前言
自从bert发展以来,NLP在通过pre-training,fine-tuning的方式在各种任务上都刷新了SOTA,但是预训练模型在预训练过程是不考虑下游任务的,这造成了预训练模型与下游任务天然的gap。而这种模式,下游任务通过不使用预训练模型的最后一层,通常会加入和任务相关的网络层以及对应的损失函数,这样不能充分挖掘预训练模型的能力。Prompt作为NLP新的范式,有望解决这一困境。
Prompt介绍
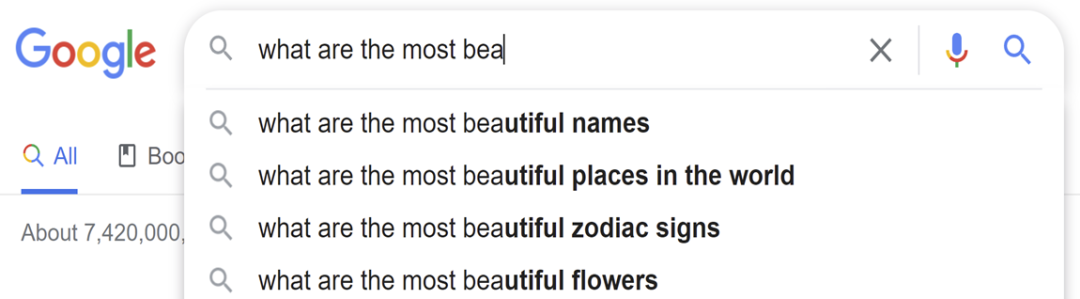
其实Prompt并不陌生,我们使用搜索引擎的时候,在输入部分内容,搜索引擎会自动提示一下内容,这就是Prompt。如下图所示:
下面我们给出Prompt在NLP领域的定义:
Prompt is a cue given to the pre-trained language model to allow it better understand human's questions
一个比较技术的定义是:

Prompt流程
Prompt的操作与之前的基于bert范式的fine-tuning不同,Prompt需要通过模板对输入数据进行重构,这样会把预测的内容也嵌入到输入数据中,这样就可以使用类似MLM的方法进行学习label了。
大致分为如下四个步骤
lStep1:Prompt Construction
lStep2:Answer Construction
lStep3:Answer Prediction
lStep4:Answer-Label Mapping
我们以一个情感分析的例子说明一下这四个步骤的具体操作:
Input: x= l love this movie
label:y=☺![]()
在监督学习中是一个二分类问题,给定一段描述,然后判断这个描述的情感类型,那么这个问题使用Prompt如何操作呢?
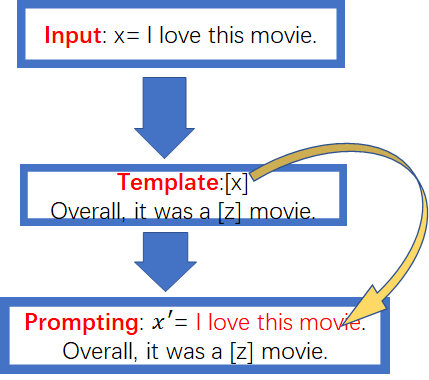
Step1:首先在Prompt Construction阶段需要制定一个模板,比如模板是这样:
Template:[x] Overall,it was a [z] movie
[x]是输入数据的占位符,[z]是预测label的占位符。如果我们使用l love this movie对[x]进行填充,那么就完成了Prompt Construction的工作了,具体形式如下:
Prompting: x′= l love this movie.Overall, it was a [z]movie.
Step2:预训练模型通常学习的是有语义的label答案,如果我们任务的label仅仅是一些无意义的标签,比如A类、B类,这个时候通常需要构造无意义标签与有语言label之间的映射关系,这就是Answer Construction。本例子中可以做如下映射关系:
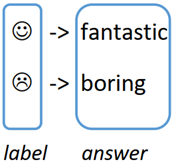
通常answer的词会有很多个,
Step3:这个步骤的主要作用就是使用预训练模型预测[z]。因此选择合适的预训练模型非常重要。假设已经选择了一个预训练模型,如果预测的结果是fantastic,那么就使用fantastic填充[z],流程如下图所示:
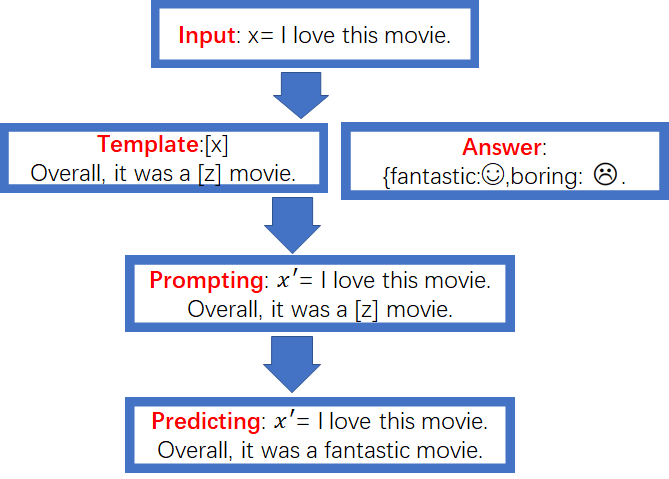
Step4:这个步骤是把step3预测得到的[z],根据step2定义的Answer Construction来进行fantastic=> ☺的映射,完整的过程如下图所示:
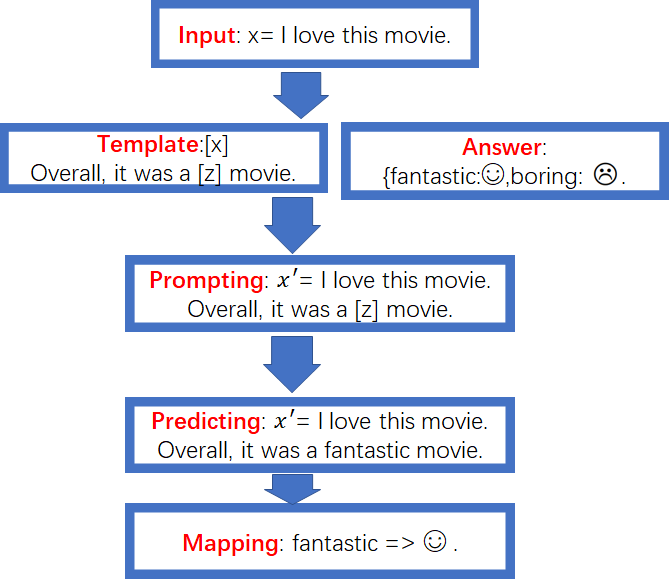
以上就是完整的Prompt操作流程,下面总结一下涉及到的数学符合
| Terminology |
Notation |
Example |
| Input |
x |
I love this movie |
| Output (label) |
y |
☺ |
| Template |
- |
[x] Overall, it was a [z] movie |
| Prompt |
x’ |
I love this movie. Overall, it was a [z] movie |
| Answer |
z |
fantastic, boring |
思考:
上述情感分析的例子在传统监督学习与Prompt有什么区别呢?
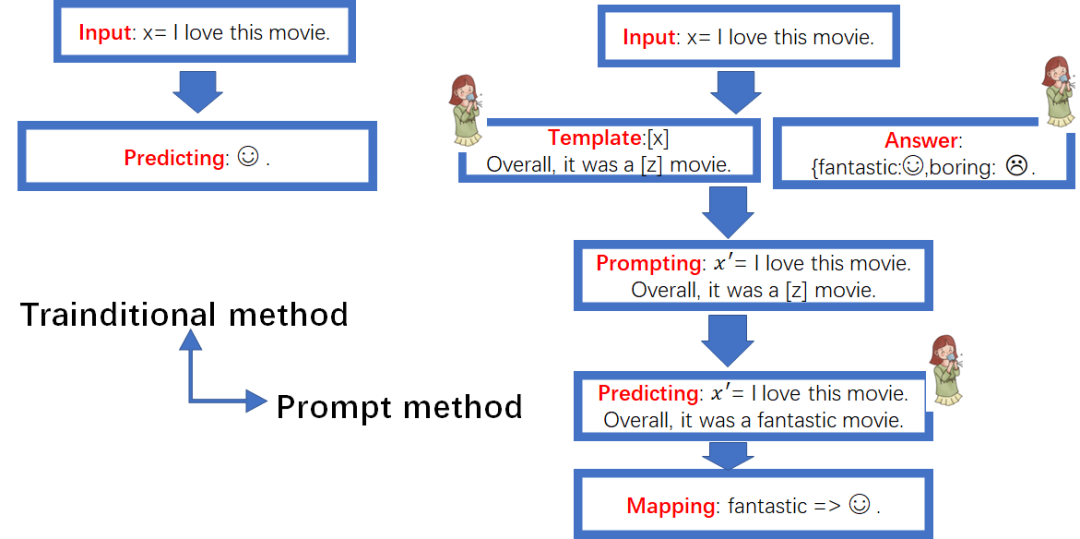
从上图可以看出,在这个任务上,其实传统的监督学习方法操作流程更简单,然而Prompt方法更可以充分挖掘预训练语言模型的知识能力,GPT3就是一个很好的例子。
Prompt设计要点:
lPrompt Template Engineering
lAnswer Engineering
lPre-trained Model Choice
lExpanding the Paradigm
lPrompt-based Training Strategies
从上图传统方法与Prompt方法对比图来看,Prompt方法在Template设计、Answer构建以及预训练模型选择都需要人工参与,这也是Prompt设计的关键要点。
Prompt Template Engineering
Answer Engineering
Pre-trained Model Choice
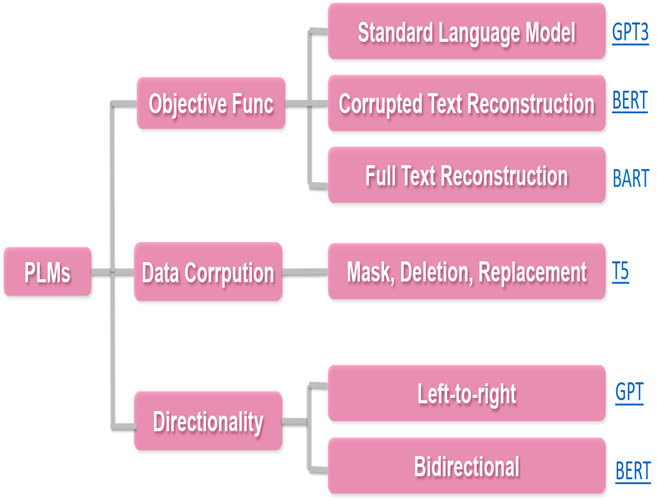
Expanding the Paradigm
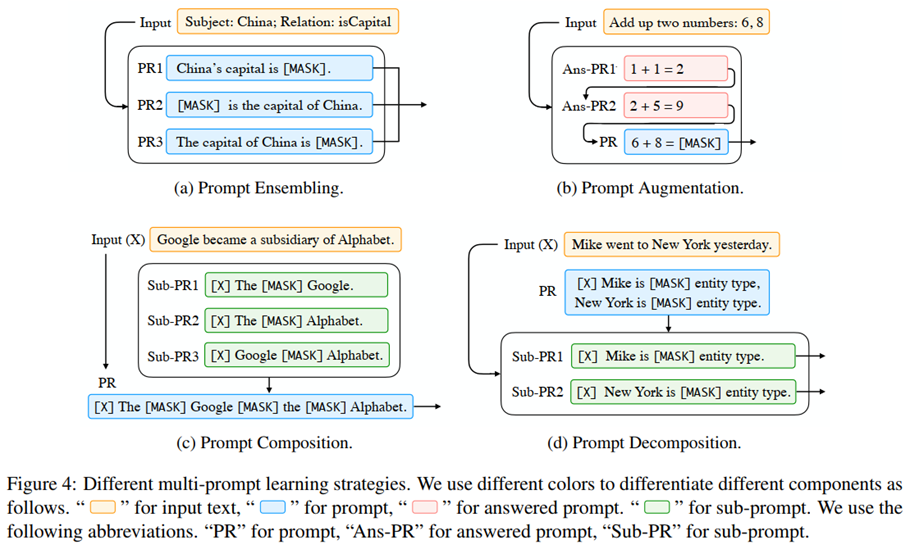
Prompt-based Training Strategies
在基于 prompt的下游任务学习中,通常存在两种类型的参数,即来自预训练模型和prompt的参数。哪类参数应该更新是一项重要的设计决策,可以在不同场景中产生不同程度的适用性。
研究者基于底层语言模型的参数是否需要调整、是否有额外的prompt参数和这些额外的prompt参数是否需要调整这三个方面总结以下5 种调整策略,如下表 6 所示,它们分别为:
GPT3的一些思考:

从GPT3给出的一些答案来看,预训练语言模型是有一些知识的,
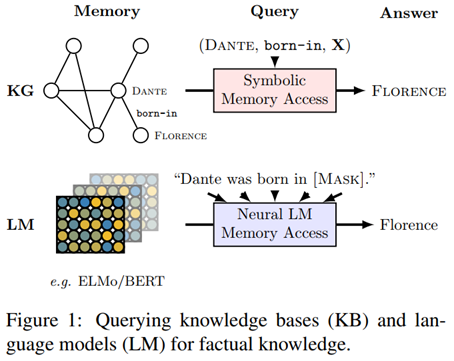
Facebook 2019(LAMA:) 论文《langauge models as knowledge base?》通过知识图谱与语言模型的对比,证明了语言模型中包括大量的知识信息。
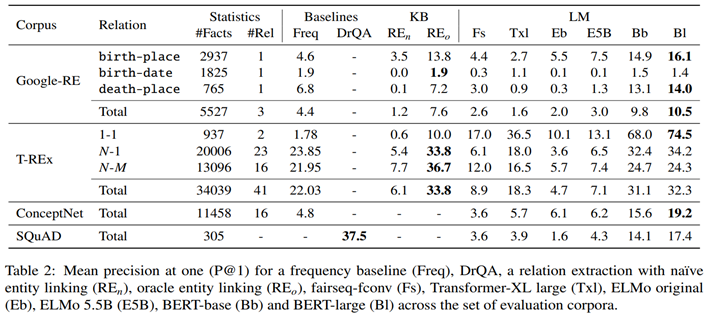
AutoPrompt
上述介绍的Prompt流程,需要大量的人力去构建Template,然后算法对Template的格式非常敏感,如下表所示,尽管他们在人看来语义是比较接近的,但是P@1指标波动很大。

《AutoPrompt: Eliciting knowledge from languagemodels with automatically generated prompts (Shin+, 2020)》提出了一种自动构建Template的方法
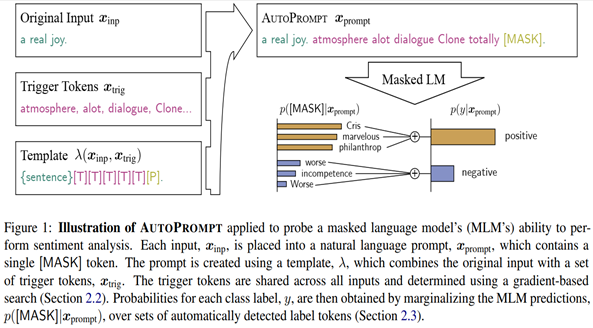
核心思想:通过梯度找出的trigger word和mask拼接在文本中,形成一个语义上不通顺、但是对模型而言却具有合理提示的样本,并且将label预测转换为masked token的预测(即完形填空问题)
基本步骤是:
1.将所有triggertoken初始化为mask token;
2.对某个trigger进行替换,找出前k个最大化输入与其梯度乘积的词:
3.对每个候选词,评估其加入prompt后的模型预测概率;
4.通过形如{sentenct}[T][T][T][T][T][P]的模版,加入上面选出的词构造prompt。
P-tuning
不管是人工构建Template还是AutoPrompt方法,token都来自字典,有一个问题:Template真的需要是“自然语言”吗?
其实我们只需要知道模版由哪些token组成,该插入到哪里,插入后能不能完成我们的下游任务,输出的候选空间是什么
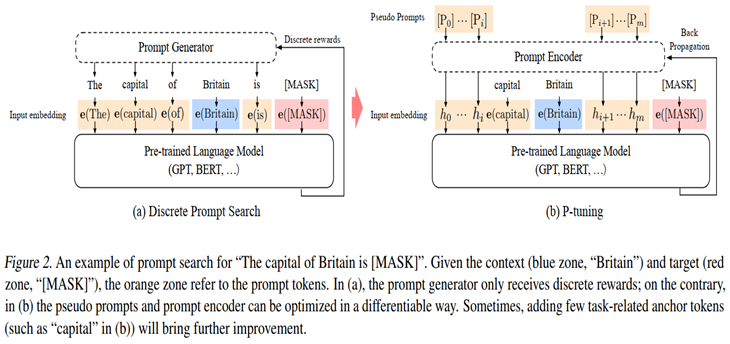
论文《GPTUnderstands, Too》提出了名为P-tuning的方法,成功地实现了模版的自动构建。
The capital of Britain is [MASK] 是很典型的一个LAMA的模板;蓝色的Britain是上下文context,红色的[MASK]是目标target;而橙色的thecapital of ... is ...是prompt tokens。
论文中黄色字体的Prompt embedding是通过BiLSTM来学习的,目的是学习这些Prompt token之间的相互关系,如下图所示:
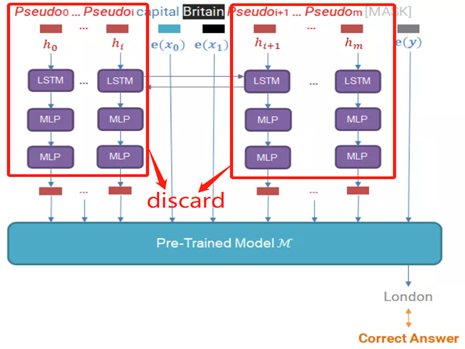
模型训练结束后,会把红色框中的MLP和LSTM删除掉,inference的时候不使用,只保留离预训练模型最近的一层向量。
P-tuning:
精髓一:自动化地寻找连续空间中的知识模板;
精髓二:训练知识模板,但不fine-tune语言模型。
P-tuning数学描述如下:


P-tuning实验效果:
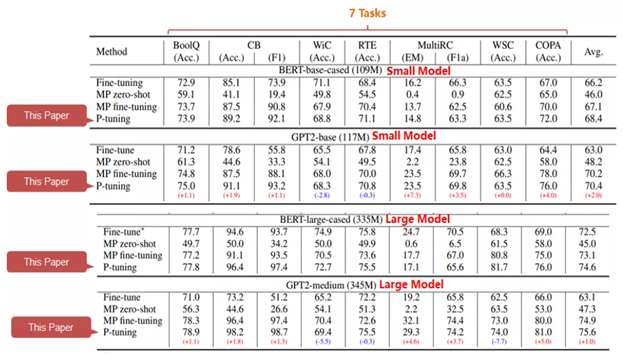
P-tuning VS fine-tuning
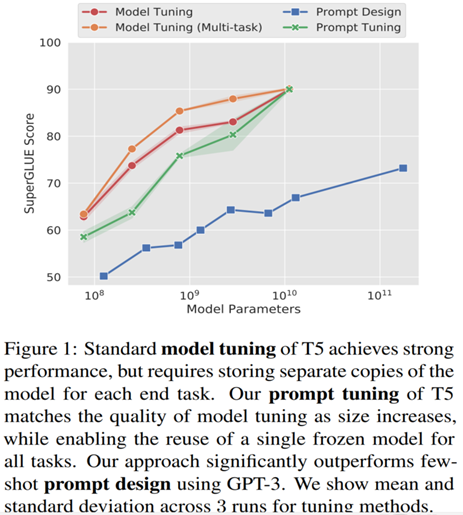
结论如下:
lfine-tuning: 随着模型规模的增大,提升逐渐饱和;
lprompt tuning: 随着模型规模的增大,性能提升与数量级基本呈现线性增长
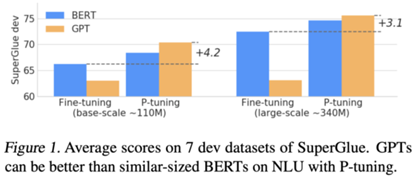
lP-tuning for GPT
– 显著提升GPT在NLU上的性能
– 同时提升BERT在NLU上表现
The Limitation of PromptTuning& P-tuning
n缺少通用性
lP-tuning匹敌fine-tuning要求
– 10B左右或更高的参数量
– 特殊的初始化技巧(label initialization)
– LMadaptation
l如何惠及1亿~10亿中小规模的模型?
n缺少任务通用性
l简单任务:GLUE& SuperGLUE
– P-tuning表现良好
l困难任务:需要知识和长文本理解
– 序列标注:命名实体识别,阅读理解……
l更现实的问题:无含义标签
– 不是所有任务的标签都有语义
– 序列标注中难以利用语义标签
P-tuning V2
论文《P-Tuning v2:Prompt Tuning Can Be Comparable to Fine-tuningUniversally Across Scales and Tasks》提出P-Tuning v2方法在Prefix-Tuning(专门为NLG)的基础上做了一些改进,使得更适配NLU场景。
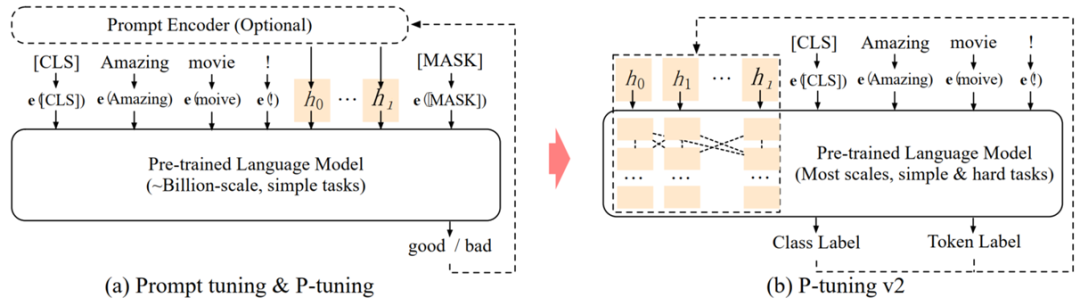
特点:
– 去除重参数化编码器
– 在Transformer的每一层都加入了Prompt 向量
– 放弃语言标签,回归[CLS]和token标签+MLP
– (可选)多任务学习
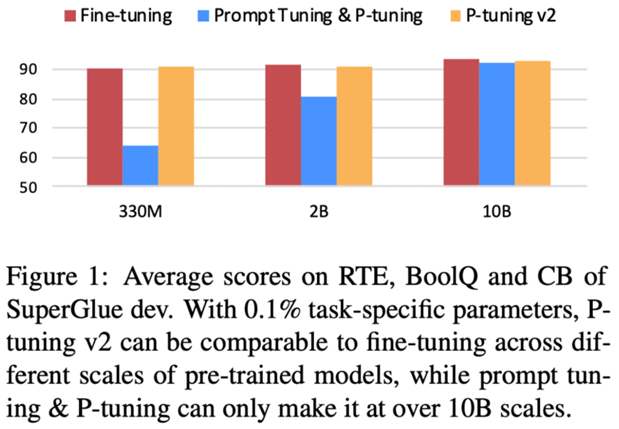
n保持预训练模型参数冻结
–P-tuning v2:仅使用0.1%的参数,在330M~10B规模均与fine-tune匹敌
–Prompt tuning & P-tuning:仅在10B规模与fine-tune匹敌
The Four Paradigms for NLP
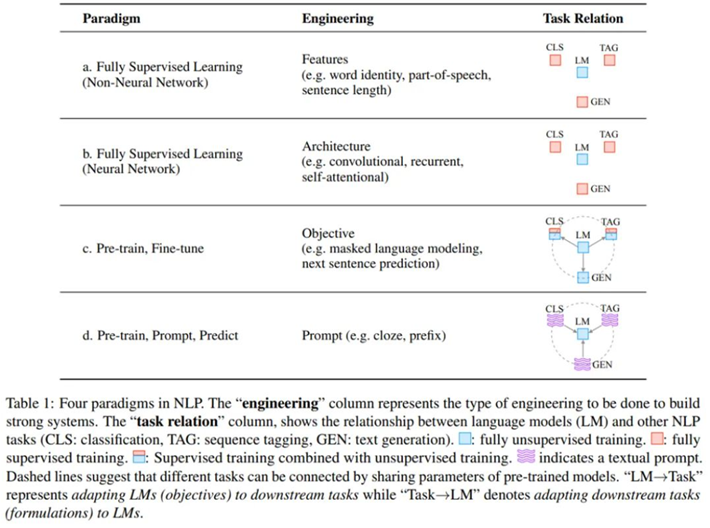
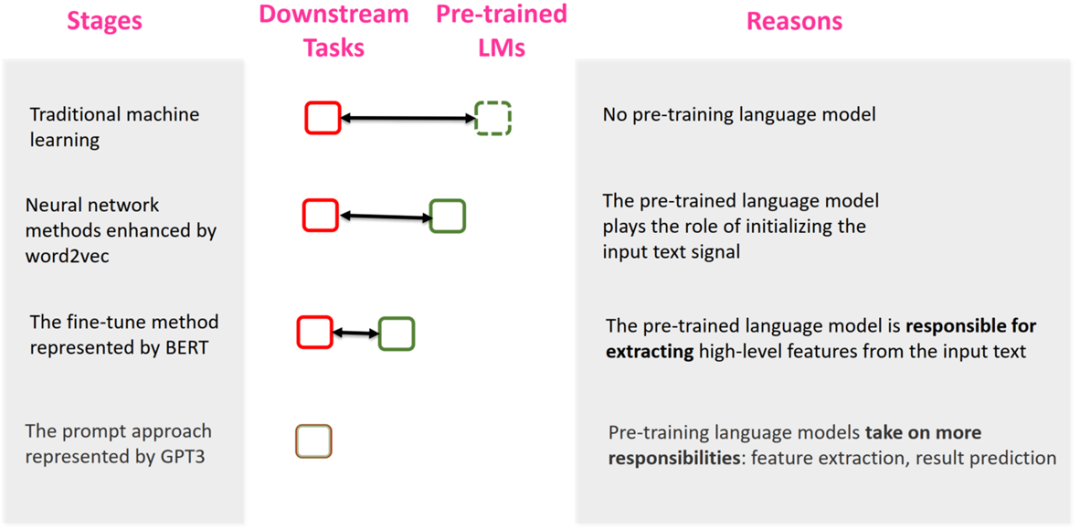
从NLP四种范式的发展规律来看,预训练语言模型与下游任务的距离越来越近了,甚至在Prompt范式预训练语言模型与下游任务几乎是一起的,充分挖掘了预训练语言模型的能力。
how can PLMs adapt to different NLP tasks?
在多任务或者基于预训练语言模型在不同的下游任务进行fine-tuning,发现都会取得不错的效果,然而随着预训练语言模型的参数量越来越大,使得fine-tuning的耗时越来越多,甚至像GPT3这么大的模型几乎无法fine-tuning。
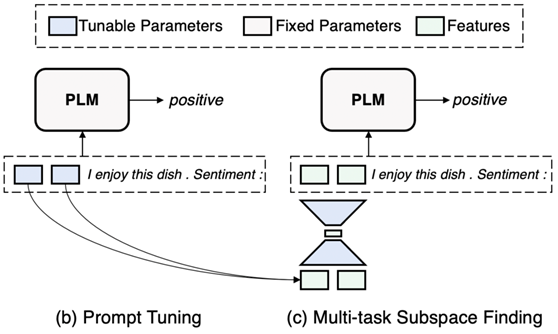
论文《Exploring Low-dimensional Intrinsic Task Subspace via Prompt Tuning 》提出一种假设,不同的子任务在预训练语言模型上进行fine-tuning都会取得不错的效果,那么这些任务是否存在共性呢?比如都是基于一个公共的向量或者矩阵,然后进行不同的映射来得到不同子任务fine-tuning之后的参数呢?
本论文就是基于这样的思想:假设这样的低纬向量存在,然后使用auto-encoder来寻找这样的低纬向量和映射矩阵,固定好映射矩阵,在每个不同的任务上只fine-tuning这个低纬向量,然后乘以映射矩阵即可,这样fine-tuning的参数量就大幅减少了。
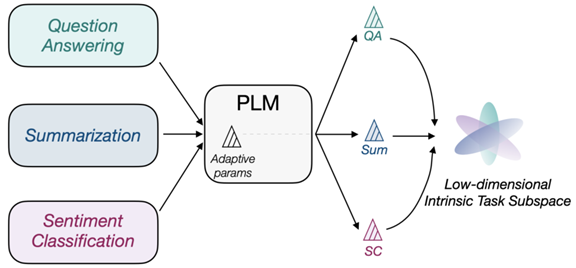
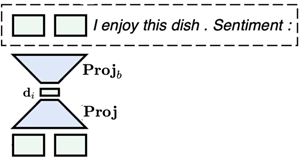
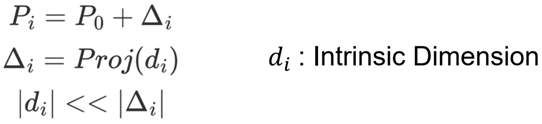
数学描述如下:
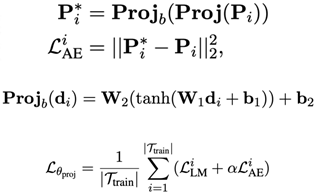
实验结果如下:
nPhase 1: Multi-task SubspaceFinding (MSF)
Find the intrinsic task subspace with multiple tasks’ prompts with an auto-encoder
nPhase 2: Intrinsic subspace Tuning(IST)
Tune parameters only in the subspace and then recover them to soft prompts with the back-projection function
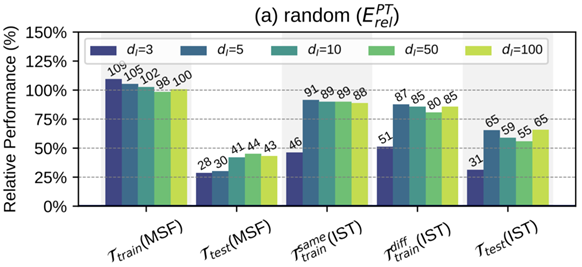
nEvaluation Metric:![]()
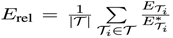
nDuring MSF, test the recovering performance for soft prompts.
nDuring IST, test the performance on seen data, unseen data, and unseen
tasks.
nExperiments:
lTraintaskset: 100 few-shot NLP tasks; Test task set: 20 few-shot NLP tasks
从实验效果来看,Di=3的时候,训练时就可以恢复1.09倍的性能。
OpenPrompt
介绍一个Prompt的开源框架OpenPrompt
nOpenPrompt:《A Unified Prompt-learningProgramming Framework》
lModularity,Flexibility,Uniformity
https:/github.com/thunlp/OpenPrompt
架构如下图所示:
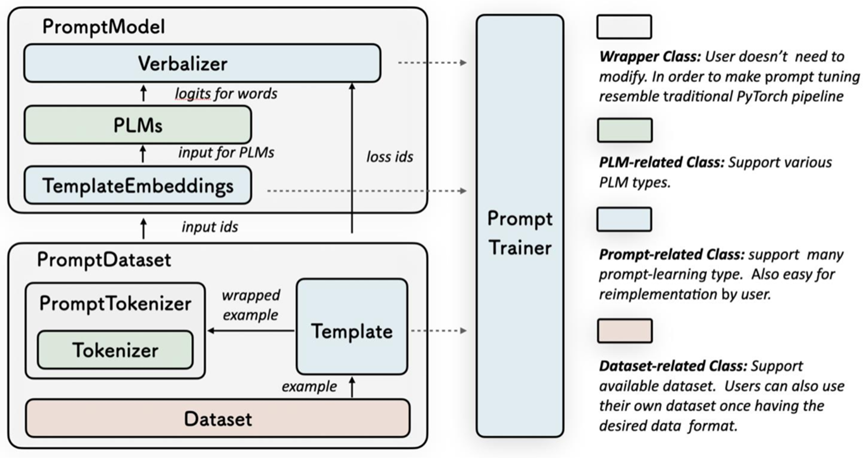
操作步骤示例如下:
nStep1:Define a task

nStep2:Define a Pre-trained Language Models(PLMs) as backbone
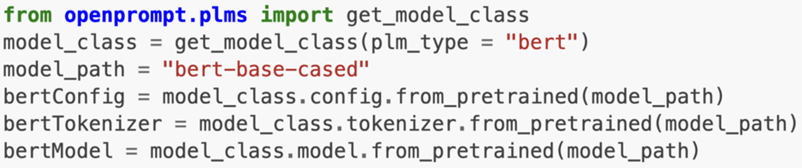
nStep3:Define a Template
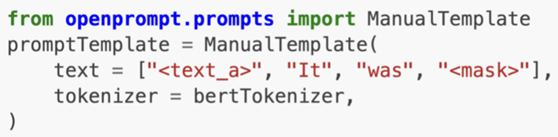
nStep4:Define a Verbalizer(optional)

nStep5:Define a PromptModel

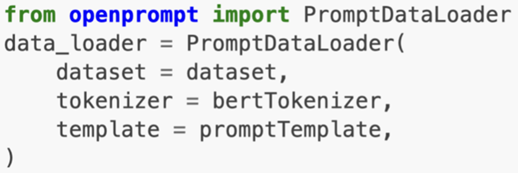
nStep6: Train and Inference
