1.1 数据表示
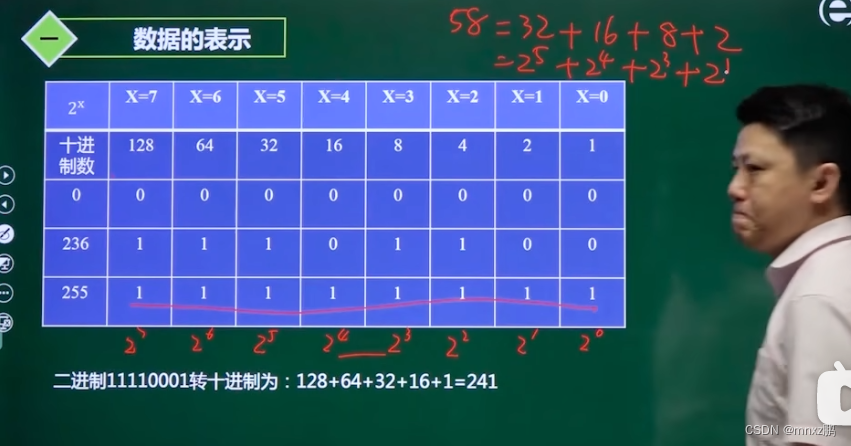


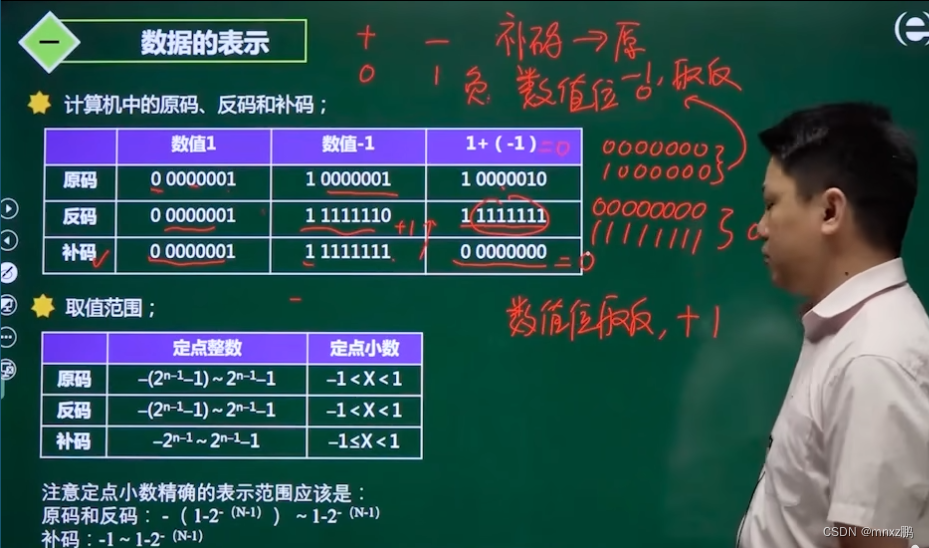
原码、反码、补码
数分正、负,码分三码
计算机用的是补码
原码:最高位(从左往右第一个)为符号位,正数记为0,负数记为1,其它为存储位。
运算过程中,运算位和符号位(最高位)要分离 。 不足:对计算机加法开销过大。
用原码表示0:10000000 或 00000000

反码:正数和原码表述一致 ;负数最高位取值和源码一致,其它数值位“按位取反(和原码相反)”。
用补码表示0:11111111 或 00000000 取值范围:-127~127
补码:正数和原码、补码一致,。负数的最高位和原码、补码规则一致(负数最高位为1),其它数位值在补码的基础上加1。 取值范围:-128~127
用补码表示0,只有一种:00000000
总结:知原码,求补码。
①正数不变,负数的原码减1再取反
②正数不变,负数的话先取反再+1
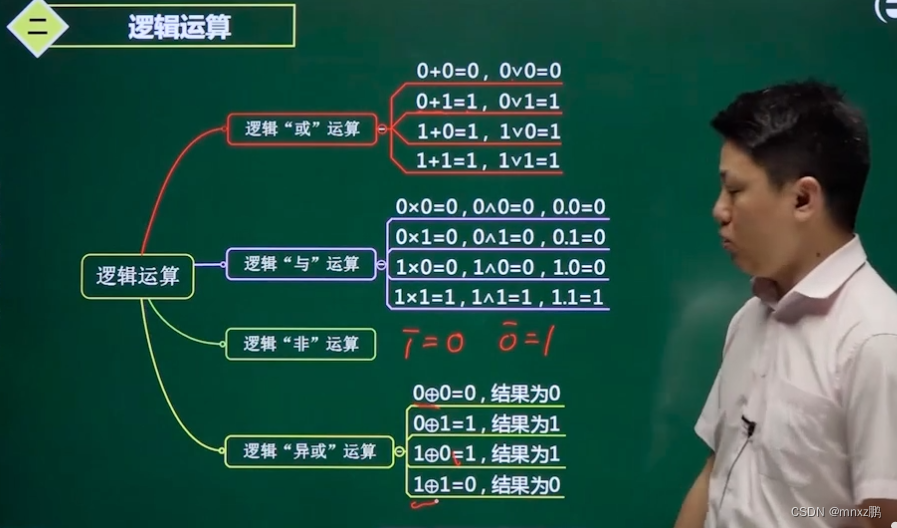
1.2 逻辑运算
或、与、非、亦或
或:一真则真,全假则假
与:全真则真,一假则假
非:取反
亦或:两个逻辑变量是否一致,一致输出0,不一致输出为1.
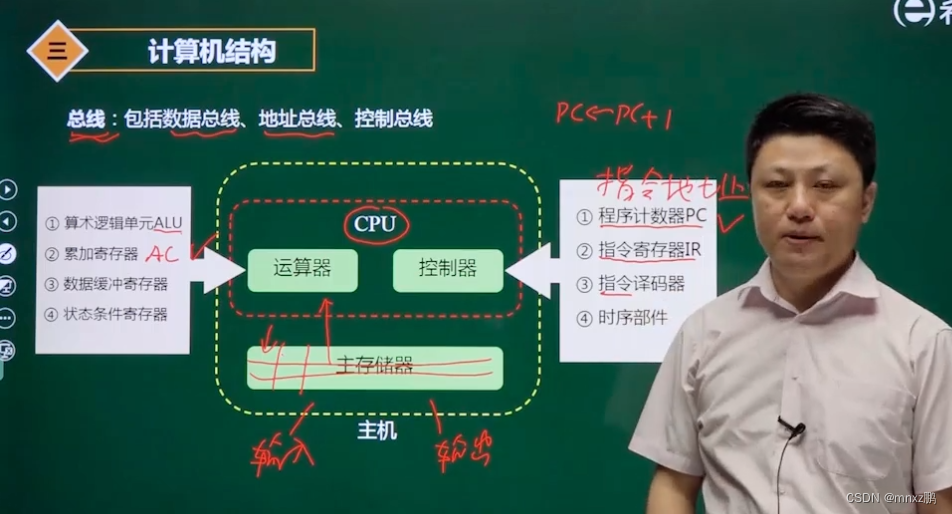
1.3计算机体系结构
当前的计算机体系结构,还是冯诺依曼下的体系结构:运算器、控制器以及主存储器、输入系统和输出系统组成。其中,运算器和控制器组成了CPU。
运算器:4部分
①算术逻辑单元ALU:用于算术运算和逻辑运算
②累加寄存器AC:暂存中间计算的结果
③数据缓冲寄存器:从主存储器中读取数据
④状态条件寄存器:用于保存计算过程中的信息
控制器:分4部分
①程序计数器PC:用于寻找指令地址
②指令寄存器IR:用于保存当前正在执行的指令
③指令译码器:指令分为操作码和地址码。所谓指令译码就是把操作码进行译码,然后向操作部件发送。
④时序部件:为我们的指令执行产生时序信号。
CPU和主存储器,输入、输出设备构成的主机通过总线进行工作。
其中总线又分为:数据总线、地址总线和控制总线3种,分别传输数据信息、地址信息、控制信息
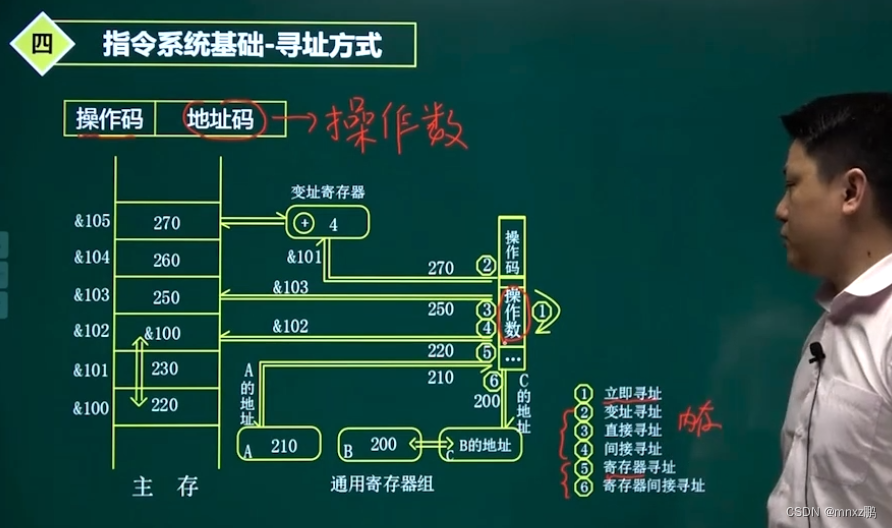
1.4指令系统-寻址方式
寻址方式,指的就是“寻找操作数”。
程序:把程序app转化为一条条指令执行。而指令又包括两部分组成:操作码和地址码。
操作码指的是进行什么样的操作(+-*/);而地址码指的是对什么样的数据进行操作(即操作数的地址)
寻址分为6种,三类:第一种是立即寻址,第2 3 4 是内存寻址,第5 6是寄存器寻址。
立即寻址:指令中夹杂(包含着)操作系统
直接寻址:一次访问即可得到操作数地址
间接寻址:两次或两次以上访问才能得到操作数地址
变址寻址:需要设置一个寄存器
寄存器寻址:操作数地址在寄存器当中
寄存器间接寻址:首先从寄存器中得到内存地址,然后再到内存当中得到操作数地址 (二步寻址)
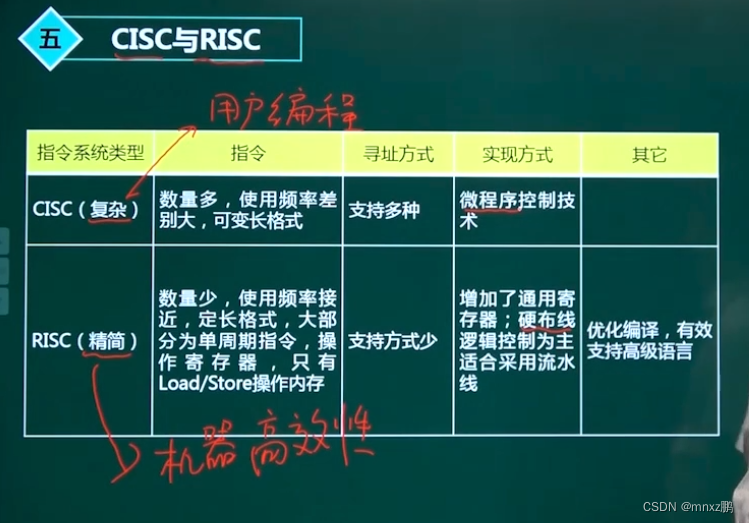
1.5 CISC与RISC
1.6流水线
→取指 → 分析 → 执行

疑问:并行执行为什么是5S?
考点:
1.计算流水线周期

2.流水线指标
- 吞吐率:实际吞吐率 Tp=n/Tk (n--指令条数,Tk--流水线执行完毕需要总时长)
理论最大吞吐率Tp=1/T (T=2)
- 加速比:S=Ts/Tk (Ts--不按流水线执行完需要的总时长)
- 效率:每一步执行的指令个数/每一步的总个数

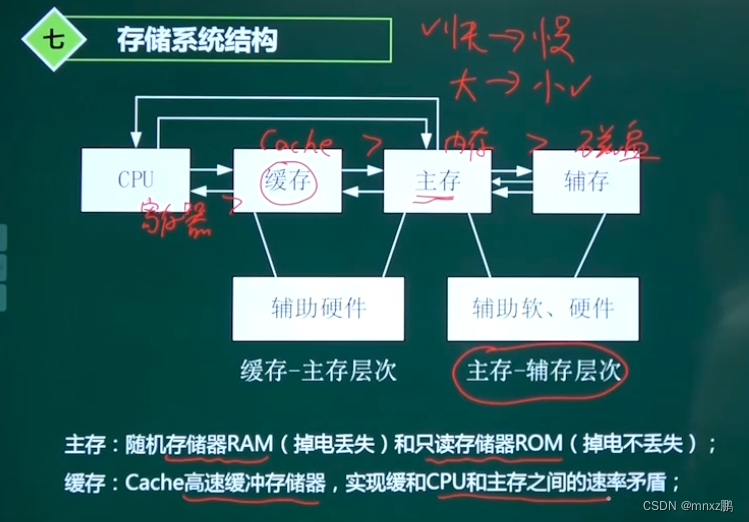
1.7存储系统结构
存储的读取速率:CPU>Cache>主存>辅存
辅存与主存,是操作系统的重要存储内容
1.8存储系统的存取方式
存储器存储方式:4种
- 顺序存储(磁带)
- 直接存取(硬盘--有磁头)
- 随机存储(内存):任何时间可以对任何一个存储单位模块进行读取,并且和它的访问序列无关。
- 相联存储(Cache):读取时只取决于内容,与地址无关。
1.9主存储器基础-组成
芯片数量=芯片总能量/某一芯片规格

十六进制转为2进制
先算,转化为2进制;再看按什么编址:1字节=8bit


1.10Cache
作用:高速缓chong存储器,用于弥补CPU和内存的(读取速率)的差异性,速率介于二者之间 。

Cache淘汰算法
CPU访问内存时,内存先把数据放在Cache中,当Cache缓存已经满了,但CPU需要继续访问内存,此时的Cache就会丢弃掉一些之前缓存的数据(内容)----即为“淘汰”
- 先进先出算法
- 最近最少使用算法 (最为理想)
- 随机算法

1.11磁盘
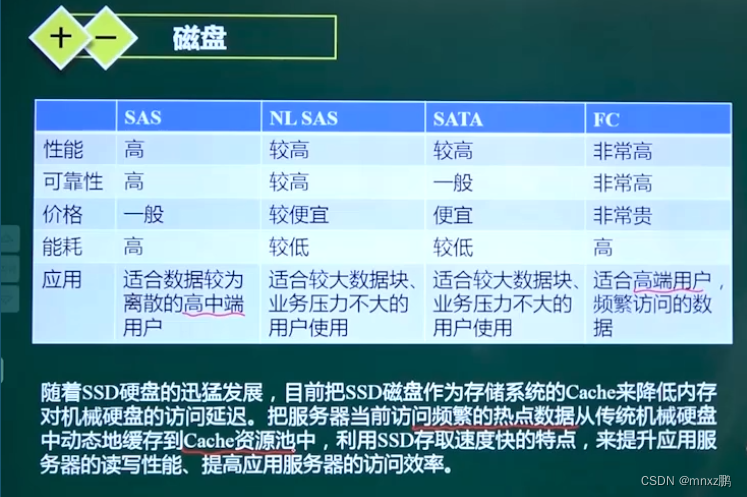
廉价磁盘冗余阵列 技术 RAID
- 思想:条带化(提升带宽)+校验技术(海明校验、奇偶检验等),提升磁盘读写的性能。
- RAID 优势:把多个独立的物理硬盘通过相关的算法组合成一个虚拟的逻辑硬盘,从而提供更大容量、更高性能,或更高的数据容错功能。
- 条带宽度:在一个RAID组中,由多块磁盘来组。
- 条带深度:在单块磁盘中,分块的大小
- 条带大小=条带深度 × 条带宽度
RAID0技术 :写入速度快,但是可靠性是最差的。


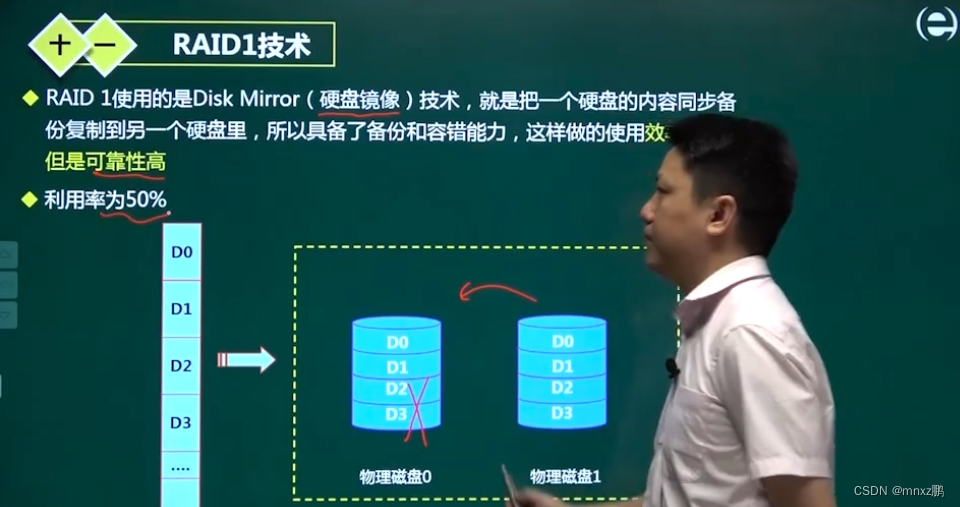
RAID1:互为镜像,具备备份和容错能力。效率不高,但是可靠性高。

RAID3
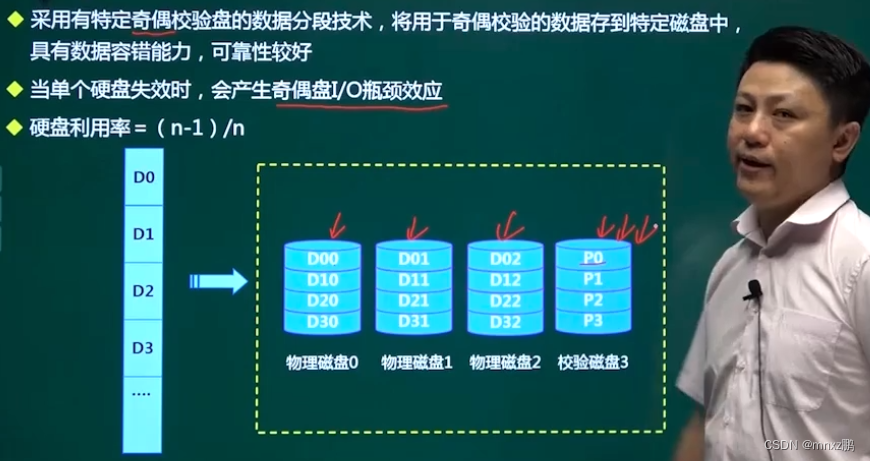
利用校验技术和条带化技术。
- 缺点:会产生I/O瓶颈效应,因为不管是哪块磁盘在工作,校验磁盘始终处于读写状态。
- 盘利用率:3/4 (有一块用于存储校验数据)
RAID4/5(二者相似,磁盘单位不同)
RAID5技术
- 优势:具有数据容错能力,可靠性好。支持多个I/O并行。相较RAID3,没有I/O瓶颈。
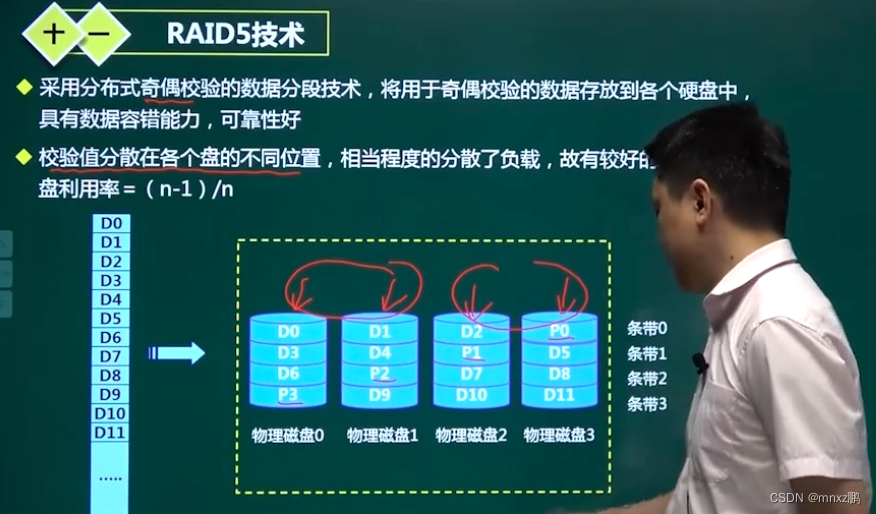
- 不足:控制器设计复杂,磁盘重建的过程比较复杂

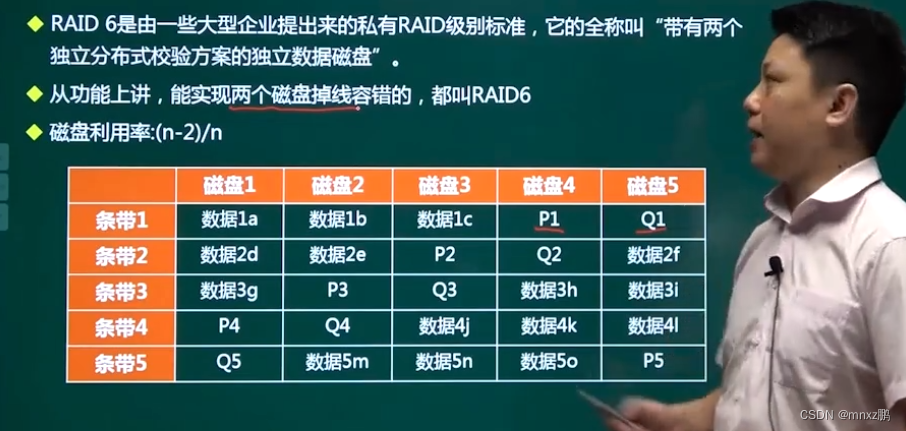
RAID6技术
增加了两个校验位,可以允许两块磁盘出现错误。
所以次盘利用率:(n-2)/n
企业用的比较多的是RAID1 0 组合 (还有RAID5)
- 原理:先分别镜像1,再组合0 磁盘利用率:50%(RAID1)

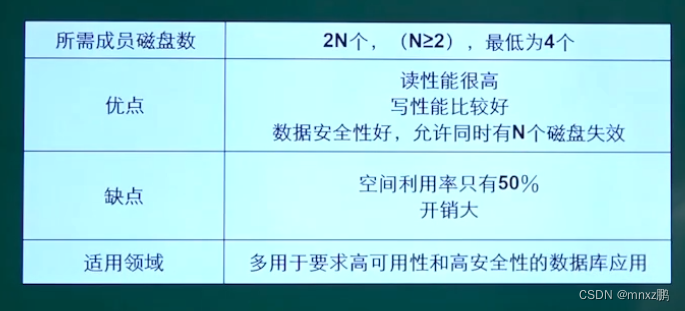
RAID10 与RAID5比较
- 性能:RAID10 >RAID5
- 可靠性:RAID10 > RAID5
- 重构(恢复速度):RAID10 > RAID5
- 成本:RAID10 < RAID5
考试过多次???如何选择
若是保存关键应用:选RAID10
若是非关键应用,且考虑成本:选RAID5 (备份服务器,远程灾备完全可用 RAID5)
RAID保护
- 热备份:当一块磁盘坏掉后,其他磁盘可以将数据快速备份恢复到热备盘,加快数据重构。
- 预拷贝:某一物理磁盘即将发生故障时(该磁盘某些参数超出了最大可容忍值),此时该磁盘可以提前把数据拷贝到热备盘中的过程。
- 失效重构:当一块磁盘挂掉之后,如何对数据进行恢复?
- RAID状态:当其中一块磁盘失效后,如果RAID组中的数据还能读出的话,称为降级状态;若不能读出,称之为失效状态。
RAID的发展
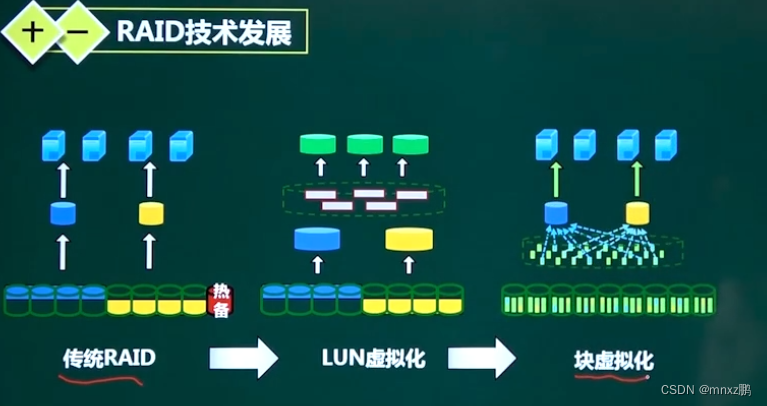
LUN虚拟化技术的风险较高,
块虚拟化:主要是RAID2.0 (考过一次--RAID2.0的特点),生产商代表:华为
- 传统的RAID技术都是基于磁盘来构建RAID组,而RAID2.0是基于数据块来构建RAID组
- 首先把磁盘分成很多的数据块(可能来自所有的磁盘),然后建RAID组时 是将很多的RAID块来构建RAID组。
- 优势:当某个数据块挂掉时,“一方有难八方支援”。即当某一块磁盘挂掉后,能快速进行重构。

1.12系统的可靠性
系统的工作方式:串行和并行
- 串行
比如计算机中的CPU和内存(串行),一个CPU故障,整个系统故障;内存故障,整个系统故障
对于计算机系统,如果都以串行方式工作,如何计算可靠性?
计算:R=R1 × R2 × R3 ×...× Rn
- 并行(内存:内存1、内存2.....)
只有当所有内存进程都发生故障,系统才会故障。
排除这一情况,就可以计算系统可靠性?
计算:R=1 -(1-R1)× (1-R2) ×...× (1-Rn)

说明:以上材料均为本人在哔哩哔哩网站上学习整理所成,文章仅为自己学习记录复习使用。参考视频资料视频资源系希赛团队老师讲解,若笔记表述或内容有误,诚盼指正!
希望更多资料的uu,可以移步B站自行查找哦!