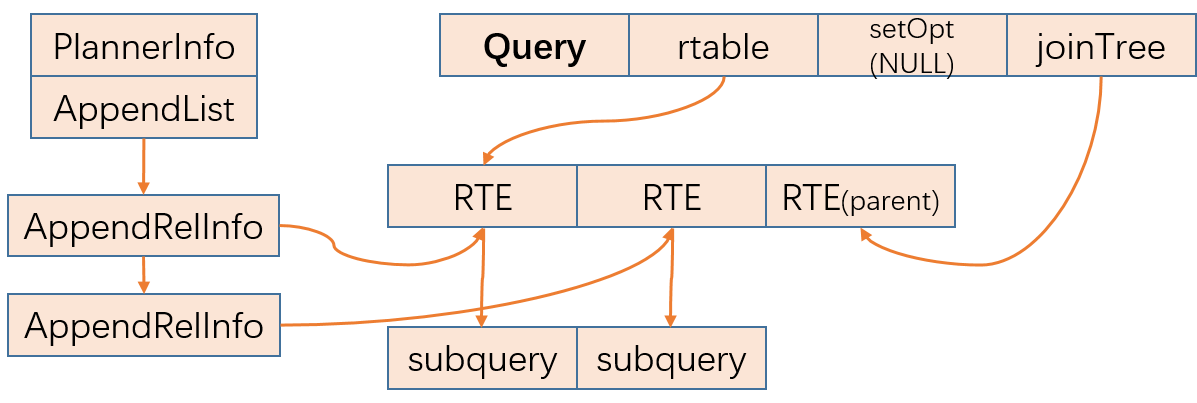
KES优化后增加Append节点进行处理。
开启并行后的执行计划如下:
explain select * from tab_01 where id < 100 union all select * from tab_02 where id < 50;
QUERY PLAN
-----------------------------------------------------------------------------------
Gather (cost=1000.00..281519.24 rows=3158 width=18)
Workers Planned: 5
-> Parallel Append (cost=0.00..280203.44 rows=3158 width=18)
-> Parallel Seq Scan on tab_02 (cost=0.00..140078.54 rows=316 width=18)
Filter: (id < 50)
-> Parallel Seq Scan on tab_01 (cost=0.00..140077.53 rows=316 width=18)
Filter: (id < 100)
(7 rows)
【更多人大金仓数据库信息,详见https://help.kingbase.com.cn/】