引言
Cola作为当前比较优秀的领域驱动设计最佳实践框架越来越被更多的技术人所知晓。先抛出COLA 4.0:应用架构的最佳实践_张建飞(Frank)的博客-CSDN博客_cola架构 是关于COLA4.0最新的内容介绍。然后个人对于读了这篇文章后,对于其中的架构理念和其中的各组件的设计加了一点个人解读来分享。
主要分为两部分来进行分析,一个架构,一个组件。架构主要想分析他的分层结构对于我们做技术架构设计和模块划分有的指导意义。组件主要就是对于一些编程的方法来解耦业务的最佳方法论。
COLA架构解析
下图转载 COLA 4.0:应用架构的最佳实践_张建飞(Frank)的博客-CSDN博客_cola架构
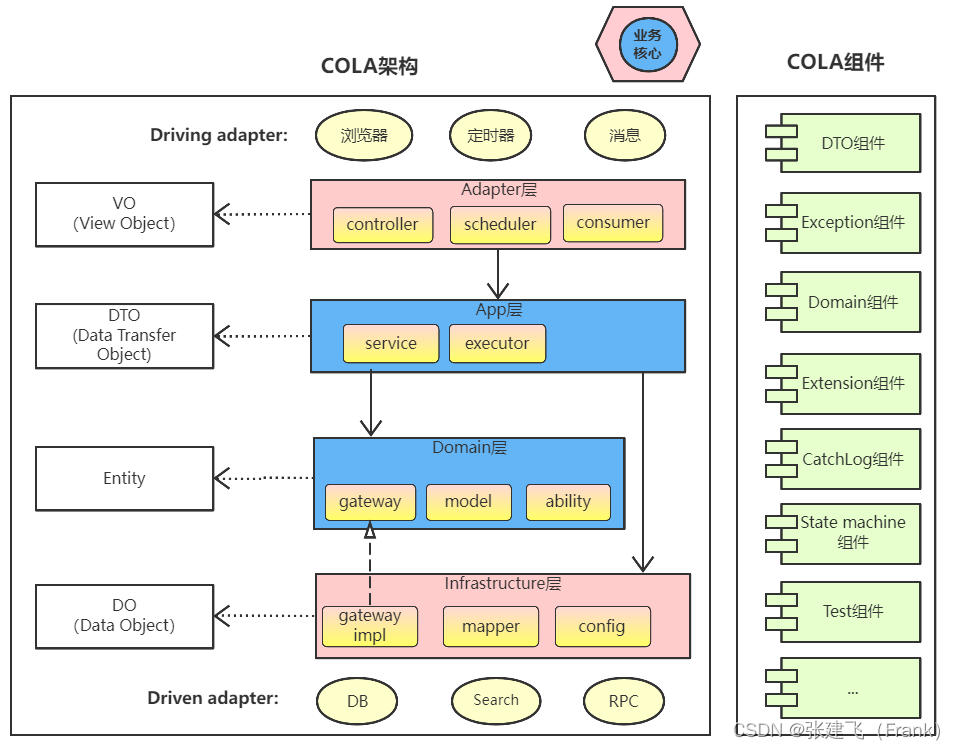
垂直拆分
从上往下分别有
- VO:ViewObject 视图 也就是给用户看的数据,也称为Controller层
- DTO: DomainTransferObject 领域转化对象 也就是领域对象转换后的对象,也称为Service层
- Entity: Entity 实体 也就是代表具体有行为的实际对象,也成为Domain层
- DO: DomainObject 领域对象,也就是领域对象,基础设施层
为什么会产生这样的分层呢?我从最原始的时候开始说明,解说这个演变过程。
最早的时候还是单体服务时候,也没有领域概念,有DAO层,实体层,服务(Service)层,控制(Controller)层,视图(View)层。后来为了提升开发效率,展示层和逻辑彻底分离,就有了前后端分离的技术,就弱化了视图层。只有控制层,形成统一的MVC架构。
后来业务发展越来越多样化,视图层对于数据结构的需求越来越多,为了响应这种变化,同时保持业务的扩展性,就得在视图层和实体层增加一层数据转化层,用来应对各种各样的场景下的视图,就形成了DAO层,实体层,DTO层,服务(Service)层,控制(Controller)层。
紧接着互联网进一步发展,业务进一步扩大,单体服务已经不能满足需求,就有了微服务。这时候服务的能力就进而被拆分成多层,有聚合层和基础服务层。此时分层服务层需求还可以满足,但是聚合层的话就难以清晰的表达了。因为聚合层可能会涉及到多个也业务域,而不同的业务域对于聚合层来讲又不能是实体层,也不能是服务层。因为如果实体层,聚合服务内的领域边界就很难清晰。如果是服务层,那么聚合服务的本身的服务层就被污染了。所以很多微服务的框架引入了一个Model层,他直接在聚合层把不同业务域分在不同的Model里面。不过此方案对于开发工作者来说有较高的要求,需要他能很好的了解领域划分。
后来就进行了领域驱动设计,这个要满足的就是以领域驱动,还有就是编程思想的转变,以充血模型替代原来的贫血模型。他认为对象除了有属性职位还应该有行为,有动作,从而达到完整的对象的目的。属性和行为密不可分的。所以将实体层和DAO层整合到一起形成基础设施层。当从基础设施完成了对象的构造之后就形成了领域层,就是领域对象。实体层同时也需要定义对象的实际行为,基本的增删改查等等。DTO层保留,控制层和视图层也保留。但是这个时候DTO虽然依然是进行数据转化,但是他是严格遵循业务过程中领域上下文(AddCustomerCmd)的数据转化。
@Extension(bizId = Constants.BIZ_1)
public class CustomerBizOneConvertorExt implements CustomerConvertorExtPt {
@Autowired
private CustomerConvertor customerConvertor;//Composite basic convertor to do basic conversion
@Override
public CustomerEntity clientToEntity(AddCustomerCmd addCustomerCmd){
CustomerEntity customerEntity = customerConvertor.clientToEntity(addCustomerCmd);
CustomerDTO customerDTO =addCustomerCmd.getCustomerDTO();
//In this business, AD and RFQ are regarded as different source
if(Constants.SOURCE_AD.equals(customerDTO.getSource()))
{
customerEntity.setSourceType(SourceType.AD);
}
if (Constants.SOURCE_RFQ.equals(customerDTO.getSource())){
customerEntity.setSourceType(SourceType.RFQ);
}
return customerEntity;
}
}此时的各个层之间的交互数据不再是对象或者其他,而只能是有领域边界定义的限界上下文。领域的划分和限界上下文的定义,请参考 猿创征文|微服务架构领域驱动设计(DDD)_剑飞的编程思维的博客-CSDN博客_微服务拆分 领域驱动设计
水平拆分
从左往右分别有
- VO:手机端,小程序端,浏览器端,消息,调度任务
- DTO: 服务,执行器
- Entity: 接口,模块,能力
- DO: 接口实现,仓库,配置
水平拆分的目的是在于在同一个逻辑层次,由于应用域不一样,使用的方法差别比较大,比如手机端和小程序端返回的数据差别和功能迭代差别较大,所以需要拆分到不同的类别。再就是执行器和服务,服务完成了功能,但是有时候再执行服务的时候可能会有相关联的业务操作,这个时候需要用执行器包装,但是他要跟服务解耦,所以要拆分。防腐层,模块和能力都是根据具体的业务做的一个划分,主要是是根据职责划分。践行单一职责原则,迪米特法则。
COLA组件
组件解决是是我们再日常开发服务中经常要用到的一些功能,封装后我们可以直接复用。同时也是可以规范我们的开发能力,不会导致代码风格混乱,从而提升开发效率。
Catchlog组件
通过定义切面,对于请求处理前后,进行日志打印,接口监控。同时定义响应体的统一处理接口,为统一处理提供一个可扩展点
Domain组件
通过多例模式,实现了充血模型的开发。为什么要用多例?首先Spring的创建的Bean模式单例的,然后充血模型的实例中是有属性的,那么他的行为只能在当前线程中安全,如果是单例,那么线程不安全,所以必须要是多例模式。应用了工厂模式生成多例。
DTO组件
定义数据转换的基本结构,父类ClientObject,Command,Response,DTO等等,扩展点名称等统一定义父类,形成多态,定义转化数据的基本规范和职责
Exception组件
定义服务中的异常,系统异常,业务异常,检查异常
Extention组件
扩展点的定义以及组装,通过函数接口,提取出扩展点,如图

函数接口,以及starter组装,扩展点的适配缓存都是较好的编程风格
StateMachine组件
这个状态机的核心思想就是把一些状态流程,流程化的开发通过定义全局结构,实现逻辑和代码的接口。核心的就是泛型的使用,状态流转的对象就是变更前,变更后,然后上下文主要对象。
除了以上的组件外,在开发中我们可能对于一些基本的操作都需要封装成组件,以供开发规范使用。
总结
分析Cola除了我们可以在开发过程中去直接引用这个框架外,更重要的是我们可以改变我们的编程思维去学习这个思考过程,学习编程方法,应用到我们实际的项目中,让我们朝着更优秀的程序员前进。